A map transform takes each incoming message and produces an output message based on your rules. You can rename fields, reorganize them into new structures, compute derived values, or remove unwanted fields. Wildcard rules let you copy all fields at once.
For an overview of data flow graphs and how transforms compose in a pipeline, see Data flow graphs overview.
Prerequisites
- A default registry endpoint named
default that points to mcr.microsoft.com is automatically created during deployment. The built-in transforms use this endpoint.
How map rules work
Each map rule has four parts:
| Property |
Required |
Description |
inputs |
Yes |
List of field paths to read from the incoming message. |
output |
Yes |
Field path where the result is written in the output message. |
expression |
No |
Formula applied to the input values. If omitted, the first input value is copied directly. |
description |
No |
Human-readable label for the rule, included in error messages. |
Inputs are assigned positional variables based on their order: the first input is $1, the second is $2, and so on. Use these variables in the expression.
Rename a field
To rename BirthDate to DateOfBirth, map one input to a different output path. No expression is needed. The value copies as-is.
In the map transform configuration, add a rule:
| Setting |
Value |
| Input |
BirthDate |
| Output |
DateOfBirth |
The CLI applies the whole graph from one config file, so add this to the corresponding place in your graph.json and apply it with az iot ops dataflowgraph apply:
{
"inputs": [
"BirthDate"
],
"output": "DateOfBirth"
}
{
inputs: [
'BirthDate'
]
output: 'DateOfBirth'
}
Important
The use of Kubernetes deployment manifests isn't supported in production environments and should only be used for debugging and testing.
- inputs:
- BirthDate
output: DateOfBirth
Restructure fields
Use dot notation in the output path to move fields into a nested structure.
Add two rules:
| Input |
Output |
Name |
Employee.Name |
BirthDate |
Employee.DateOfBirth |
The CLI applies the whole graph from one config file, so add this to the corresponding place in your graph.json and apply it with az iot ops dataflowgraph apply:
{
"inputs": [
"Name"
],
"output": "Employee.Name"
},
{
"inputs": [
"BirthDate"
],
"output": "Employee.DateOfBirth"
}
{
inputs: [ 'Name' ]
output: 'Employee.Name'
}
{
inputs: [ 'BirthDate' ]
output: 'Employee.DateOfBirth'
}
Important
The use of Kubernetes deployment manifests isn't supported in production environments and should only be used for debugging and testing.
- inputs:
- Name
output: Employee.Name
- inputs:
- BirthDate
output: Employee.DateOfBirth
Given this input:
{
"Name": "Grace Owens",
"BirthDate": "19840202",
"Position": "Analyst"
}
These two rules produce:
{
"Employee": {
"Name": "Grace Owens",
"DateOfBirth": "19840202"
}
}
Only fields listed in a rule's output appear in the result. The Position field isn't included because no rule maps it.
When you list multiple inputs, their positional variables let you merge them in an expression.
Add a rule:
| Setting |
Value |
| Inputs |
Position, Office |
| Output |
Employment.Position |
| Expression |
$1 + ", " + $2 |
The CLI applies the whole graph from one config file, so add this to the corresponding place in your graph.json and apply it with az iot ops dataflowgraph apply:
{
"inputs": [
"Position",
"Office"
],
"output": "Employment.Position",
"expression": "$1 + \", \" + $2"
}
{
inputs: [ 'Position', 'Office' ]
output: 'Employment.Position'
expression: '$1 + ", " + $2'
}
Important
The use of Kubernetes deployment manifests isn't supported in production environments and should only be used for debugging and testing.
- inputs:
- Position # $1
- Office # $2
output: Employment.Position
expression: "$1 + \", \" + $2"
Given Position: "Analyst" and Office: "Kent, WA", the output is "Analyst, Kent, WA".
Use the expression field to apply built-in functions or arithmetic.
Add a compute rule. For example, to convert Celsius to Fahrenheit:
| Setting |
Value |
| Input |
temperature |
| Output |
temperature_f |
| Expression |
cToF($1) |
To scale a sensor reading to a 0-100 range, use the expression scale($1, 0, 4095, 0, 100).
The CLI applies the whole graph from one config file, so add this to the corresponding place in your graph.json and apply it with az iot ops dataflowgraph apply:
{
"inputs": [
"temperature"
],
"output": "temperature_f",
"expression": "cToF($1)"
}
To scale a sensor reading:
{
"inputs": [
"raw_pressure"
],
"output": "pressure_pct",
"expression": "scale($1, 0, 4095, 0, 100)"
}
{
inputs: [ 'temperature' ]
output: 'temperature_f'
expression: 'cToF($1)'
}
To scale a sensor reading:
{
inputs: [ 'raw_pressure' ]
output: 'pressure_pct'
expression: 'scale($1, 0, 4095, 0, 100)'
}
Important
The use of Kubernetes deployment manifests isn't supported in production environments and should only be used for debugging and testing.
- inputs:
- temperature # $1
output: temperature_f
expression: "cToF($1)"
To scale a sensor reading:
- inputs:
- raw_pressure # $1
output: pressure_pct
expression: "scale($1, 0, 4095, 0, 100)"
For the complete list of operators, functions, and advanced features, see Expressions reference.
Copy all fields with wildcards
When the output should closely match the input with only a few changes, use a wildcard rule to copy every field at once. Then add rules to override, add, or remove specific fields.
Add a passthrough rule that copies all fields. Set the input to * and the output to *.
The CLI applies the whole graph from one config file, so add this to the corresponding place in your graph.json and apply it with az iot ops dataflowgraph apply:
{
"inputs": [
"*"
],
"output": "*"
}
{
inputs: [ '*' ]
output: '*'
}
Important
The use of Kubernetes deployment manifests isn't supported in production environments and should only be used for debugging and testing.
- inputs:
- '*'
output: '*'
Wildcard rule requirements
- A wildcard rule must be the first rule in your map configuration.
- Only one wildcard rule is allowed per map transform.
- The asterisk matches one or more path segments and must represent a complete segment. Patterns like
partial* aren't supported.
Prefix wildcards
You can scope the wildcard to a specific prefix. To flatten all fields from ColorProperties to the root level:
Add a rule with input ColorProperties.* and output *.
The CLI applies the whole graph from one config file, so add this to the corresponding place in your graph.json and apply it with az iot ops dataflowgraph apply:
{
"inputs": [
"ColorProperties.*"
],
"output": "*"
}
{
inputs: [ 'ColorProperties.*' ]
output: '*'
}
Important
The use of Kubernetes deployment manifests isn't supported in production environments and should only be used for debugging and testing.
- inputs:
- 'ColorProperties.*'
output: '*'
Given:
{
"ColorProperties": {
"Hue": "blue",
"Saturation": "90%",
"Brightness": "50%"
}
}
The output is:
{
"Hue": "blue",
"Saturation": "90%",
"Brightness": "50%"
}
Remove fields from the output
Set the output to an empty string to exclude specific fields. This approach is typically used after a wildcard rule: copy everything, then remove what you don't need.
- Add a passthrough rule to copy all fields.
- Add a remove rule and select the fields to exclude (for example,
password and internal_id).
The CLI applies the whole graph from one config file, so add this to the corresponding place in your graph.json and apply it with az iot ops dataflowgraph apply:
{
"inputs": [
"*"
],
"output": "*"
},
{
"inputs": [
"password",
"internal_id"
],
"output": ""
}
{
inputs: [ '*' ]
output: '*'
}
{
inputs: [ 'password', 'internal_id' ]
output: ''
}
Important
The use of Kubernetes deployment manifests isn't supported in production environments and should only be used for debugging and testing.
- inputs:
- '*'
output: '*'
- inputs:
- password
- internal_id
output: ""
No expression is allowed on a removal rule.
Override wildcards for specific fields
When a wildcard rule and a specific rule both match the same field, the more specific rule takes precedence.
- Add a passthrough rule to copy all fields.
- Add a compute rule for
temperature with the expression cToF($1).
The map transform applies the specific rule to temperature and copies all other fields as-is.
The CLI applies the whole graph from one config file, so add this to the corresponding place in your graph.json and apply it with az iot ops dataflowgraph apply:
{
"inputs": [
"*"
],
"output": "*"
},
{
"inputs": [
"temperature"
],
"output": "temperature",
"expression": "cToF($1)"
}
{
inputs: [ '*' ]
output: '*'
}
{
inputs: [ 'temperature' ]
output: 'temperature'
expression: 'cToF($1)'
}
Important
The use of Kubernetes deployment manifests isn't supported in production environments and should only be used for debugging and testing.
- inputs:
- '*'
output: '*'
- inputs:
- temperature # $1
output: temperature
expression: "cToF($1)"
You can read from and write to message metadata like MQTT topics and user properties. See Metadata fields in the expressions reference.
Add a rule with input region and output $metadata.user_property.region to write a field value to an MQTT user property.
The CLI applies the whole graph from one config file, so add this to the corresponding place in your graph.json and apply it with az iot ops dataflowgraph apply:
{
"inputs": [
"*"
],
"output": "*"
},
{
"inputs": [
"region"
],
"output": "$metadata.user_property.region"
}
{
inputs: [ '*' ]
output: '*'
}
{
inputs: [ 'region' ]
output: '$metadata.user_property.region'
}
Important
The use of Kubernetes deployment manifests isn't supported in production environments and should only be used for debugging and testing.
- inputs:
- '*'
output: '*'
- inputs:
- region
output: $metadata.user_property.region
For a complete example of dynamic topic routing, see Route messages to different topics.
Use last known value and defaults
When sensor data arrives intermittently, you can fill in missing fields with the last known value or a static default. See Last known value and Default values in the expressions reference.
Add a rule for the temperature field and enable Last known value. Set a default value of 0 as a fallback.
The CLI applies the whole graph from one config file, so add this to the corresponding place in your graph.json and apply it with az iot ops dataflowgraph apply:
{
"inputs": [
"temperature ? $last ?? 0"
],
"output": "temperature"
}
{
inputs: [ 'temperature ? $last ?? 0' ]
output: 'temperature'
}
Important
The use of Kubernetes deployment manifests isn't supported in production environments and should only be used for debugging and testing.
- inputs:
- temperature ? $last ?? 0 # $1
output: temperature
This rule uses the current value when present, falls back to the last known value, and uses 0 if neither is available.
Enrich with external data
You can augment messages with data from an external state store by configuring datasets. For example, look up a device's metadata by its ID and include it in the output. For details, see Enrich with external data.
Data flow graph exclusive features
Data flow graphs support several features that aren't available in data flow builtInTransformation mappings.
Default values for missing fields
Use the ?? <default> syntax on an input to provide a static fallback when a field is missing. This is simpler than writing an if expression to check for empty values.
In the map transform configuration, set the input to include the ?? syntax followed by the default value. For example, enter temperature ?? 0 as the input field to use 0 when the temperature field is missing.
The CLI applies the whole graph from one config file, so add this to the corresponding place in your graph.json and apply it with az iot ops dataflowgraph apply:
{
"inputs": [
"temperature ?? 0"
],
"output": "temperature"
}
{
inputs: [ 'temperature ?? 0' ]
output: 'temperature'
}
Important
The use of Kubernetes deployment manifests isn't supported in production environments and should only be used for debugging and testing.
- inputs:
- temperature ?? 0
output: temperature
For details on supported default types and combining defaults with last known values, see Default values in the expressions reference.
Regex functions
Data flow graphs support regular expression matching and replacement:
str::regex_matches(string, pattern): Returns true if the string matches the regex pattern.str::regex_replace(string, pattern, replacement): Replaces all regex matches with the replacement string.
These functions are useful in filter expressions or for cleaning and transforming string data. For the full list of string functions, see String functions in the expressions reference.
Full configuration example
Here's a complete map configuration that copies all fields, removes sensitive data, restructures a field, and computes a derived value:
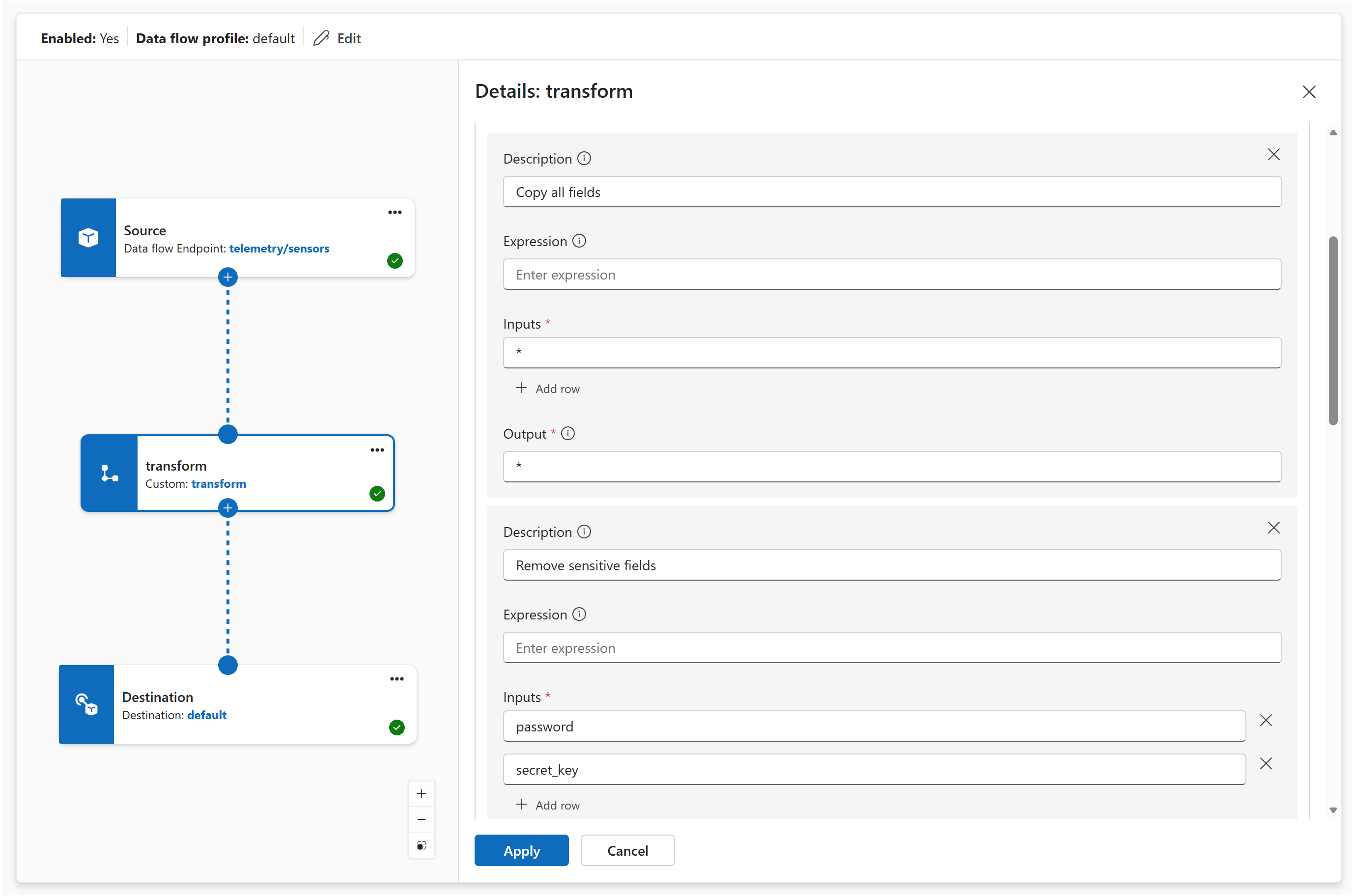
In the Operations experience, create a data flow graph and add a map transform. In the map configuration panel, add rules to:
- Copy all fields with a wildcard passthrough.
- Remove sensitive fields by setting the output to empty for
password and secret_key.
- Restructure the
BirthDate field to Employee.DateOfBirth.
- Compute a Fahrenheit conversion using the formula
cToF($1) on the temperature field.
- Merge the
Position and Office fields with the formula $1 + ", " + $2.
The Azure CLI applies a data flow graph from a single JSON config file. Create a graph.json file with the graph properties. In the graph.json file, each transform's rules are stored in the value field as an escaped JSON string. For the readable form of each transform's rules, see the how-to for that transform type.
{
"mode": "Enabled",
"nodes": [
{
"nodeType": "Source",
"name": "sensors",
"sourceSettings": {
"endpointRef": "default",
"dataSources": [
"telemetry/sensors"
]
}
},
{
"nodeType": "Graph",
"name": "transform",
"graphSettings": {
"registryEndpointRef": "default",
"artifact": "azureiotoperations/graph-dataflow-map:1.0.0",
"configuration": [
{
"key": "rules",
"value": "{\"map\":[{\"inputs\":[\"*\"],\"output\":\"*\",\"description\":\"Copy all fields\"},{\"inputs\":[\"password\",\"secret_key\"],\"output\":\"\",\"description\":\"Remove sensitive fields\"},{\"inputs\":[\"BirthDate\"],\"output\":\"Employee.DateOfBirth\",\"description\":\"Restructure birth date\"},{\"inputs\":[\"temperature\"],\"output\":\"temperature_f\",\"expression\":\"cToF($1)\",\"description\":\"Convert Celsius to Fahrenheit\"},{\"inputs\":[\"Position\",\"Office\"],\"output\":\"Employment.Position\",\"expression\":\"$1 + \\\", \\\" + $2\",\"description\":\"Merge position and office\"}]}"
}
]
}
},
{
"nodeType": "Destination",
"name": "output",
"destinationSettings": {
"endpointRef": "default",
"dataDestination": "telemetry/processed"
}
}
],
"nodeConnections": [
{
"from": {
"name": "sensors"
},
"to": {
"name": "transform"
}
},
{
"from": {
"name": "transform"
},
"to": {
"name": "output"
}
}
]
}
Tip
To generate the escaped string, save the rules to a file like rules.json, then run jq -c . rules.json and paste the single-line output into the value field.
Apply the config file. The extendedLocation is added automatically from the instance and resource group, so don't include it in the file.
az iot ops dataflowgraph apply \
--name temperature-map-example \
--instance <INSTANCE_NAME> \
--resource-group <RESOURCE_GROUP> \
--config-file graph.json
resource dataflowGraph 'Microsoft.IoTOperations/instances/dataflowProfiles/dataflowGraphs@2026-03-01' = {
name: 'temperature-map-example'
parent: dataflowProfile
properties: {
mode: 'Enabled'
nodes: [
{
nodeType: 'Source'
name: 'sensors'
sourceSettings: {
endpointRef: 'default'
dataSources: [
'telemetry/sensors'
]
}
}
{
nodeType: 'Graph'
name: 'transform'
graphSettings: {
registryEndpointRef: 'default'
artifact: 'azureiotoperations/graph-dataflow-map:1.0.0'
configuration: [
{
key: 'rules'
value: '{"map":[{"inputs":["*"],"output":"*","description":"Copy all fields"},{"inputs":["password","secret_key"],"output":"","description":"Remove sensitive fields"},{"inputs":["BirthDate"],"output":"Employee.DateOfBirth","description":"Restructure birth date"},{"inputs":["temperature"],"output":"temperature_f","expression":"cToF($1)","description":"Convert Celsius to Fahrenheit"},{"inputs":["Position","Office"],"output":"Employment.Position","expression":"$1 + \\", \\" + $2","description":"Merge position and office"}]}'
}
]
}
}
{
nodeType: 'Destination'
name: 'output'
destinationSettings: {
endpointRef: 'default'
dataDestination: 'telemetry/processed'
}
}
]
nodeConnections: [
{
from: { name: 'sensors' }
to: { name: 'transform' }
}
{
from: { name: 'transform' }
to: { name: 'output' }
}
]
}
}
Important
The use of Kubernetes deployment manifests isn't supported in production environments and should only be used for debugging and testing.
The rules configuration is a JSON string placed as the value for the rules key in a DataflowGraph transform node's configuration section:
{
"map": [
{
"inputs": ["*"],
"output": "*",
"description": "Copy all fields"
},
{
"inputs": ["password", "secret_key"],
"output": "",
"description": "Remove sensitive fields"
},
{
"inputs": ["BirthDate"],
"output": "Employee.DateOfBirth",
"description": "Restructure birth date"
},
{
"inputs": ["temperature"],
"output": "temperature_f",
"expression": "cToF($1)",
"description": "Convert Celsius to Fahrenheit"
},
{
"inputs": ["Position", "Office"],
"output": "Employment.Position",
"expression": "$1 + \", \" + $2",
"description": "Merge position and office"
}
]
}
For the full DataflowGraph resource structure, see Data flow graphs overview.
Next steps