Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
In Microsoft OneLake, you can seamlessly work with tables in both Delta Lake and Apache Iceberg formats.
This flexibility is enabled through metadata virtualization, a feature that allows Iceberg tables to be interpreted as Delta Lake tables, and vice versa. You can directly write Iceberg tables or create shortcuts to them, making these tables accessible across various Fabric workloads. Similarly, Fabric tables written in the Delta Lake format can be read using Iceberg readers.
When you write or create a shortcut to an Iceberg table folder, OneLake automatically generates virtual Delta Lake metadata (Delta log) for the table, enabling its use with Fabric workloads. Conversely, Delta Lake tables now include virtual Iceberg metadata, allowing compatibility with Iceberg readers.
Important
This feature is in preview.
While this article includes guidance for using Iceberg tables with Snowflake, this feature is intended to work with any Iceberg tables with Parquet-formatted data files in storage.
Virtualize Delta Lake tables as Iceberg
To set up the automatic conversion and virtualization of tables from Delta Lake format to Iceberg format, follow these steps.
Enable automatic table virtualization of Delta Lake tables to the Iceberg format by turning on the delegated OneLake setting named Enable Delta Lake to Apache Iceberg table format virtualization in your workspace settings.
Note
This setting controls a feature that is currently in preview. This setting will be removed in a future update when the feature is enabled for all users and is no longer in preview.
Make sure your Delta Lake table, or a shortcut to it, is located in the
Tablessection of your data item. The data item may be a lakehouse or another Fabric data item.Tip
If your lakehouse is schema-enabled, then your table directory will be located directly within a schema such as
dbo. If your lakehouse is not schema-enabled, then your table directory will be directly within theTablesdirectory.Confirm that your Delta Lake table has converted successfully to the virtual Iceberg format. You can do this by examining the directory behind the table.
To view the directory if your table is in a lakehouse, you can right-click the table in the Fabric UI and select View files.
If your table is in another data item type, such as a warehouse, a database, or a mirrored database, you will need to use a client like Azure Storage Explorer or OneLake File Explorer, rather than the Fabric UI, to view the files behind the table.
You should see a directory named
metadatainside the table folder, and it should contain multiple files, including the conversion log file. Open the conversion log file to see more info about the Delta Lake to Iceberg conversion, including the timestamp of the most recent conversion and any error details.If the conversion log file shows that the table was successfully converted, read the Iceberg table using your service, app, or library of choice.
Depending on what Iceberg reader you use, you will need to know either the the path to the table directory or to the most recent
.metadata.jsonfile shown in themetadatadirectory.You can see the HTTP path to the latest metadata file of your table by opening the Properties view for the
*.metadata.jsonfile with the highest version number. Take note of this path.The path to your data item's
Tablesfolder may look like this:https://onelake.dfs.fabric.microsoft.com/83896315-c5ba-4777-8d1c-e4ab3a7016bc/a95f62fa-2826-49f8-b561-a163ba537828/Tables/Within that folder, the relative path to the latest metadata file may look like
dbo/MyTable/metadata/321.metadata.json.To read your virtual Iceberg table using Snowflake, follow the steps in this guide.
Create a table shortcut to an Iceberg table
If you already have an Iceberg table in a storage location supported by OneLake shortcuts, follow these steps to create a shortcut and have your Iceberg table appear with the Delta Lake format.
Locate your Iceberg table. Find where your Iceberg table is stored, which could be in Azure Data Lake Storage, OneLake, Amazon S3, Google Cloud Storage, or an S3 compatible storage service.
Note
If you're using Snowflake and aren't sure where your Iceberg table is stored, you can run the following statement to see the storage location of your Iceberg table.
SELECT SYSTEM$GET_ICEBERG_TABLE_INFORMATION('<table_name>');Running this statement returns a path to the metadata file for the Iceberg table. This path tells you which storage account contains the Iceberg table. For example, here's the relevant info to find the path of an Iceberg table stored in Azure Data Lake Storage:
{"metadataLocation":"azure://<storage_account_path>/<path_within_storage>/<table_name>/metadata/00001-389700a2-977f-47a2-9f5f-7fd80a0d41b2.metadata.json","status":"success"}Your Iceberg table folder needs to contain a
metadatafolder, which itself contains at least one file ending in.metadata.json.In your Fabric lakehouse, create a new table shortcut in the Tables area of a lakehouse.
Tip
If you see schemas such as dbo under the Tables folder of your lakehouse, then the lakehouse is schema-enabled. In this case, right-click on the schema and create a table shortcut under the schema.
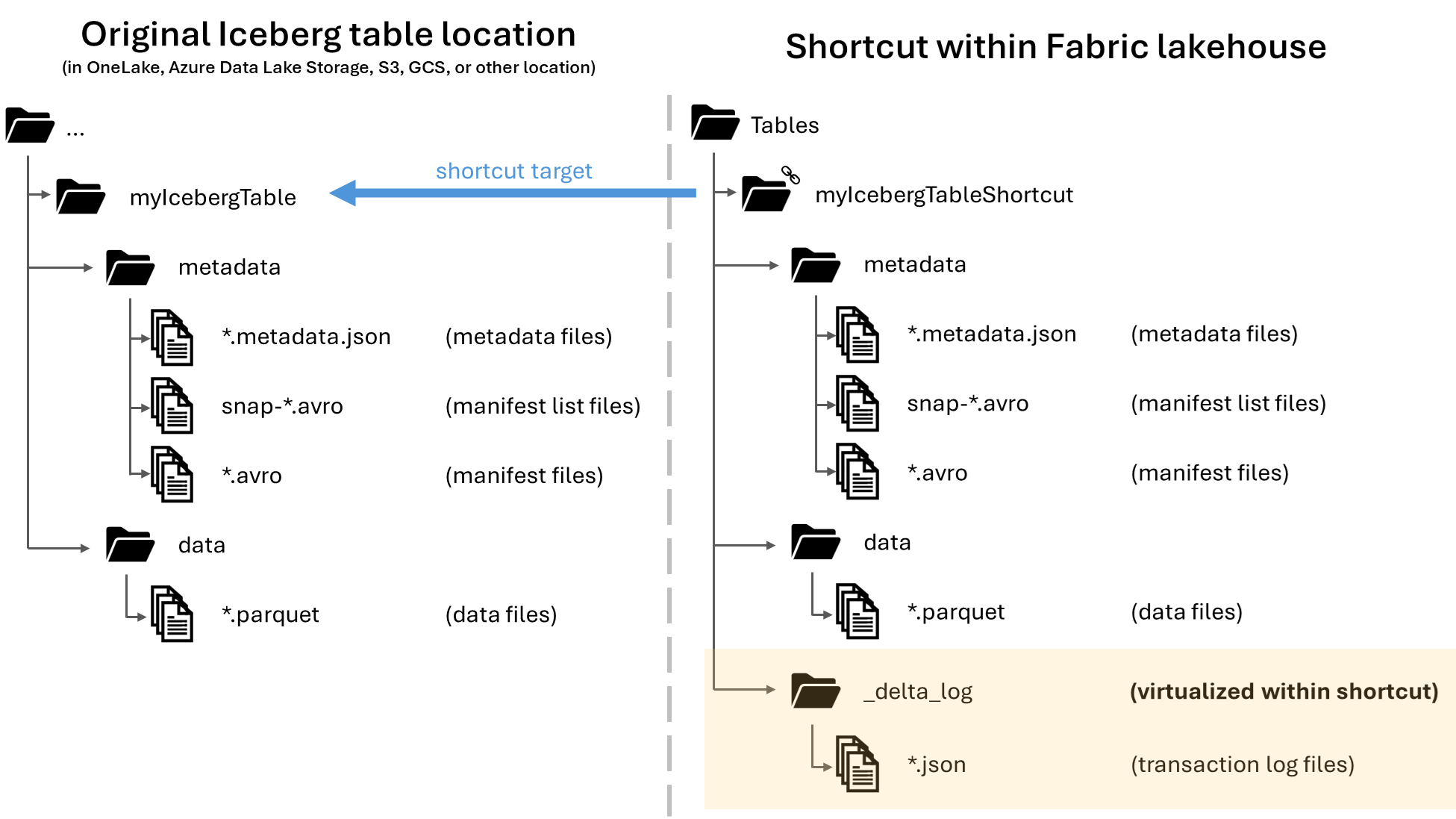
For the target path of your shortcut, select the Iceberg table folder. The Iceberg table folder contains the
metadataanddatafolders.Once your shortcut is created, you should automatically see this table reflected as a Delta Lake table in your lakehouse, ready for you to use throughout Fabric.
If your new Iceberg table shortcut doesn't appear as a usable table, check the Troubleshooting section.
Troubleshooting
The following tips can help make sure your Iceberg tables are compatible with this feature:
Check the folder structure of your Iceberg table
Open your Iceberg folder in your preferred storage explorer tool, and check the directory listing of your Iceberg folder in its original location. You should see a folder structure like the following example.
../
|-- MyIcebergTable123/
|-- data/
|-- A5WYPKGO_2o_APgwTeNOAxg_0_1_002.parquet
|-- A5WYPKGO_2o_AAIBON_h9Rc_0_1_003.parquet
|-- metadata/
|-- 00000-1bdf7d4c-dc90-488e-9dd9-2e44de30a465.metadata.json
|-- 00001-08bf3227-b5d2-40e2-a8c7-2934ea97e6da.metadata.json
|-- 00002-0f6303de-382e-4ebc-b9ed-6195bd0fb0e7.metadata.json
|-- 1730313479898000000-Kws8nlgCX2QxoDHYHm4uMQ.avro
|-- 1730313479898000000-OdsKRrRogW_PVK9njHIqAA.avro
|-- snap-1730313479898000000-9029d7a2-b3cc-46af-96c1-ac92356e93e9.avro
|-- snap-1730313479898000000-913546ba-bb04-4c8e-81be-342b0cbc5b50.avro
If you don't see the metadata folder, or if you don't see files with the extensions shown in this example, then you might not have a properly generated Iceberg table.
Check the conversion log
When an Iceberg table is virtualized as a Delta Lake table, a folder named _delta_log/ can be found inside the shortcut folder. This folder contains the Delta Lake format's metadata (the Delta log) after successful conversion.
This folder also includes the latest_conversion_log.txt file, which contains the latest attempted conversion's success or failure details.
To see the contents of this file after creating your shortcut, open the menu for the Iceberg table shortcut under Tables area of your lakehouse and select View files.
You should see a structure like the following example:
Tables/
|-- MyIcebergTable123/
|-- data/
|-- <data files>
|-- metadata/
|-- <metadata files>
|-- _delta_log/ <-- Virtual folder. This folder doesn't exist in the original location.
|-- 00000000000000000000.json
|-- latest_conversion_log.txt <-- Conversion log with latest success/failure details.
Open the conversion log file to see the latest conversion time or failure details. If you don't see a conversion log file, conversion wasn't attempted.
If conversion wasn't attempted
If you don't see a conversion log file, then the conversion wasn't attempted. Here are two common reasons why conversion isn't attempted:
The shortcut wasn't created in the right place.
In order for a shortcut to an Iceberg table to get converted to the Delta Lake format, the shortcut must be placed directly under the Tables folder of a non-schema-enabled lakehouse. You shouldn't place the shortcut in the Files section or under another folder if you want the table to be automatically virtualized as a Delta Lake table.
The shortcut's target path is not the Iceberg folder path.
When you create the shortcut, the folder path you select in the target storage location must only be the Iceberg table folder. This folder contains the
metadataanddatafolders.
"Fabric capacity region cannot be validated" error message in Snowflake
If you are using Snowflake to write a new Iceberg table to OneLake, you might see the following error message:
Fabric capacity region cannot be validated. Reason: 'Invalid access token. This may be due to authentication and scoping. Please verify delegated scopes.'
If you see this error, have your Fabric tenant admin double-check that you've enabled both tenant settings mentioned in the Write an Iceberg table to OneLake using Snowflake section:
- In the upper-right corner of the Fabric UI, open Settings, and select Admin portal.
- Under Tenant settings, in the Developer settings section, enable the setting labeled Service principals can use Fabric APIs.
- In the same area, in the OneLake settings section, enable the setting labeled Users can access data stored in OneLake with apps external to Fabric.
Limitations and considerations
Keep in mind the following temporary limitations when you use this feature:
Supported data types
The following Iceberg column data types map to their corresponding Delta Lake types using this feature.
Iceberg column type Delta Lake column type Comments intintegerlonglongSee Type width issue. floatfloatdoubledoubleSee Type width issue. decimal(P, S)decimal(P, S)See Type width issue. booleanbooleandatedatetimestamptimestamp_ntzThe timestampIceberg data type doesn't contain time zone information. Thetimestamp_ntzDelta Lake type isn't fully supported across Fabric workloads. We recommend the use of timestamps with time zones included.timestamptztimestampIn Snowflake, to use this type, specify timestamp_ltzas the column type during Iceberg table creation. More info on Iceberg data types supported in Snowflake can be found here.stringstringbinarybinarytimeN/A Not supported Type width issue
If you use Snowflake to write your Iceberg table and the table contains column types
INT64,double, orDecimalwith precision >= 10, then the resulting virtual Delta Lake table may not be consumable by all Fabric engines. You may see errors such as:Parquet column cannot be converted in file ... Column: [ColumnA], Expected: decimal(18,4), Found: INT32.We're working on a fix for this issue.
Workaround: If you're using the Lakehouse table preview UI and see this issue, you can resolve this error by switching to the SQL Endpoint view (top right corner, select Lakehouse view, switch to SQL Endpoint) and previewing the table from there. If you then switch back to the Lakehouse view, the table preview should display properly.
If you're running a Spark notebook or job and encounter this issue, you can resolve this error by setting the
spark.sql.parquet.enableVectorizedReaderSpark configuration tofalse. Here's an example PySpark command to run in a Spark notebook:spark.conf.set("spark.sql.parquet.enableVectorizedReader","false")Iceberg table metadata storage isn't portable
The metadata files of an Iceberg table refer to each other using absolute path references. If you copy or move an Iceberg table's folder contents to another location without rewriting the Iceberg metadata files, the table becomes unreadable by Iceberg readers, including this OneLake feature.
Workaround:
If you need to move your Iceberg table to another location to use this feature, use the tool that originally wrote the Iceberg table to write a new Iceberg table in the desired location.
Iceberg table folders must contain only one set of metadata files
If you drop and recreate an Iceberg table in Snowflake, the metadata files aren't cleaned up. This behavior is by design, in support of the
UNDROPfeature in Snowflake. However, because your shortcut points directly to a folder and that folder now has multiple sets of metadata files within it, we can't convert the table until you remove the old table’s metadata files.Conversion will fail if more than one set of metadata files are found in the Iceberg table's metadata folder.
Workaround:
To ensure the converted table reflects the correct version of the table:
- Ensure you aren’t storing more than one Iceberg table in the same folder.
- Clean up any contents of an Iceberg table folder after dropping it, before recreating the table.
Metadata changes not immediately reflected
If you make metadata changes to your Iceberg table, such as adding a column, deleting a column, renaming a column, or changing a column type, the table may not be reconverted until a data change is made, such as adding a row of data.
We're working on a fix that picks up the correct latest metadata file that includes the latest metadata change.
Workaround:
After making the schema change to your Iceberg table, add a row of data or make any other change to the data. After that change, you should be able to refresh and see the latest view of your table in Fabric.
Region availability limitation
The feature isn't yet available in the following regions:
- Qatar Central
- Norway West
Workaround:
Workspaces attached to Fabric capacities in other regions can use this feature. See the full list of regions where Microsoft Fabric is available.
Private links not supported
This feature isn't currently supported for tenants or workspaces that have private links enabled.
We're working on an improvement to remove this limitation.
OneLake shortcuts must be same-region
We have a temporary limitation on the use of this feature with shortcuts that point to OneLake locations: the target location of the shortcut must be in the same region as the shortcut itself.
We're working on an improvement to remove this requirement.
Workaround:
If you have a OneLake shortcut to an Iceberg table in another lakehouse, be sure that the other lakehouse is associated with a capacity in the same region.
Certain Iceberg partition transform types are not supported
Currently, the Iceberg partition types
bucket[N],truncate[W], andvoidare not supported.If the Iceberg table being converted contains these partition transform types, virtualization to the Delta Lake format will not succeed.
We're working on an improvement to remove this limitation.
Related content
- Use Snowflake to write or read Iceberg tables in OneLake.
- Learn more about Fabric and OneLake security.
- Learn more about OneLake shortcuts.