Azure Databricks
An Apache Spark-based analytics platform optimized for Azure.
2,218 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ESY%3C/text%3E%3C/svg%3E)
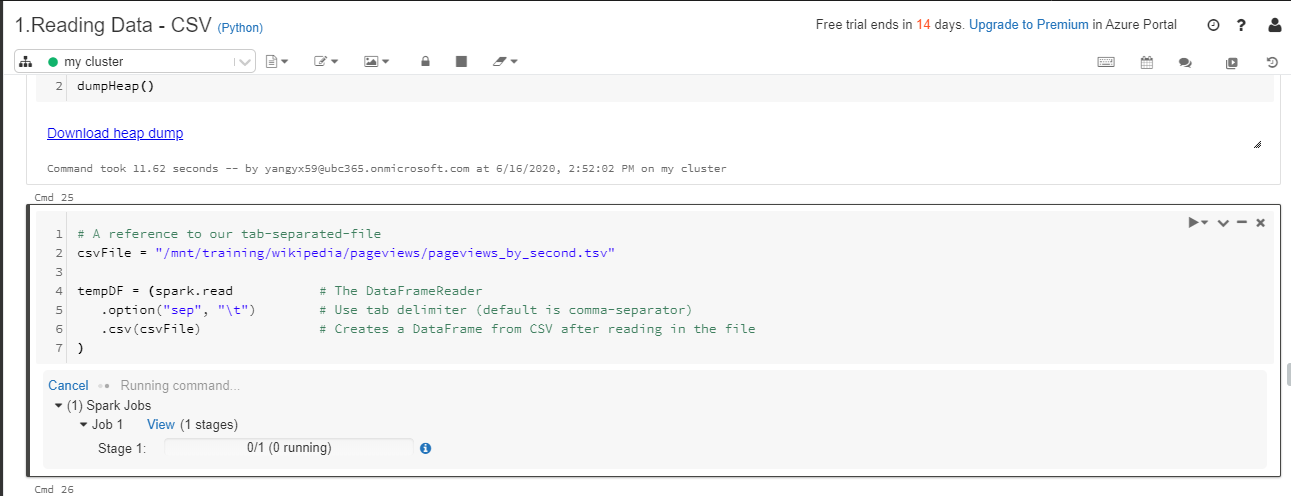
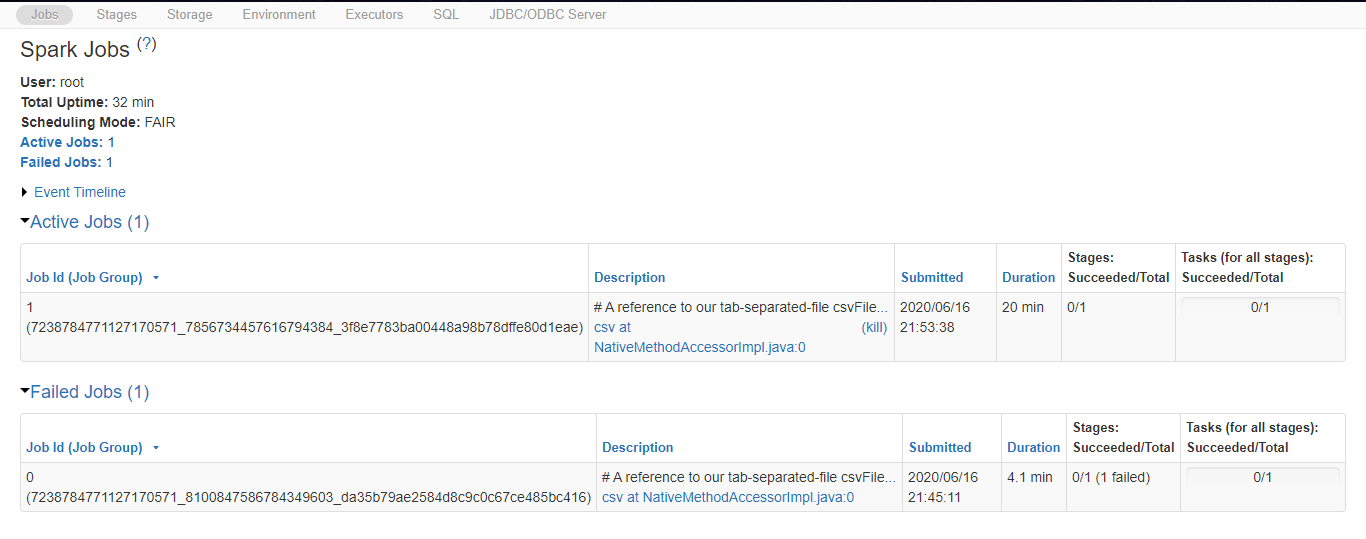
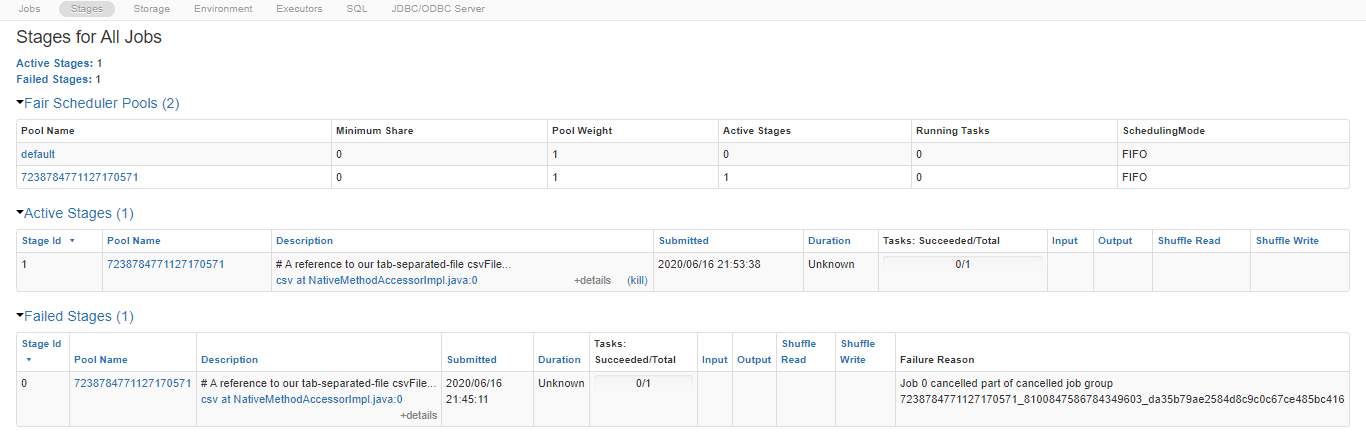
I am currently running the "1.Reading Data - CSV" notebook from the "Read and write data in Azure Databricks" module on Microsoft learn. When I tried to run the cell "# A reference to our tab-separated-file", the Spark jobs seems to be stuck while the command just continues running. The cluster attached to the notebook seems fine and running. Below are the screenshots of the notebook and the job description.
I have tried restarting the cluster and then detaching and re-attaching the cluster to the notebook, but the issue persists.

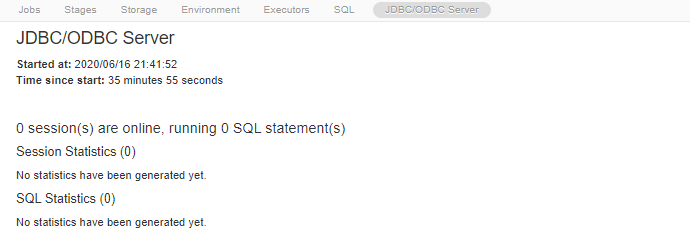
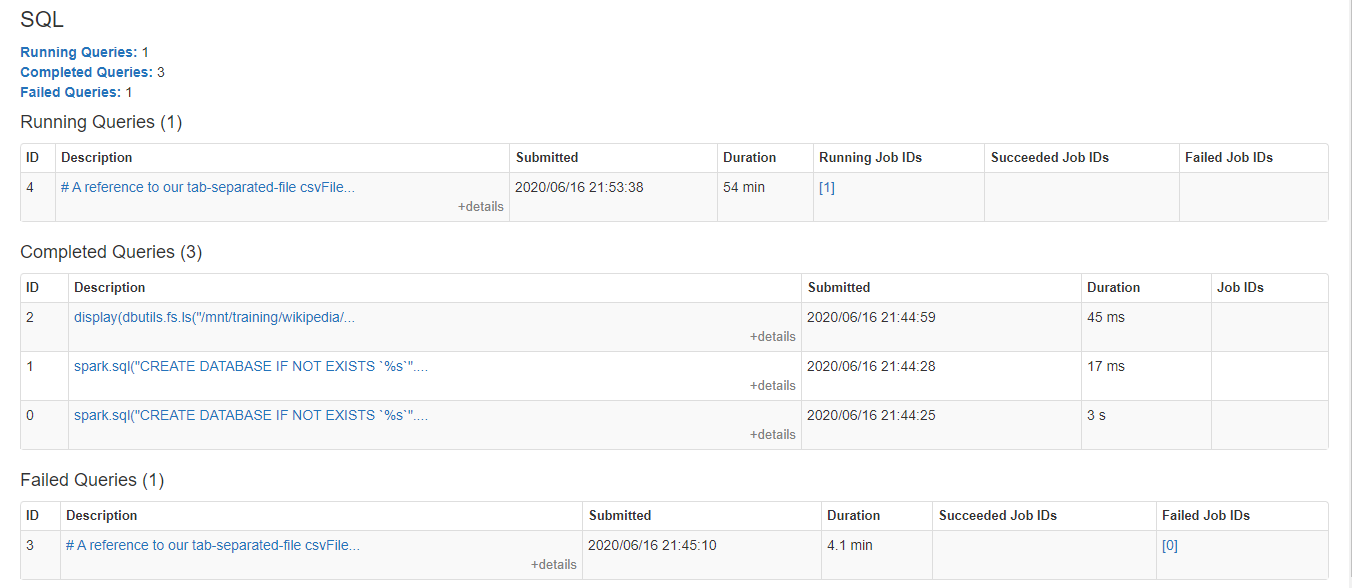

@sashayang-8285, Welcome to the Microsoft Q&A platform.
Could you please share the Databricks Runtime version which you are using?
I’m able to run the “1. Reading Data - CSV” from MS Learn, without any issue.
Used: Azure Databricks Runtime version: 6.6 (includes Apache Spark 2.4.5, Scala 2.11)
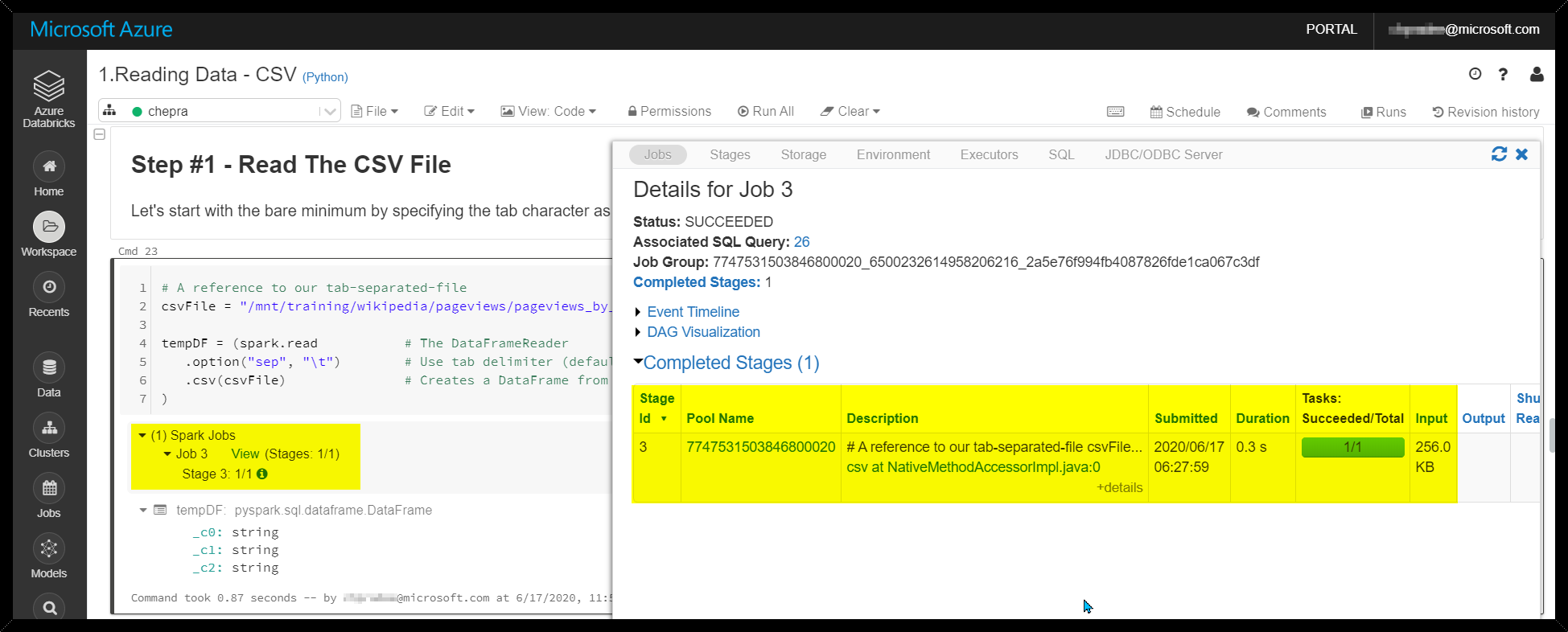
Hope this helps. Do let us know if you any further queries.
Do click on "Accept Answer" and Upvote on the post that helps you, this can be beneficial to other community members.
My runtime version is 6.5 (includes Apache Spark 2.4.5, Scala 2.11)
I just read (from other discussion threads) that my free trial license has a quota of 4 cores, which technically speaking is not enough for me to launch a cluster. But for some unknown reason the cluster I created actually ran yesterday (a glitch I guess?). Maybe this is why the jobs are not running?
@Sasha Yang , Yes, you are correct Azure Free trial subscription are not allowed to create Spark cluster.
You may checkout similar Q&A thread here: https://learn.microsoft.com/en-us/answers/questions/1544/azure-databricks.html
I have tried it on Databricks Runtime version 6.5 and able to run the query without any issue.
I would suggest you to create a new cluster and check if the issue persists.
Hope this helps. Do let us know if you any further queries.
-----------------------------------------
Do click on "Accept Answer" and Upvote on the post that helps you, this can be beneficial to other community members.
Hello @Sasha Yang ,
Just checking in to see if the above answer helped. If this answers your query, do click “Accept Answer” and Up-Vote for the same. And, if you have any further query do let us know.
Hello @Sasha Yang ,
Just checking in to see if the above answer helped. If this answers your query, do click “Accept Answer” and Up-Vote for the same. And, if you have any further query do let us know.