Simplified Lambda Architecture with Cosmos DB and Databricks
 By Theo van Kraay, Data and AI Solution Architect at Microsoft
By Theo van Kraay, Data and AI Solution Architect at Microsoft
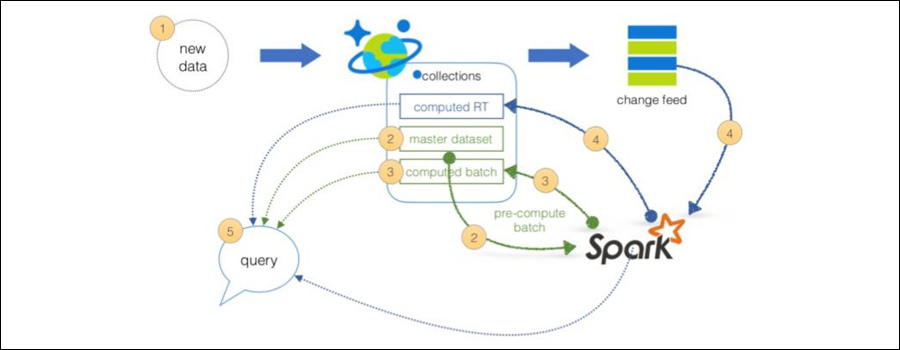
Lambda architectures enable efficient data processing of massive data sets, using batch-processing, stream-processing, and a serving layer to minimize the latency involved in querying big data. To implement a lambda architecture on Azure, you can combine the following technologies to accelerate real-time big data analytics:
- Azure Cosmos DB, the industry's first globally distributed, multi-model database service.
- Azure Databricks, a fast, easy and collaborative Apache Spark-based analytics platform optimised for Azure
- Azure Cosmos DB change feed, which streams new data to the batch layer for Databricks to process
- The Spark to Azure Cosmos DB Connector
Designed in collaboration with the original founders of Apache Spark, Azure Databricks helps customers accelerate innovation with one-click setup, streamlined workflows and an interactive workspace that enables collaboration between data scientists, data engineers and business analysts. As an Azure service, customers automatically benefit from the native integration with other Azure services such as Power BI and Cosmos DB, as well as from enterprise-grade Azure security, including Active Directory integration, compliance and enterprise-grade SLAs.
This blog serves as an addendum to a previously published article here, which walks through in detail how a simplified lambda architecture can be implemented using Azure Cosmos DB and Spark. The previous article was based on Spark on HDInsight. This blog will clarify how to use Azure Databricks with Cosmos DB in the same way.
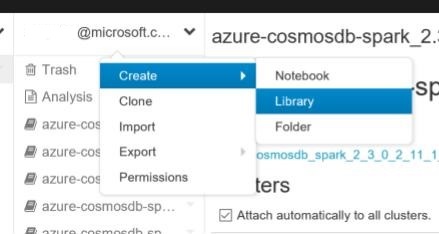
The Cosmos DB Spark Connector is available as a Maven release, and adding it to the Databricks environment is straight forward. Just right click under the user pane area in the Databricks home area and select Create -> Library:
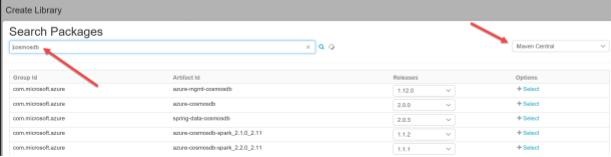
You should enter the latest Maven coordinate, e.g. com.microsoft.azure:azure-cosmosdb-spark_2.3.0_2.11:1.2.0:

Or, you can search for it by clicking “Search Spark Packages and Maven Central” above, and search as below:
When you have the required Coordinate, hit create (this will start resolving dependencies):
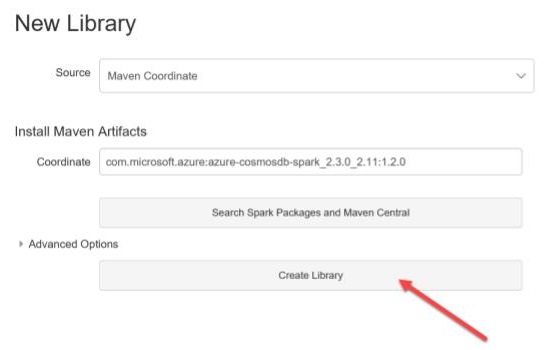
A library with a list of Maven artefacts will be created:

As above, ensure you check “Attach automatically to all clusters” at the bottom left. You will need to restart clusters for the library to take effect. Using the Maven coordinates to add dependencies required in Databricks is the best and easiest approach. However, in some scenarios, it might be necessary to take a particular feature or fix to a Scala project which might be maintained in Maven, but where the required fix is only available in a GitHub fix branch, and not in the latest stable Maven release. For some detailed guidance on how to do this, see here.
Once restarted, we are ready to start building a Lambda Architecture with Cosmos DB and Azure Databricks! Lets test out a prototype Speed Layer sample for a Lambda Architecture (see also here for more detailed Speed, Batch and Serving layers samples – these samples should now work on Databricks, but for Speed layer be sure to change “changefeedcheckpointlocation” to "/tmp” or other existing directory name in your Databricks File System).
You will require write-access to a Cosmos DB collection (refer to Create a Cosmos DB database account). Below is a Python script you can use to stream data from Twitter into Cosmos DB. You will need to enter your collection's configuration details in the code below (edit host, masterkey, database, collection variables). You also need to register the script as a new application at https://apps.twitter.com/. After choosing a name and application for your app, you will be provided with a consumer key, consumer secret, access token and access token secret - which need to be filled into the corresponding variables in the code below before you run it. Here we have used Tweepy's Python-based client to access Twitter's service. If not already installed, pip install tweepy==3.3.0. If you haven't already installed Cosmos DB's Python client, pip install pyDocumentDB
import tweepy
from tweepy import OAuthHandler
from config import *
from tweepy import Stream
from listener import CosmosDBListener
import pydocumentdb
from pydocumentdb import document_client
from pydocumentdb import documents
import datetime
# Enter twitter OAuth keys here.
consumer_key = 'add consumer key here'
consumer_secret = 'add consumer secret here'
access_token = 'add access token here'
access_secret = 'add access secret here'
# Enter CosmosDB config details below.
# Enter your masterKey, endpoint here.
masterKey = 'master key here'
host = 'cosmos db host url here'
# Enter your database, collection and preferredLocations here.
databaseId = 'database name here'
collectionId = 'collection name here'
if __name__ == '__main__':
auth = OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_secret)
api = tweepy.API(auth)
connectionPolicy = documents.ConnectionPolicy()
connectionPolicy.EnableEndpointDiscovery
connectionPolicy.PreferredLocations = preferredLocations
client = document_client.DocumentClient(host, {'masterKey': masterKey}, connectionPolicy)
dbLink = 'dbs/' + databaseId
collLink = dbLink + '/colls/' + collectionId
twitter_stream = Stream(auth, CosmosDBListener(client, collLink))
twitter_stream.filter(track=['#CosmosDB', '#ApacheSpark', '#ChangeFeed', 'ChangeFeed', '#MachineLearning', '#BigData', '#DataScience', '#Mongo', '#Graph'], async=True)
Run the above code to start sending tweets into Cosmos DB. When tweets are being sent, you should be able to use the Cosmos DB connector (Notebook from original article shown below):
// Import Libraries
import com.microsoft.azure.cosmosdb.spark._
import com.microsoft.azure.cosmosdb.spark.schema._
import com.microsoft.azure.cosmosdb.spark.config.Config
import org.codehaus.jackson.map.ObjectMapper
import com.microsoft.azure.cosmosdb.spark.streaming._
import java.time._
// Configure connection to Azure Cosmos DB Change Feed
val sourceConfigMap = Map(
"Endpoint" -> "Cosmos DB host here",
"Masterkey" -> "master key here",
"Database" -> "database name here",
"Collection" -> "collection name here",
"ConnectionMode" -> "Gateway",
"ChangeFeedCheckpointLocation" -> "/tmp ",
"changefeedqueryname" -> "Streaming Query from Cosmos DB Change Feed Interval Count")
// Start reading change feed as a stream
var streamData = spark.readStream.format(classOf[CosmosDBSourceProvider].getName).options(sourceConfigMap).load()
//**RUN THE ABOVE FIRST AND KEEP BELOW IN SEPARATE CELL
// Start streaming query to console sink
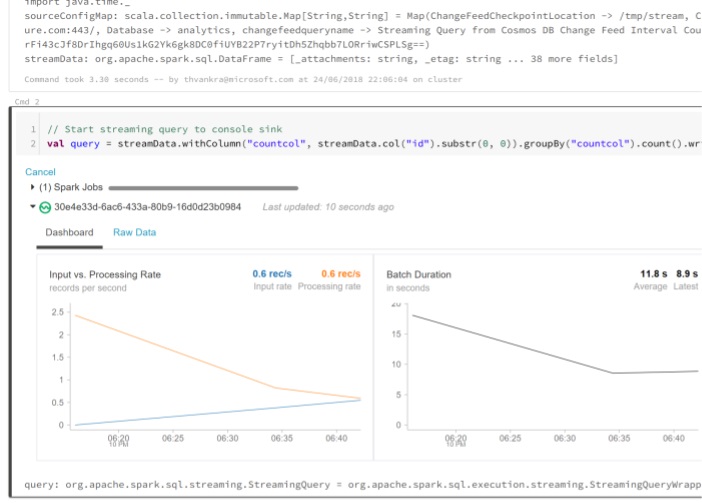
val query = streamData.withColumn("countcol", streamData.col("id").substr(0, 0)).groupBy("countcol").count().writeStream.outputMode("complete").format("console").start()
Resources
- If you’d like to learn more about Azure Cosmos DB, visit here
- To learn more about Cosmos DB use cases, visit here.
- To learn more about Azure Databricks, visit here.
- For a review of the Lambda Architecture pattern in general, visit here.
- For latest news and announcements on Cosmos DB, please follow us @AzureCosmosDB and #CosmosDB