Core concepts for Azure Kubernetes Service (AKS)
This article describes core concepts of Azure Kubernetes Service (AKS), a managed Kubernetes service that you can use to deploy and operate containerized applications at scale on Azure.
What is Kubernetes?
Kubernetes is an open-source container orchestration platform for automating the deployment, scaling, and management of containerized applications. For more information, see the official Kubernetes documentation.
What is AKS?
AKS is a managed Kubernetes service that simplifies deploying, managing, and scaling containerized applications using Kubernetes. For more information, see What is Azure Kubernetes Service (AKS)?
Cluster components
An AKS cluster is divided into two main components:
- Control plane: The control plane provides the core Kubernetes services and orchestration of application workloads.
- Nodes: Nodes are the underlying virtual machines (VMs) that run your applications.
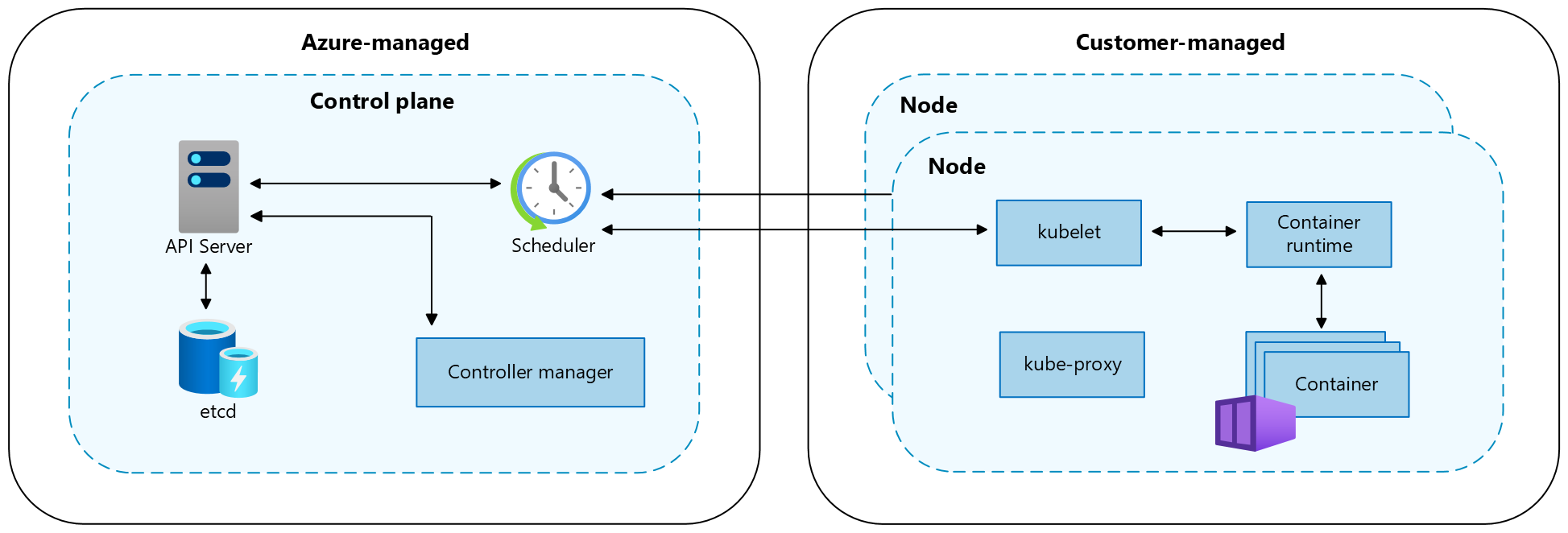
Control plane
The Azure managed control plane is comprised of several components that help manage the cluster:
| Component | Description |
|---|---|
| kube-apiserver | The API server (kube-apiserver) exposes the Kubernetes API to enable requests to the cluster from inside and outside of the cluster. |
| etcd | etcd is a highly available key-value store that helps maintain the state of your Kubernetes cluster and configuration. |
| kube-scheduler | The scheduler (kube-scheduler) helps make scheduling decisions, watching for new pods with no assigned node and selecting a node for them to run on. |
| kube-controller-manager | The controller manager (kube-controller-manager) runs controller processes, such as noticing and responding when nodes go down. |
| cloud-controller-manager | The cloud controller manager (cloud-controller-manager) embeds cloud-specific control logic to run controllers specific to the cloud provider. |
Nodes
Each AKS cluster has at least one node, which is an Azure virtual machine (VM) that runs Kubernetes node components. The following components run on each node:
| Component | Description |
|---|---|
| kubelet | The kubelet ensures that containers are running in a pod. |
| kube-proxy | The kube-proxy is a network proxy that maintains network rules on nodes. |
| container runtime | The container runtime manages the execution and lifecycle of containers. |
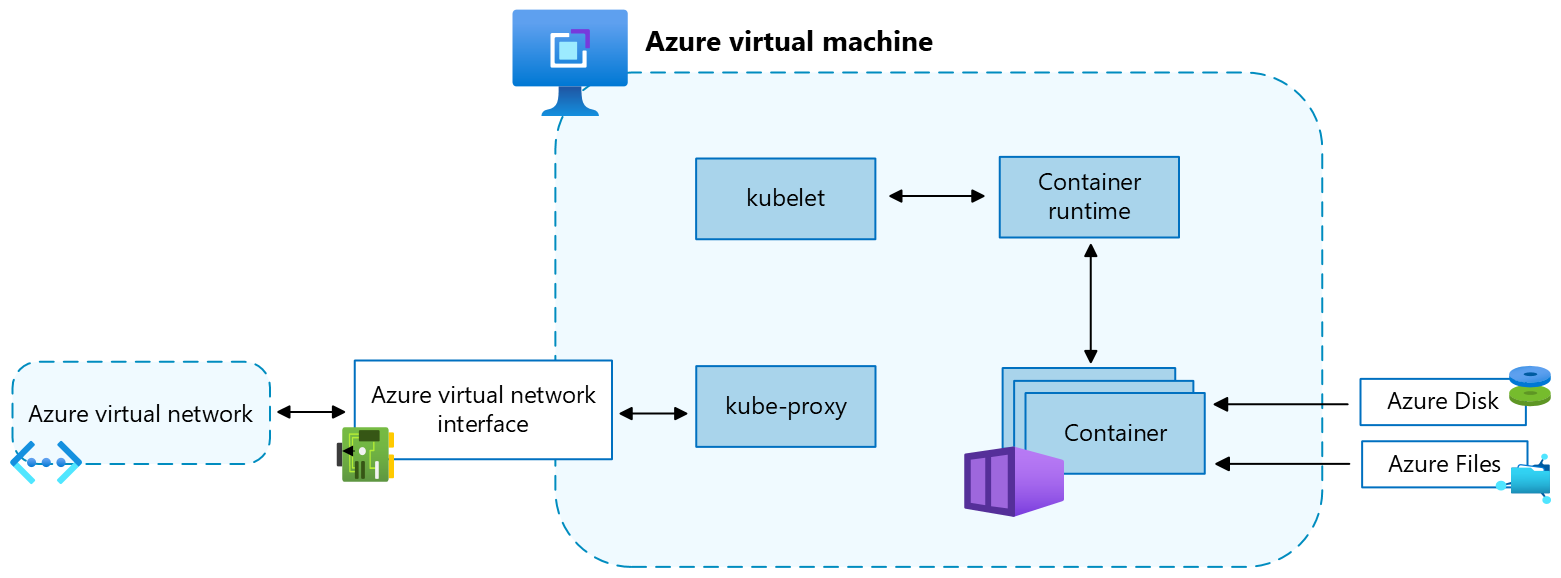
Node configuration
VM size and image
The Azure VM size for your nodes defines CPUs, memory, size, and the storage type available, such as high-performance SSD or regular HDD. The VM size you choose depends on the workload requirements and the number of pods you plan to run on each node. For more information, see Supported VM sizes in Azure Kubernetes Service (AKS).
In AKS, the VM image for your cluster's nodes is based on Ubuntu Linux, Azure Linux, or Windows Server 2022. When you create an AKS cluster or scale out the number of nodes, the Azure platform automatically creates and configures the requested number of VMs. Agent nodes are billed as standard VMs, so any VM size discounts, including Azure reservations, are automatically applied.
OS disks
Default OS disk sizing is only used on new clusters or node pools when Ephemeral OS disks aren't supported and a default OS disk size isn't specified. For more information, see Default OS disk sizing and Ephemeral OS disks.
Resource reservations
AKS uses node resources to help the nodes function as part of the cluster. This usage can cause a discrepancy between the node's total resources and the allocatable resources in AKS. To maintain node performance and functionality, AKS reserves two types of resources, CPU and memory, on each node. For more information, see Resource reservations in AKS.
OS
AKS supports Ubuntu 22.04 and Azure Linux 2.0 as the node OS for Linux node pools. For Windows node pools, AKS supports Windows Server 2022 as the default OS. Windows Server 2019 is being retired after Kubernetes version 1.32 reaches end of life and isn't supported in future releases. If you need to upgrade your Windows OS version, see Upgrade from Windows Server 2019 to Windows Server 2022. For more information on using Windows Server on AKS, see Windows container considerations in Azure Kubernetes Service (AKS).
Container runtime
A container runtime is software that executes containers and manages container images on a node. The runtime helps abstract away sys-calls or OS-specific functionality to run containers on Linux or Windows. For Linux node pools, containerd is used on Kubernetes version 1.19 and higher. For Windows Server 2019 and 2022 node pools, containerd is generally available and is the only runtime option on Kubernetes version 1.23 and higher.
Pods
A pod is a group of one or more containers that share the same network and storage resources and a specification for how to run the containers. Pods typically have a 1:1 mapping with a container, but you can run multiple containers in a pod.
Node pools
In AKS, nodes of the same configuration are grouped together into node pools. These node pools contain the underlying virtual machine scale sets and virtual machines (VMs) that run your applications. When you create an AKS cluster, you define the initial number of nodes and their size (SKU), which creates a system node pool. System node pools serve the primary purpose of hosting critical system pods, such as CoreDNS and konnectivity. To support applications that have different compute or storage demands, you can create user node pools. User node pools serve the primary purpose of hosting your application pods.
For more information, see Create node pools in AKS and Manage node pools in AKS.
Node resource group
When you create an AKS cluster in an Azure resource group, the AKS resource provider automatically creates a second resource group called the node resource group. This resource group contains all the infrastructure resources associated with the cluster, including virtual machines (VMs), virtual machine scale sets, and storage.
For more information, see the following resources:
- Why are two resource groups created with AKS?
- Can I provide my own name for the AKS node resource group?
- Can I modify tags and other properties of the resources in the AKS node resource group?
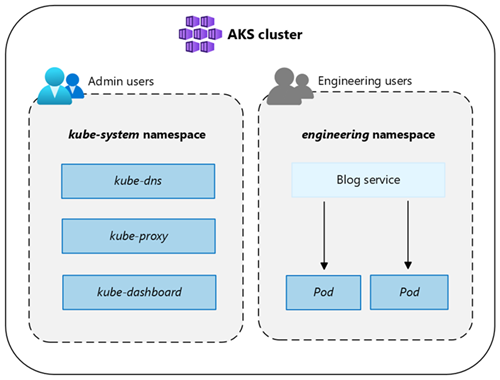
Namespaces
Kubernetes resources, such as pods and deployments, are logically grouped into namespaces to divide an AKS cluster and create, view, or manage access to resources.
The following namespaces are created by default in an AKS cluster:
| Namespace | Description |
|---|---|
| default | The default namespace allows you to start using cluster resources without creating a new namespace. |
| kube-node-lease | The kube-node-lease namespace enables nodes to communicate their availability to the control plane. |
| kube-public | The kube-public namespace isn't typically used, but can be used for resources to be visible across the whole cluster by any user. |
| kube-system | The kube-system namespace is used by Kubernetes to manage cluster resources, such as coredns, konnectivity-agent, and metrics-server. |
Cluster modes
In AKS, you can create a cluster with the Automatic (preview) or Standard mode. AKS Automatic provides a more fully managed experience, managing cluster configuration, including nodes, scaling, security, and other preconfigured settings. AKS Standard provides more control over the cluster configuration, including the ability to manage node pools, scaling, and other settings.
For more information, see AKS Automatic and Standard feature comparison.
Pricing tiers
AKS offers three pricing tiers for cluster management: Free, Standard, and Premium. The pricing tier you choose determines the features available for managing your cluster.
For more information, see Pricing tiers for AKS cluster management.
Supported Kubernetes versions
For more information, see Supported Kubernetes versions in AKS.
Next steps
For information on more core concepts for AKS, see the following resources:

Azure Kubernetes Service
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for