Azure Site Recovery–VMWARE (5)
Připravil jsem pro vás sérii článků, zabývající se technologií Azure Site Recovery. Konkrétně v šesti na sebe navazujících článcích se dozvíte, jak správně nasadit Azure Site Recovery. Postupně vás tyto články od začátku provedou celým procesem a to od samotné instalace a nastavení potřebných komponent, po obnovení virtuálních strojů po výpadku produkčního prostředí. Všechny na sebe navazující články pak budou popisovat spolupráci Azure Site Recovery v kombinaci s VMWARE virtualizační platfomou.
Níže jsou odkazy na předcházející články:
Azure Site Recovery – VMWARE (1) Azure Site Recovery – VMWARE (2) Azure Site Recovery – VMWARE (3) Azure Site Recovery – VMWARE (4)
V této části článku se budeme zabývat TEST FAILOVER procedurou, tedy proceduru, kdy otestujeme, zda jsou replikované virtuální stroje v Azure plně funkční.
1. Testování Failoveru
Nyní si asi kladete otázku. Dobře teď mám vše nastaveno, a jak zjistím, že to vše skutečně funguje. Jak si ověřím, že v případě výpadku budou fungovat naše aplikace, weby apod. Možnosti jsou dvě. Možnost radikální a složitější se jmenuje FAILOVER, resp. Unplanned/Neplánovaný Failover. A ta jednodušší metoda se jmenu TEST FAILOVER. V této části si ukážeme TEST FAILOVER.
Ten má tu výhodu, že obvykle neovlivní stávající produkční prostředí, nevýhodou pak je, že nelze pravděpodobně otestovat úplně vše.
TEST FAILOVER funguje tak, že dojde ke spuštění virtuálních strojů v samotném Azure a to z dat/virtuálních disků uložených ve storage accountu v Azure. A to buď zařazením do specifické Azure vNet, nebo úplně izolovaně.
V sekci „PROTECTED ITEMS“ – „PROTECTION GROUPS“ vstoupíme do konkrétní skupiny.

Zde pak označíme konkrétní jeden virtuální stroj.

Ve spodní části okna pak klikneme na tlačítko „TEST FAILOVER“.

Zobrazí se okno pro testování failoveru. Zde pak máme možnost vybrat, do jaké virtuální sítě bude virtuální stroj při této operaci zařazen. Pokud vybereme volbu „None“, spustí se virtuální stroj v „izolovaném“ módu, kdy bude virtuální stroj dostupný pouze skrze VIP IP adresu jeho Cloud Service a případné nastavené Endpointy. Pokud vybereme existující virtuální síť, je zde vícero možností/scénářů.
1. Virtuální síť není nijak propojená s On-Premise prostředím. V tom případě tento test nemůže nijak ovlivnit produkční On-Premise prostředí, ale výhodou je, že pokud umístíme do stejné sítě jiný již existující virtuální stroj v Azure, můžeme otestovat i vnitřní komunikaci a nemusíme například, vůbec definovat Endponty a tím vystavovat konkrétní porty/služby do prostředí „Internetu“.
2. Virtuální síť je propojená s On-Premise prostředím např. pomocí Site-to-Site VPN, ale je připojená do izolované On-Premise sítě. Tento scénář je náročnější na realizaci z hlediska konfigurace On-Premise prostředí. Předpokládá, že existuje On-Premise izolovaná síť, která není routována dál do jiných interních sítí a na této izolované sítí jsou k dispozici např. testovací klientské stanice apod. Výhodou tohoto řešení je, že neovlivní stávající produkční prostředí, a navíc lze tímto způsobem otestovat i spuštění komplexního prostředí v Azure, kde pak lze na straně klientů v On-Premise izolované síťi otestovat, zda jsou služby/aplikace dostupné. A tak si ověřit co by mohlo nastat v případě, pokud by nastal skutečný výpadek v On-Premise prostředí. Samozřejmě tímto způsobem nelze pravděpodobně otestovat vše.
3. Virtuální síť je propojená s On-Premise prostředím např. pomocí Site-to-Site VPN a je připojená do On-Premise sítě, která je dále routovaná. Tento scénář se spíše váže na samotný Failover, kdy potřebujete zajistit dostupnost služeb pro interní klienty v případě výpadku On-Premise prostředí. A kdy se předpokládá, že původní produkční servery replikované do Azure aktuálně nejsou dostupné. Nicméně při samotném TEST FAILOVER se dá použit i tento scénář. Nicméně hodně záleží na tom, jaké služby či aplikace jsou testovány a jak. Tedy je třeba zamezit ovlivnění stávajícího produkčního prostředí.
V mém případě jsem vybral volbu „Infra-production“

Pokud přejdeme do sekce „JOBS“ a vstoupíme do konkrétní běžící úlohy TEST FAILOVER, uvidíme detaily samotné úlohy a její průběh. Pokud vše proběhne v pořádku, zastaví se úloha ve fází, kdy očekává potvrzení úspěšnosti/dokončení testování. To tedy znamená, že je čas otestovat služby běžící na virtuálním stroji v Azure.

Jak je vidět z detailu výpisu virtuálního stroje, je ve stavu Running, má veřejnou IP adresu a také díky tomu, že jsem jej nechal zařadit do virtuální sítě „Infra-production“, získal i konkrétní lokální IP adresu.

Zde pak detail Cloud Service, která je rovněž automaticky vytvořena.

Ve výchozím stavu, pokud testujeme failover jen pro jeden virtuální stroj, nedojde k nastavení žádného Endpointu.

Proto jsem přidal Endpoint pro port TCP 3389 (RDP) a pro port TCP 80 (HTTP).

Poté jsem otestoval, že na portu TCP 80 poslouchá služba IIS. Tedy máte otestovánu dostupnost služby IIS.

Dále jsem se přihlásil před RDP klienta, abych otestoval, zda je funkční připojení na vzdálenou plochu.

Jakmile mám otestováno, vrátím se do sekce „JOBS“, vstoupím do konkrétní úlohy a provedu dokončení testu kliknutím na tlačítko „COMPLETE TEST“

Následně jsem vyzván k doplnění komentáře, který se uloží a co je hlavní mám možnost říci, že dojde k úklidu a celé testovací prostředí vzniklé při TEST FAILOVER bude zrušeno.

Zde je pak ukázka kompletně dokončené úlohy.

V případě testování kompletních scénářů, mohu realizovat testovací failover prostřednictvím RECOVERY PLAN. Tedy vyberu konkrétní recovery plán, který může obsahovat různé skupiny počítačů a na ně navázané sckripty a spustit TEST FAILOVER. 

Stejně jako v předchozím případě jsem nechal virtuální stroje zařadit do sítě „Infra-Production“

Kompletní TEST FAILOVER evidentně doběhl do fáze čekání na prověření. A jak jde vidět skript se rovněž „úspěšně“ dokončil. Ale… po prověření virtuálních strojů jsem zjistil, že nedošlo k přidání EndPointů. Tedy co s tím..?

Musíme se přesunout v Azure do části „AUTOMATION“, kde máme z galerie vytvořený náš RUNBOOK. Vstoupíme do RUNBOOKu.

Zde klikneme na sekci „JOBS“ a vybereme konkrétní úlohu.

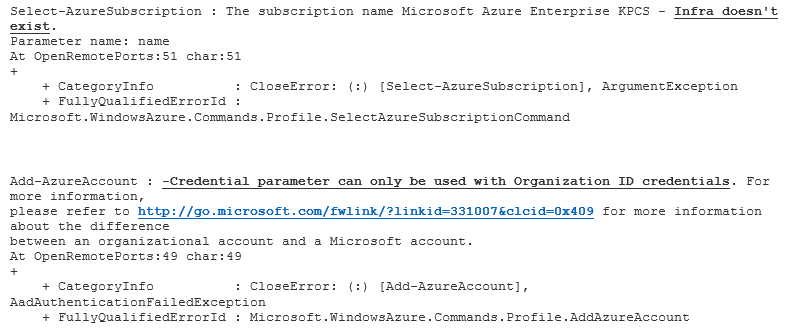
Dále přejdeme do sekce „HISTORY“ kde již vidíme, že skript skončil vygenerováním dvou chyb.

Už první chyba nám naznačí to, co jsem předpokládal a to, že doplnění pověření pro poštěstění skriptu již delší dobu musí být realizováno pomocí účtu, který odpovídá organizaci. V mém případě xxxxxx@kpcs.cz (nebo pak doménovému účtu z interní Azure Active Directory). A nejsou podporovány účty např. xxxxx@outlook.com apod. Dalším možným problémem v samotném Runbooku je parametr –SubscriptionName. Ten již v novějších verzích Azure PowerShell není podporován. A je třeba jej nahradit parametrem –SubscriptionID. Tedy v samotném příkladu Runbooku je chyba.
V rámci samotného RUNBOOKu přejdeme do sekce „AUTHOR“ – „PUBLISHED“ a dolní části okna klikneme na tlačítko „EDIT“


Zde jsem pak provedl úpravy v kódu a nahradil názvy proměnných

Poté jsem upravený skript uložil tlačítkem „SAVE“ a vypublikoval pomocí tlačítka „PUBLISH“.

Také jsem upravil proměnnou a nahradil SubscriptionName za SubscriptionID.


A nakonec jsem změnil uživatele v rámci definice pověření.

- Jakub Heinz, KPCS CZ
Mohlo by vás také zajímat:
Protecting Your VMware and Physical Servers by Using Microsoft Azure Site Recovery