Understand path lengths in Azure NetApp Files
File and path length refers to the number of Unicode characters in a file path, including directories. This limit is a factor in the individual character lengths, which are determined by the size of the character in bytes. For instance, NFS and SMB allow path components of 255 bytes. The file encoding format of ASCII uses 8-bit encoding, meaning file path components (such as a file or folder name) in ASCII can be up to 255 characters since ASCII characters are 1 byte in size.
The following table shows the supported component and path lengths in Azure NetApp Files volumes:
| Component | NFS | SMB |
|---|---|---|
| Path component size | 255 bytes | 255 bytes |
| Path length size | Unlimited | Default: 255 bytes Maximum in later Windows versions: 32,767 bytes |
| Maximum path size for transversal | 4,096 bytes | 255 bytes |
Note
Dual-protocol volumes use the lowest maximum value.
If an SMB share name is \\SMB-SHARE, the share name adds 11 Unicode characters to the path length because each character is 1 byte. If the path to a specific file is \\SMB-SHARE\apps\archive\file, it's 29 Unicode characters; each character, including the slashes, is 1 byte. For NFS mounts, the same concepts apply. The mount path /AzureNetAppFiles is 17 Unicode characters of 1 byte each.
Azure NetApp Files supports the same path length for SMB shares that modern Windows servers support: up to 32,767 bytes. However, depending on the version of the Windows client, some applications can't support paths longer than 260 bytes. Individual path components (the values between slashes, such as file or folder names) support up to 255 bytes. For instance, a file name using the Latin capital “A” (which takes up 1 byte per character) in a file path in Azure NetApp Files can't exceed 255 characters.
# mkdir 256charsaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
mkdir: cannot create directory ‘256charsaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa’: File name too long
# mkdir 255charsaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
# ls | grep 255
255charsaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
Discerning character sizes
The Linux utility uniutils can be used to find the byte size of Unicode characters by typing multiple instances of the character instance and viewing the bytes field.
Example 1: The Latin capital A increments by 1 byte each time it's used (using a single hex value of 41, which is in the 0-255 range of ASCII characters).
# printf %b 'AAA' | uniname
character byte UTF-32 encoded as glyph name
0 0 000041 41 A LATIN CAPITAL LETTER A
1 1 000041 41 A LATIN CAPITAL LETTER A
2 2 000041 41 A LATIN CAPITAL LETTER A
Result 1: The name AAA uses 3 bytes out of 255.
Example 2: The Japanese character 字 increments 3 bytes each instance. This can be also calculated by the 3 separate hex code values (E5, AD, 97) under the encoded as field. Each hex value represents 1 byte:
# printf %b '字字字' | uniname
character byte UTF-32 encoded as glyph name
0 0 005B57 E5 AD 97 字 CJK character Nelson 1281
1 3 005B57 E5 AD 97 字 CJK character Nelson 1281
2 6 005B57 E5 AD 97 字 CJK character Nelson 1281
Result 2: A file named 字字字 uses 9 bytes out of 255.
Example 3: The letter Ä with diaeresis uses 2 bytes per instance (C3 + 84).
# printf %b 'ÄÄÄ' | uniname
character byte UTF-32 encoded as glyph name
0 0 0000C4 C3 84 Ä LATIN CAPITAL LETTER A WITH DIAERESIS
1 2 0000C4 C3 84 Ä LATIN CAPITAL LETTER A WITH DIAERESIS
2 4 0000C4 C3 84 Ä LATIN CAPITAL LETTER A WITH DIAERESIS
Result 3: A file named ÄÄÄ uses 6 bytes out of 255.
Example 4: A special character, such as the 😃 emoji, falls into an undefined range that exceeds the 0-3 bytes used for Unicode characters. As a result, it uses a surrogate pair for its character encoding. In this case, each instance of the character uses 4 bytes.
# printf %b '😃😃😃' | uniname
character byte UTF-32 encoded as glyph name
0 0 01F603 F0 9F 98 83 😃 Character in undefined range
1 4 01F603 F0 9F 98 83 😃 Character in undefined range
2 8 01F603 F0 9F 98 83 😃 Character in undefined range
Result 4: A file named 😃😃😃 uses 12 bytes out of 255.
Most emojis fall into the 4-byte range but can go up to 7 bytes. Of the more than one thousand standard emojis, approximately 180 are in the Basic Multilingual Plane (BMP), which means they can be displayed as text or emoji in Azure NetApp Files, depending on the client’s support for the language type.
For more detailed information on the BMP and other Unicode planes, see Understand volume languages in Azure NetApp Files.
Character byte impact on path lengths
Although a path length is thought to be the number of characters in a file or folder name, it's actually the size of the supported bytes in the path. Since each character adds a byte size to a name, different character sets in different languages support different file name lengths.
Consider the following scenarios:
A file or folder repeats the Latin alphabet character “A” for its file name. (for example, AAAAAAAA)
Since “A” uses 1 byte and 255 bytes is the path component size limit, then 255 instances of “A” would be allowed in a file name.
A file or folder repeats the Japanese character 字 in its name.
Since “字” has a size of 3 bytes, the file name length limit would be 85 instances of 字 (3 byte * 85 = 255 bytes), or a total of 85 characters.
A file or folder repeats the grinning face emoji (😃) in its name.
A grinning face emoji (😃) uses 4 bytes, meaning a file name with only that emoji would allow a total of 64 characters (255 bytes/4 bytes).
- A file or folder uses a combination of different characters (ie, Name字😃).
When different characters with different byte sizes are used in a file or folder name, each character’s byte size factors in to the file or folder length. A file or folder name of Name字😃 would use 1+1+1+1+3+4 bytes (11 bytes) of the total 255-byte length.
Special emoji concepts
Special emojis, such as a flag emoji, exist under the BMP classification: the emoji renders as text or image depending on client support. When a client doesn't support the image designation, it instead uses regional text-based designations.
For instance, the United States flag use the characters "us" (which resemble the Latin characters U+S, but are actually special characters that use different encodings). Uniname shows the differences between the characters.
# printf %b 'US' | uniname
character byte UTF-32 encoded as glyph name
0 0 000055 55 U LATIN CAPITAL LETTER U
1 1 000053 53 S LATIN CAPITAL LETTER S
# printf %b '🇺🇸' | uniname
character byte UTF-32 encoded as glyph name
0 0 01F1FA F0 9F 87 BA 🇺 Character in undefined range
1 4 01F1F8 F0 9F 87 B8 🇸 Character in undefined range
Characters designated for the flag emojis translate to flag images in supported systems, but remain as text values in unsupported systems. These characters use 4 bytes per character for a total of 8 bytes when a flag emoji is used. As such, a total of 31 flag emojis are allowed in a file name (255 bytes/8 bytes).
SMB path limits
By default, Windows servers and clients support path lengths up to 260 bytes, but the actual file path lengths are shorter due to metadata added to Windows paths such as the <NUL> value and domain information.
When a path limit is exceeded in Windows, a dialog box appears:
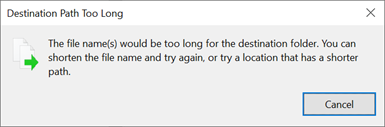
SMB path lengths can be extended when using Windows 10/Windows Server 2016 version 1607 or later by changing a registry value as covered in Maximum Path Length Limitation. When this value is changed, path lengths can extend out to up to 32,767 bytes (minus metadata values).
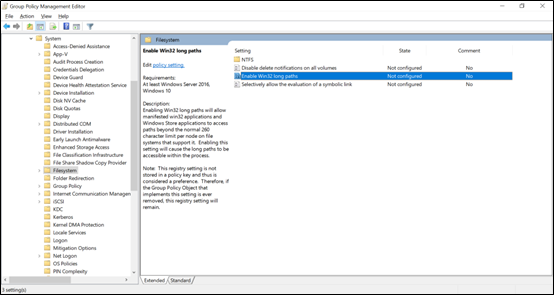
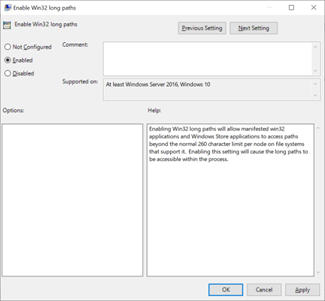
Once this feature is enabled, you must access the SMB share needs using \\?\ in the path to allow longer path lengths. This method doesn't support UNC paths, so the SMB share needs to be mapped to a drive letter.
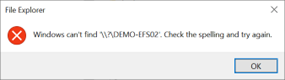
Using \\?\Z: instead allows access and supports longer file paths.

Note
The Windows CMD doesn't currently support the use of \\?\.
Workaround if the max path length cannot be increased
If the max path length can't be enabled in the Windows environment or the Windows client versions are too low, there's a workaround. You can mount the SMB share deeper into the directory structure and reduce the queried path length.
For example, rather than mapping \\NAS-SHARE\AzureNetAppFiles to Z:, map \\NAS-SHARE\AzureNetAppFiles\folder1\folder2\folder3\folder4 to Z:.
NFS path limits
NFS path limits with Azure NetApp Files volumes have the same 255-byte limit for individual path components. Each component, however, is evaluated one at a time and can process up to 4,096 bytes per request with a near limitless total path length. For instance, if each path component is 255 bytes, an NFS client can evaluate up to 15 components per request (including / characters). As such, a cd request to a path over the 4,096-byte limit yields a "File name too long" error message.
In most cases, Unicode characters are 1 byte or less, so the 4,096-byte limit corresponds to 4,096 characters. If a character is larger than 1 byte in size, then the path length is less than 4,096 characters. Characters with a size greater than 1 byte in size count more against the total character count than 1-byte characters.
The path length max can be queried using the getconf PATH_MAX /NFSmountpoint command.
Note
The limit is defined in the limits.h file on the NFS client. You shouldn't adjust these limits.
Dual-protocol volume considerations
When using Azure NetApp Files for dual-protocol access, the difference in how path lengths are handled in NFS and SMB protocols can create incompatibilities across file and folders. For instance, Windows SMB supports up to 32,767 characters in a path (provided the long path feature is enabled on the SMB client), but NFS support can exceed that amount. As such, if a path length is created in NFS that exceeds the support of SMB, clients are unable to access the data once the path length maximums have been reached. In those cases, either take care to consider the lower end limits of file path lengths across protocols when creating file and folder names (and folder path depth) or map SMB shares closer to the desired folder path to reduce the path length.
Instead of mapping the SMB share to the top level of the volume to navigate down to a path of \\share\folder1\folder2\folder3\folder4, consider mapping the SMB share to the entire path of \\share\folder1\folder2\folder3\folder4. As a result, a drive letter mapping to Z: lands in the desired folder and reduces the path length from Z:\folder1\folder2\folder3\folder4\file to Z:\file.
Special character considerations
Azure NetApp Files volumes use a language type of C.UTF-8, which covers many countries and languages including German, Cyrillic, Hebrew, and most Chinese/Japanese/Korean (CJK). Most common text characters in Unicode are 3 bytes or less. Special characters--such as emojis, musical symbols, and mathematical symbols--are often larger than 3 bytes. Some use UTF-16 surrogate pair logic.
If you use a character that Azure NetApp Files doesn't support, you might see a warning requesting a different file name.
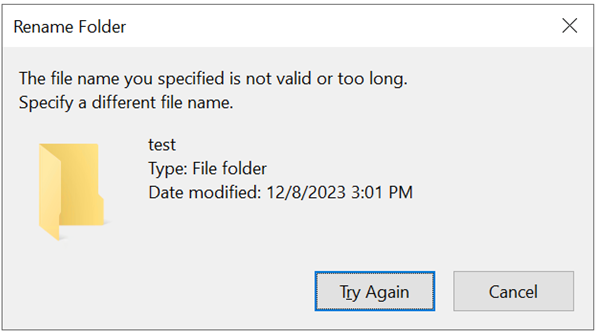
Rather than the name being too long, the error actually results from the character byte size being too large for the Azure NetApp Files volume to use over SMB. There's no workaround in Azure NetApp Files for this limitation. For more information on special character handling in Azure NetApp Files, see Protocol behavior with special character sets.
Next steps
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for