Azure Percept
A comprehensive Azure platform with added security for creating edge artificial intelligence solutions.
72 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EVS%3C/text%3E%3C/svg%3E)
How many unique human voices can Azure Percept Audio recognize at one time.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EYM%3C/text%3E%3C/svg%3E)
This is a duplicate issue of https://learn.microsoft.com/en-us/answers/questions/916503/index.html
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EQ%3C/text%3E%3C/svg%3E)
Hello @vinit sawant , Thanks for reaching out with a great question. I hope the below information really helps with your initial query!
The Azure Percept Audio (sometimes called the Percept Ear) is a "System on a Module" or SoM.
The Azure Percept Audio SoM makes use of a couple of Azure Services to process Audio;
LUIS: Allows interaction with applications and devices using natural language.
Cognitive Speech Identification: is an Azure Service offering Text-to-speech, speech-to-text, speech translation and speaker recognition.
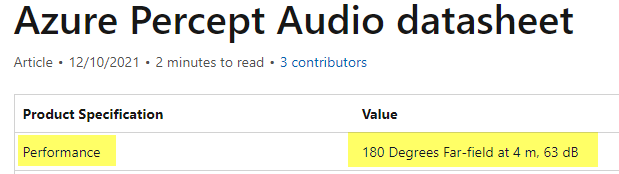
Updated: 7/26/2022: Below is the update from the AIML engineers on the initial query. I Hope this helps!
"Speech Identification verifies and identifies speakers by their unique voice characteristics, by using voice biometry. You provide audio training data for a single speaker, which creates an enrollment profile based on the unique characteristics of the speaker's voice. You can then cross-check audio voice samples against this profile to verify that the speaker is the same person (speaker verification). You can also cross-check audio voice samples against a group of enrolled speaker profiles to see if it matches any profile in the group (speaker identification). Then you do recognition, it will recognize based on the file.
Characteristics somehow like nose, eye, lip,... in face recognition"
Please let us know if you need further help in this matter, happy to help!
Hello @QuantumCache ,
Thank you for your quick response and useful links. That really helped.
But this brings me back to another question which goes like this, If the Azure percept audio edge module (The Percept Ear) is placed in a room where a lot of people are, How can it identify the keyword spoken by whom, or How can it recognize how many speakers are present by unique IDs or something like that?
I am checking on this, meanwhile please feel free to comment on this thread for further discussion points..
Hello @vinit sawant ,Below is the update from the AIML engineers on the initial query. I Hope this helps!
Speech Identification verify and identify speakers by their unique voice characteristics, by using voice biometry. You provide audio training data for a single speaker, which creates an enrollment profile based on the unique characteristics of the speaker's voice. You can then cross-check audio voice samples against this profile to verify that the speaker is the same person (speaker verification). You can also cross-check audio voice samples against a group of enrolled speaker profiles to see if it matches any profile in the group (speaker identification). Then you do recognition, it will recognize based on the file.
Characteristics somehow like nose, eye, lip,... in face recognition.
Please accept the helpful response as 'Answer', which will be helpful to others as well with similar questions.