Azure SQL Database
An Azure relational database service.
5,758 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EJK%3C/text%3E%3C/svg%3E)
I am looking for a C# solution to use a script task in SSIS so that I can load multiple csv files to SQL Tables
Now If I use a data flow task, then I have to create 1 DFT per file as each file has a different metadata ( unless there is some other way with dynamic DFT?)
So I checked the following solutions
http://www.techbrothersit.com/2016/03/how-to-create-tables-dynamically-from.html
http://www.techbrothersit.com/2016/04/how-to-load-flat-files-to-sql-server.html
One of this solution expects target table to be already present while other creates the table on the fly ( columns from the first line of the CSV) which is fine as well
Issue :-
Now my CSV files have comma as a delimiter and some of the columns have comma in the column value
eg some columns have numbers but with comma separated value eg 100,000
some columns have info about name of person which can be D'Souza
`
so the above scripts error out as they consider any comma as a field separator so error is thrown like count of values doesn't match the number or columns
OR the apostrophe character throws the error as invalid data
eg here's the structure of one csv file ( check lines 2,3)
Thanks in advance.
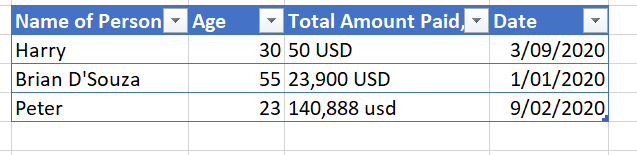

The borrowed solutions use simple text reading operations that are not suitable for CSV files, which contain commas or quotation marks within values, or which contain multiline values.
If you want to process CSV files yourself, then consider a designed class: TextFieldParser [https://learn.microsoft.com/en-us/dotnet/api/microsoft.visualbasic.fileio.textfieldparser?view=netframework-4.8]. It can be used in C# but requires a reference to Microsoft.VisualBasic assembly.
You can find many samples, for example:
using Microsoft.VisualBasic.FileIO;
. . .
using (var p = new TextFieldParser(@"C:\myfile.csv")
{
TextFieldType = FieldType.Delimited,
Delimiters = new[] { "," },
HasFieldsEnclosedInQuotes = true
})
{
while (!p.EndOfData)
{
// read and split one line of fields
string[] fields = p.ReadFields();
// each fields[i] is a value of a column
// . . .
}
}
It is not difficult to identify the first header row.
If you decide to build dynamic SQL, which is not always recommended, then replace each apostrophe (like “Brian D'Souza”) with two apostrophes using string.Replace function.
Try and debug it in a separate console application, in Visual Studio, before moving to SSIS.
But also check if SSIS contains other appropriate tasks.
Thanks I am not a C# developer but this code seems easy as fields[i] refer to a column .I can use it to create an insert statement
so by using this class I din't have to handle regular expressions?
[...] so by using this class I din't have to handle regular expressions?
This class can read valid CSV files and deliver the parsed values of the fields. You do not have to use Regular Expressions for parsing.
But if you want to process some specific extracted fields, (for example: get currency symbol from Total Amount Paid column), you can use Regular Expressions after you get the data with TextFieldParser.
Thanks for a quick response. I tested and it worked like magic.
However, my intention is to have just single SSIS package with just 1 script task to load ALL tables.
However the method you suggested, I am getting the column values in an array fields[0],fields[1] etc which implies I need to create an insert statement with that array members in it which means if a file has 5 columns then my code should be different from the code which can load a file with 10 columns.
So any way to have one script which can generate a dynamic insert statement and load table with the same name of the file. ( just as in the example in one of the links I shared)
If you want to use a similar approach, then maybe try something like this:
. . .
string[] fields = p.ReadFields();
string query = "Insert into " + SchemaName + "." + TableName + " (" + ColumnList + ") " +
"VALUES(" + string.Join( ", ", fields.Select( f => "'" + f.Replace( "'", "''" ) + "'" ) ) + " )";
. . .
This should work with any number of columns, assuming that values do not need adjustments to SQL format.
Thanks I will try this.
However, how ColumnList needs to be generated,
Earlier code you mentioned had a logic of using Field[0],[1] etc of the first line
but in my case the columns can vary per file
so how to generate the columnlist from first line?
Try something like this:
. . .
string ColumnList = null;
while (!p.EndOfData)
{
// read and split one line of fields
string[] fields = p.ReadFields();
if( ColumnList == null )
{
// first, header row
ColumnList = string.Join(", ", fields.Select( f => "[" + f.Replace( "]", "]]" ) + "]" ) );
}
else
{
// data row; insert to database
. . .
}
}
Thanks I tried this and it worked fine
ColumnList = string.Join(", ", fields.Select(f => "[" + f.Replace("'", "''") + "]"));
why does your code has Replace( "]", "]]" ) ? is it to replace ] in the column value to ]]
If table name or column name is also an SQL keyword, or contains certain characters like space or ‘]’, then CREATE TABLE and INSERT will fail. It is necessary to replace ‘]’ with ‘]]’ and to add ‘[‘ and ‘]’.
This answer has been deleted due to a violation of our Code of Conduct. The answer was manually reported or identified through automated detection before action was taken. Please refer to our Code of Conduct for more information.
Comments have been turned off. Learn more