Azure Synapse Analytics
An Azure analytics service that brings together data integration, enterprise data warehousing, and big data analytics. Previously known as Azure SQL Data Warehouse.
5,373 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EJ%3C/text%3E%3C/svg%3E)
Hi all, I am working with Azure Synapse Spark pool with below configuration:
Spark version 3.3
Python version3.8
Scala 2.12.15
Java version 1.8.0_282
I am trying to read an excel file in a Azure ADL folder using libraries pandas and spark.pandas. The code executed is:
import pandas as pd
Files2Read = "abfss://*****@ADLACCOUNT.dfs.core.windows.net/FOLDER/SUBFOLDER/FILENAME.xlsx"
try:
df = pd.read_excel(Files2Read)
dfOriginal = spark.createDataFrame(df)
except Exception as e:
mssparkutils.notebook.exit(str(e))*
The code is working if I execute it in a notebook but when I call the notebook from another notebook with mssparkutils the code fails with error "Notebook Exit: 'JavaPackage' object is not callable". The extended error:
ERROR notebookUtils: Uncaught throwable from user code: ---------------------------------------------------------------------------TypeError Traceback (most recent call last)/tmp/ipykernel_27337/1874386971.py in <module>
49 df = pd.read_excel(Files2Read)
---> 50 dfOriginal = spark.createDataFrame(df)
51 #######Clean Dataframe
/opt/spark/python/lib/pyspark.zip/pyspark/sql/session.py in createDataFrame(self, data, schema, samplingRatio, verifySchema)
890 # Create a DataFrame from pandas DataFrame.
--> 891 return super(SparkSession, self).createDataFrame( # type: ignore[call-overload]
892 data, schema, samplingRatio, verifySchema
/opt/spark/python/lib/pyspark.zip/pyspark/sql/pandas/conversion.py in createDataFrame(self, data, schema, samplingRatio, verifySchema)
435 raise
--> 436 converted_data = self._convert_from_pandas(data, schema, timezone)
437 return self._create_dataframe(converted_data, schema, samplingRatio, verifySchema)
/opt/spark/python/lib/pyspark.zip/pyspark/sql/pandas/conversion.py in _convert_from_pandas(self, pdf, schema, timezone)
472 else:
--> 473 should_localize = not is_timestamp_ntz_preferred()
474 for column, series in pdf.iteritems():
/opt/spark/python/lib/pyspark.zip/pyspark/sql/utils.py in is_timestamp_ntz_preferred()
295 jvm = SparkContext._jvm
--> 296 return jvm is not None and jvm.PythonSQLUtils.isTimestampNTZPreferred()
TypeError: 'JavaPackage' object is not callable
During handling of the above exception, another exception occurred:
NotebookExit Traceback (most recent call last)/tmp/ipykernel_27337/1874386971.py in <module>
57 except Exception as e:
58 print("Error in temp_"+DeltaTableName)
---> 59 mssparkutils.notebook.exit(str(e))
~/cluster-env/clonedenv/lib/python3.8/site-packages/notebookutils/mssparkutils/notebook.py in exit(value)
19
20 def exit(value):
---> 21 nb.exit(value)
~/cluster-env/clonedenv/lib/python3.8/site-packages/notebookutils/mssparkutils/handlers/notebookHandler.py in exit(self, value)
56 def exit(self, value):
57 self.exitVal = str(value)
---> 58 raise NotebookExit(value)
NotebookExit: 'JavaPackage' object is not callable
Did you see this behavior before?

Hi @JLopez ,
Welcome to Microsoft Q&A platform and thanks for posting your question here.
As I understand your query, you are facing an error while trying to call one notebook through another. Please let me know if that is not the case.
What is the code you are running to call another notebook , could you please the screenshot of the same.
I tried to repro your scenario and was able to get through it without any error by using '%run' command to call another notebook. Kindly check the below images.
Note: Make sure the notebook that you are calling from another notebook is published , or do check 'Enable unpublished notebook reference' option in the notebook properties.
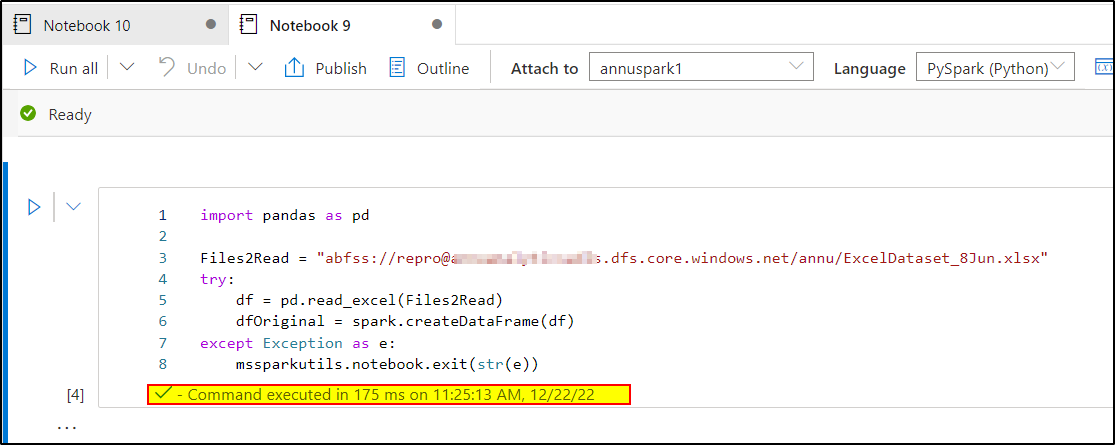
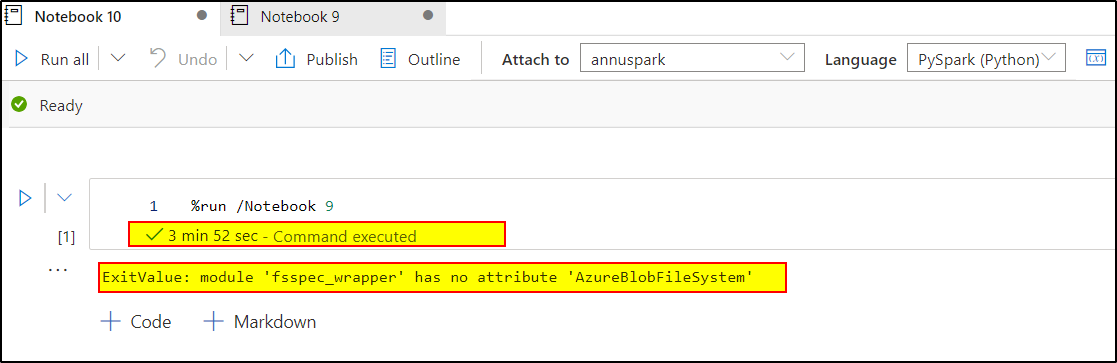

Please let us know how it goes.
Hi @AnnuKumari-MSFT , thank you for your answer.
I execute it with below code and enabling the "unpublished notebook reference" getting the same error:
executionParameters = {
"Files2Read": "abfss://*****@ADLACCOUNT.dfs.core.windows.net/CONTAINER/FOLDER/.xlsx"
}
mssparkutils.notebook.run("Notebook 4",3600,executionParameters)
Hi @JLopez ,
I have reached out to Internal team for the issue you are facing. They are looking into it. I will respond back once I get some response from them. Thankyou.
Hi @JLopez ,
The product team has raised a Pull request to mitigate the issue , you are experiencing. The fix will be in place soon.
As per their communication , as a workaround, you can add a new cell in referenced notebook with below code block:
from py4j.java_gateway import java_import
jvm = SparkContext._jvm
java_import(jvm, "org.apache.spark.sql.api.python.*")
Please let us know how it goes. Thankyou .
Hi AnnuKumari-MSFT, I can confirm the workaround is working as expected.
Thanks to you and your team for your help.
Hi @JLopez ,
Thankyou for the confirmation on mitigation of the issue and thanks for accepting the answer. Glad to know it was helpful. I will keep you posted if I get any further communication from the team about the fix release. Thankyou.