SQLSweet16!, Episode 3: Parallel INSERT … SELECT
Sanjay Mishra, with Arvind Shyamsundar
Reviewed By: Sunil Agarwal, Denzil Ribeiro, Mike Ruthruff, Mike Weiner
Loading large amounts of data from one table to another is a common task in many applications. Over the years, there have been several techniques to improve the performance of the data loading operations. SQL Server 2014 allowed parallelism for SELECT … INTO operations. However, the users needed more flexibility, in terms of placement of the target table, existing data in the target table, etc., which are not possible with the SELECT … INTO statement. Loading data into an existing table (with or without existing data) through an INSERT … SELECT statement has been a serial operation. Until SQL Server 2016.
SQL Server 2016, under certain conditions, allows an INSERT … SELECT statement to operate in parallel, thereby significantly reducing the data loading time for these applications. A hidden gem!
Figure 1 illustrates loading time with and without parallelism. The test was performed on an 8-core machine (Figure 3 shows the degree of parallelism achieved), on a table with 50 million rows. Your mileage will vary.
[caption id="attachment_2985" align="alignnone" width="827"]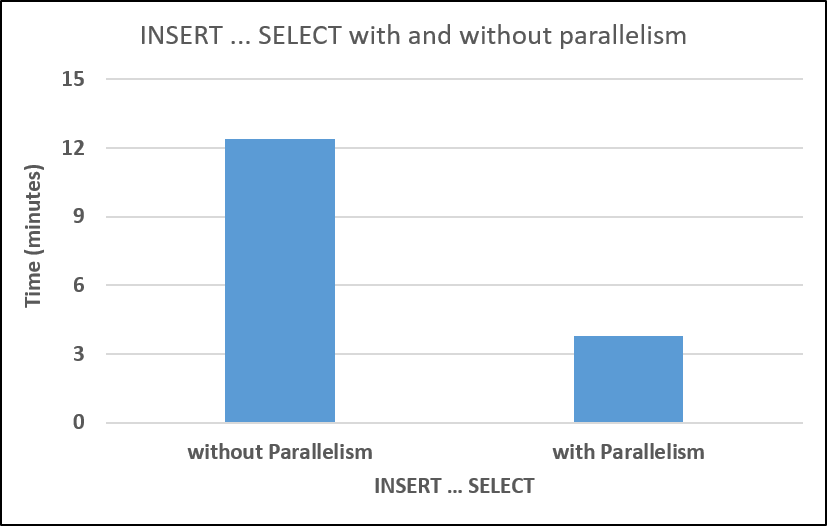 Figure 1: INSERT ... SELECT with and without parallelism (SQL Server 2016)[/caption]
Figure 1: INSERT ... SELECT with and without parallelism (SQL Server 2016)[/caption]
Important to Know
Two important criteria must be met to allow parallel execution of an INSERT … SELECT statement.
- The database compatibility level must be 130. Execute “SELECT name, compatibility_level FROM sys.databases” to determine the compability level of your database, and if it is not 130, execute “ALTER DATABASE <MyDB> SET COMPATIBILITY_LEVEL = 130” to set it to 130. Changing the compatibility level of a database influences some behavior changes. You should test and ensure that your overall application works well with the new compatibility level.
- Must use the TABLOCK hint with the INSERT … SELECT statement. For example: INSERT INTO table_1 WITH (TABLOCK) SELECT * FROM table_2.
There are a few restrictions under which parallel insert is disabled, even when the above requirements are met. We will cover the restrictions, and work arounds, if applicable, in a separate blog post.
How to know you are getting parallelism
The simplest way to check for parallelism is the execution plan. Figure 2 shows an execution plan for an INSERT … SELECT statement without parallelism.
[caption id="attachment_2986" align="alignnone" width="975"]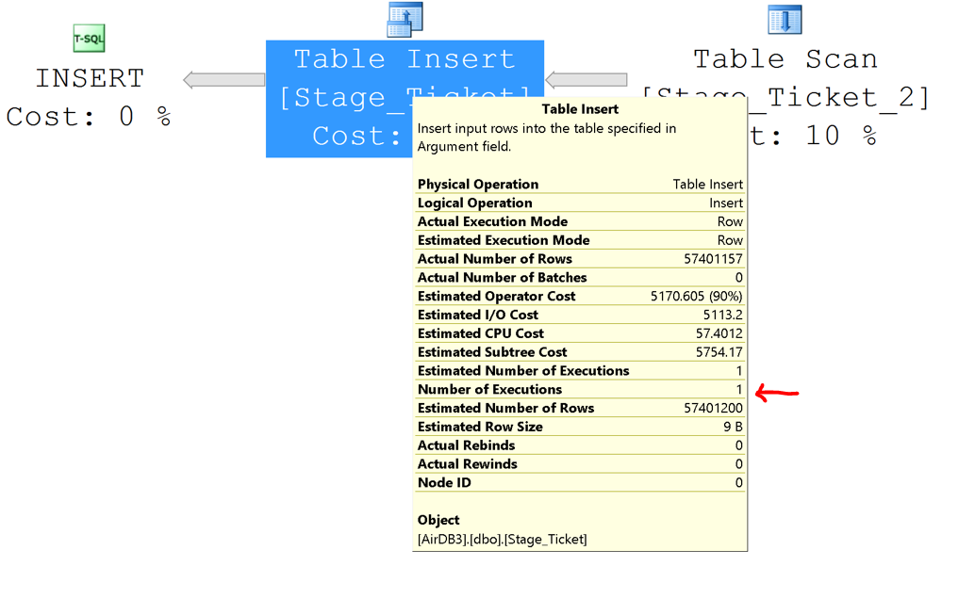 Figure 2: INSERT ... SELECT execution plan without parallelism[/caption]
Figure 2: INSERT ... SELECT execution plan without parallelism[/caption]
Under appropriate conditions, the same statement can use parallelism, as shown in Figure 3.
[caption id="attachment_2976" align="alignnone" width="1000"]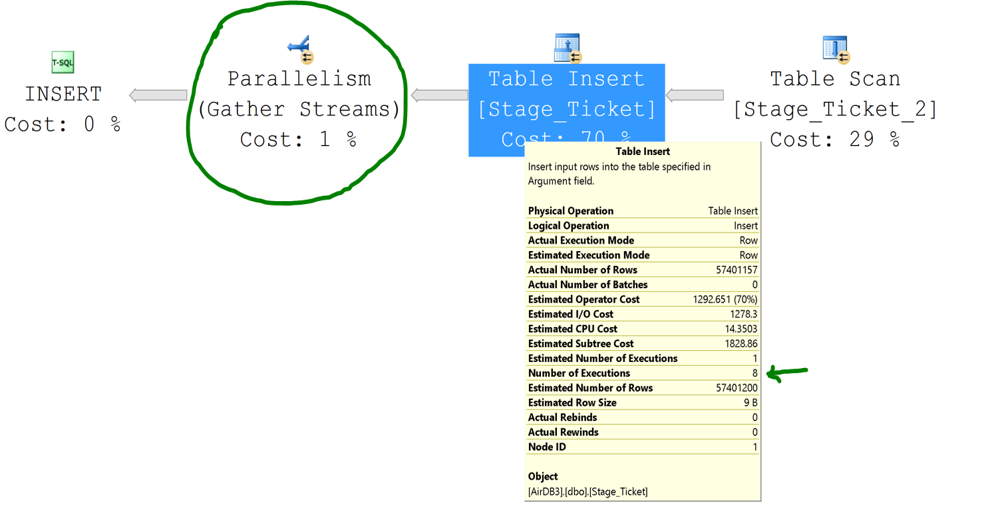 Figure 3: INSERT ... SELECT execution plan with parallelism[/caption]
Figure 3: INSERT ... SELECT execution plan with parallelism[/caption]
Call to Action
Tell us about your application scenarios where you plan to use this functionality. Also if you are already taking advantage of this hidden gem, share some data points, such as data volume, load time, the benefits you are seeing from parallelism, etc.
Comments
- Anonymous
July 06, 2016
I'm very excited about this feature and will be testing it out shortly. I'm very interested in the restrictions and will be looking forward to the blog post.- Anonymous
July 26, 2016
I'm seeing parallel inserts into temp tables without using "with (tablock)" as well.- Anonymous
July 27, 2016
That's correct, Justin. https://blogs.msdn.microsoft.com/sqlcat/2016/07/21/real-world-parallel-insert-what-else-you-need-to-know covers the reason why.
- Anonymous
- Anonymous
- Anonymous
July 06, 2016
So... similar restrictions to minimal logging? Looking forward to the follow up post.- Anonymous
August 08, 2016
Hi Erik, minimal logging and parallelism are not related.Minimal logging involves logging only the information that is required to recover the transaction without supporting point-in-time recovery. minimal logging improve performance as we do not write to the log file the same data as without minimal logging, which improve the performance ("write less get more performance").* minimal logging is not new and does not need compatibility level 130, which is one of the restriction for parallelism in 2016 insert.* minimally logged works under the bulk-logged recovery model and the simple recovery model, while the feature works on full mode.* and more...- Anonymous
September 23, 2016
Right, my point is that there's a similar set of restrictions for when either can be utilized by the engine for inserts. - Anonymous
October 01, 2016
Thanks for sharing great stuff !In older version of SQL Server, minimal logging worked only with bulk-logged recovery model. Has there been any change recently to make this feature available with Simple recovery model ?Please correct me if my understanding is not correct.Anil
- Anonymous
- Anonymous
- Anonymous
July 11, 2016
Looks pretty straightforward? Just make sure you're in 2016 compat mode and use a tablock hint....... - Anonymous
July 11, 2016
Very cool. Thanks for the heads up on another "hidden gem". Could you add the code for the test harness that you used and the full CREATE TABLE statements (including indexes, etc) so that we can try to duplicate your tests to see if we come up with similar results? Thanks.- Anonymous
July 14, 2016
You can actually reproduce with any dataset. We would like to hear the gains you achieve with your workload. If you are looking for a sample database, you can try the SQL Server 2016 sample databases on Github: https://github.com/Microsoft/sql-server-samples/tree/master/samples/databases/wide-world-importers. Looking forward to hear your learnings and experience.- Anonymous
November 10, 2016
Apologies for the late reply. I lost track of this thread.I'm well aware that this can be done with any workload but that's not what I'm looking for. I'm looking for the workload used in the article so I can do some performance comparisons. Creating a 50 million row test table is pretty easy to do nowadays but I'd like to see the CREATE TABLE statement along with whatever the PK is and any other indexes that may be present.
- Anonymous
- Anonymous
- Anonymous
July 14, 2016
HelloOne of the obvious restrictions is when the inserted table has a before/after insert trigger implemented on it. I have right now tested it.A second restriction (though that I haven't tested i) is when the inserted table has a Foreign key constraint implemented on itBest regardsMohamed Houriwww.hourim.wordpress.com - Anonymous
July 14, 2016
Great feature and post!Let's wait the post with the restrictions of this feature. - Anonymous
July 20, 2016
Is parallel INSERT ... SELECT only implemented for heaps?- Anonymous
July 20, 2016
That is correct: parallel INSERT...SELECT is not supported for clustered indexes. It does work very well with Clustered Columnstore though. We will publish a blog post with more details on parallel INSERT...SELECT very soon!
- Anonymous
- Anonymous
July 25, 2016
The follow up article on restrictions and considerations is here: https://blogs.msdn.microsoft.com/sqlcat/2016/07/21/real-world-parallel-insert-what-else-you-need-to-know/ - Anonymous
July 25, 2016
I am new to SQL. I am with an accounting background. I am a beginner , u can say. Still I can fairly understand what u r up to.I shall dig your website to jump into the bandwagon.Great - Anonymous
August 12, 2016
Hi guys, great article, thanks for this. With updates and selects using "With Nolock" introduces a possibility of dirty reads or updates. Would the same rule apply to the "With Tablock" cluase?Dean