Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
Tip
Try out Data Factory in Microsoft Fabric, an all-in-one analytics solution for enterprises. Microsoft Fabric covers everything from data movement to data science, real-time analytics, business intelligence, and reporting. Learn how to start a new trial for free!
This article describes the storage event triggers that you can create in your Azure Data Factory or Azure Synapse Analytics pipelines.
Event-driven architecture is a common data integration pattern that involves production, detection, consumption, and reaction to events. Data integration scenarios often require customers to trigger pipelines that are triggered from events on an Azure Storage account, such as the arrival or deletion of a file in Azure Blob Storage account. Data Factory and Azure Synapse Analytics pipelines natively integrate with Azure Event Grid, which lets you trigger pipelines on such events.
Storage event trigger considerations
Consider the following points when you use storage event triggers:
- The integration described in this article depends on Azure Event Grid. Make sure that your subscription is registered with the Event Grid resource provider. For more information, see Resource providers and types. You must be able to do the
Microsoft.EventGrid/eventSubscriptions/action. This action is part of theEventGrid EventSubscription Contributorbuilt-in role. - If you're using this feature in Azure Synapse Analytics, ensure that you also register your subscription with the Data Factory resource provider. Otherwise, you get a message stating that "the creation of an Event Subscription failed."
- If the Blob Storage account resides behind a private endpoint and blocks public network access, you need to configure network rules to allow communications from Blob Storage to Event Grid. You can either grant storage access to trusted Azure services, such as Event Grid, following Storage documentation, or configure private endpoints for Event Grid that map to a virtual network address space, following Event Grid documentation.
- The storage event trigger currently supports only Azure Data Lake Storage Gen2 and General-purpose version 2 storage accounts. If you're working with Secure File Transfer Protocol (SFTP) storage events, you need to specify the SFTP Data API under the filtering section too. Because of an Event Grid limitation, Data Factory only supports a maximum of 500 storage event triggers per storage account.
- To create a new storage event trigger or modify an existing one, the Azure account you use to sign in to the service and publish the storage event trigger must have appropriate role-based access control (Azure RBAC) permission on the storage account. No other permissions are required. Service principal for the Azure Data Factory and Azure Synapse Analytics does not need special permission to either the storage account or Event Grid. For more information about access control, see the Role-based access control section.
- If you applied an Azure Resource Manager lock to your storage account, it might affect the blob trigger's ability to create or delete blobs. A
ReadOnlylock prevents both creation and deletion, while aDoNotDeletelock prevents deletion. Ensure that you account for these restrictions to avoid any issues with your triggers. - We don't recommend file arrival triggers as a triggering mechanism from data flow sinks. Data flows perform a number of file renaming and partition file shuffling tasks in the target folder that can inadvertently trigger a file arrival event before the complete processing of your data.
Create a trigger with the UI
This section shows you how to create a storage event trigger within the Azure Data Factory and Azure Synapse Analytics pipeline user interface (UI).
Switch to the Edit tab in Data Factory or the Integrate tab in Azure Synapse Analytics.
On the menu, select Trigger, and then select New/Edit.
On the Add Triggers page, select Choose trigger, and then select + New.
Select the trigger type Storage events.
Select your storage account from the Azure subscription dropdown list or manually by using its storage account resource ID. Choose the container on which you want the events to occur. Container selection is required, but selecting all containers can lead to a large number of events.
The
Blob path begins withandBlob path ends withproperties allow you to specify the containers, folders, and blob names for which you want to receive events. Your storage event trigger requires at least one of these properties to be defined. You can use various patterns for bothBlob path begins withandBlob path ends withproperties, as shown in the examples later in this article.Blob path begins with: The blob path must start with a folder path. Valid values include2018/and2018/april/shoes.csv. This field can't be selected if a container isn't selected.Blob path ends with: The blob path must end with a file name or extension. Valid values includeshoes.csvand.csv. Container and folder names, when specified, must be separated by a/blobs/segment. For example, a container namedorderscan have a value of/orders/blobs/2018/april/shoes.csv. To specify a folder in any container, omit the leading/character. For example,april/shoes.csvtriggers an event on any file namedshoes.csvin a folder calledaprilin any container.
Note that
Blob path begins withandBlob path ends withare the only pattern matching allowed in a storage event trigger. Other types of wildcard matching aren't supported for the trigger type.Select whether your trigger responds to a Blob created event, a Blob deleted event, or both. In your specified storage location, each event triggers the Data Factory and Azure Synapse Analytics pipelines associated with the trigger.
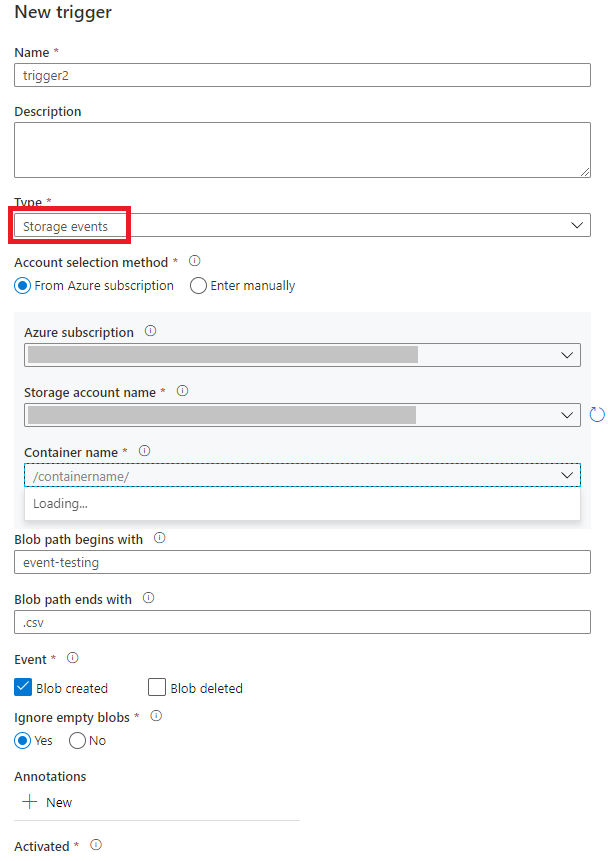
Select whether or not your trigger ignores blobs with zero bytes.
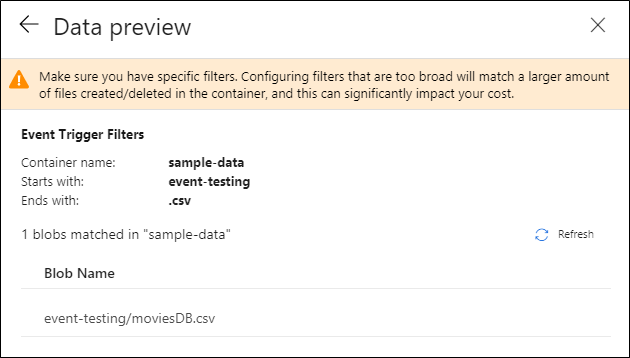
After you configure your trigger, select Next: Data preview. This screen shows the existing blobs matched by your storage event trigger configuration. Make sure you have specific filters. Configuring filters that are too broad can match a large number of files that were created or deleted and might significantly affect your cost. After your filter conditions are verified, select Finish.
To attach a pipeline to this trigger, go to the pipeline canvas and select Trigger > New/Edit. When the side pane appears, select the Choose trigger dropdown list and select the trigger you created. Select Next: Data preview to confirm that the configuration is correct. Then select Next to validate that the data preview is correct.
If your pipeline has parameters, you can specify them on the Trigger Run Parameters side pane. The storage event trigger captures the folder path and file name of the blob into the properties
@triggerBody().folderPathand@triggerBody().fileName. To use the values of these properties in a pipeline, you must map the properties to pipeline parameters. After you map the properties to parameters, you can access the values captured by the trigger through the@pipeline().parameters.parameterNameexpression throughout the pipeline. For a detailed explanation, see Reference trigger metadata in pipelines.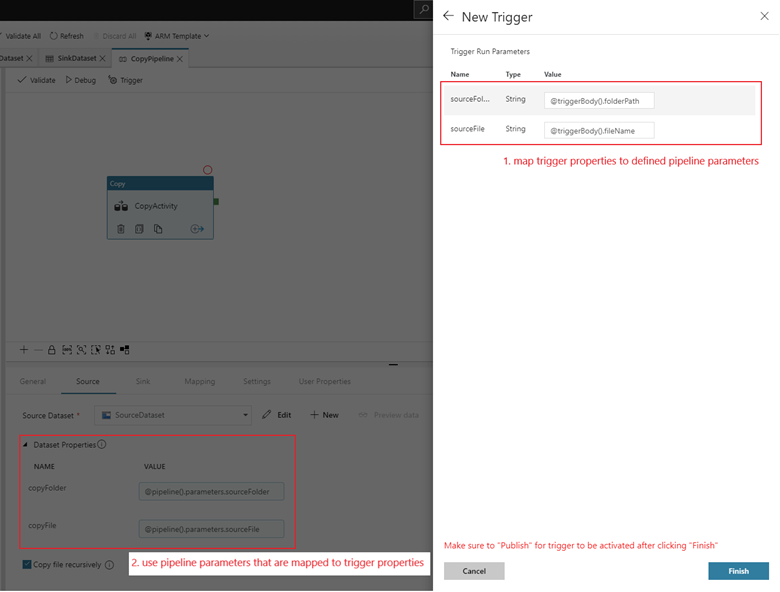
In the preceding example, the trigger is configured to fire when a blob path ending in .csv is created in the folder event-testing in the container sample-data. The
folderPathandfileNameproperties capture the location of the new blob. For example, when MoviesDB.csv is added to the path sample-data/event-testing,@triggerBody().folderPathhas a value ofsample-data/event-testingand@triggerBody().fileNamehas a value ofmoviesDB.csv. These values are mapped, in the example, to the pipeline parameterssourceFolderandsourceFile, which can be used throughout the pipeline as@pipeline().parameters.sourceFolderand@pipeline().parameters.sourceFile, respectively.After you're finished, select Finish.


JSON schema
The following table provides an overview of the schema elements that are related to storage event triggers.
| JSON element | Description | Type | Allowed values | Required |
|---|---|---|---|---|
| scope | The Azure Resource Manager resource ID of the storage account. | String | Azure Resource Manager ID | Yes. |
| events | The type of events that cause this trigger to fire. | Array | Microsoft.Storage.BlobCreated, Microsoft.Storage.BlobDeleted |
Yes, any combination of these values. |
blobPathBeginsWith |
The blob path must begin with the pattern provided for the trigger to fire. For example, /records/blobs/december/ only fires the trigger for blobs in the december folder under the records container. |
String | Provide a value for at least one of these properties: blobPathBeginsWith or blobPathEndsWith. |
|
blobPathEndsWith |
The blob path must end with the pattern provided for the trigger to fire. For example, december/boxes.csv only fires the trigger for blobs named boxes in a december folder. |
String | Provide a value for at least one of these properties: blobPathBeginsWith or blobPathEndsWith. |
|
ignoreEmptyBlobs |
Whether or not zero-byte blobs triggers a pipeline run. By default, this is set to true. |
Boolean | true or false | No. |
Examples of storage event triggers
This section provides examples of storage event trigger settings.
Important
You have to include the /blobs/ segment of the path, as shown in the following examples, whenever you specify container and folder, container and file, or container, folder, and file. For blobPathBeginsWith, the UI automatically adds /blobs/ between the folder and container name in the trigger JSON.
| Property | Example | Description |
|---|---|---|
Blob path begins with |
/containername/ |
Receives events for any blob in the container. |
Blob path begins with |
/containername/blobs/foldername/ |
Receives events for any blobs in the containername container and foldername folder. |
Blob path begins with |
/containername/blobs/foldername/subfoldername/ |
You can also reference a subfolder. |
Blob path begins with |
/containername/blobs/foldername/file.txt |
Receives events for a blob named file.txt in the foldername folder under the containername container. |
Blob path ends with |
file.txt |
Receives events for a blob named file.txt in any path. |
Blob path ends with |
/containername/blobs/file.txt |
Receives events for a blob named file.txt under the container containername. |
Blob path ends with |
foldername/file.txt |
Receives events for a blob named file.txt in the foldername folder under any container. |
Role-based access control
Data Factory and Azure Synapse Analytics pipelines use Azure role-based access control (Azure RBAC) to ensure that unauthorized access to listen to, subscribe to updates from, and trigger pipelines linked to blob events are strictly prohibited.
- To successfully create a new storage event trigger or update an existing one, the Azure account signed in to the service needs to have appropriate access to the relevant storage account. Otherwise, the operation fails with the message "Access Denied."
- Data Factory and Azure Synapse Analytics need no special permission to your Event Grid instance, and you do not need to assign special RBAC permission to the Data Factory or Azure Synapse Analytics service principal for the operation.
Any of the following RBAC settings work for storage event triggers:
- Owner role to the storage account
- Contributor role to the storage account
Microsoft.EventGrid/EventSubscriptions/Writepermission to the storage account/subscriptions/####/resourceGroups/####/providers/Microsoft.Storage/storageAccounts/storageAccountName
Specifically:
- When you author in the data factory (in the development environment for instance), the Azure account signed in needs to have the preceding permission.
- When you publish through continuous integration and continuous delivery, the account used to publish the Azure Resource Manager template into the testing or production factory needs to have the preceding permission.
To understand how the service delivers the two promises, let's take a step back and peek behind the scenes. Here are the high-level workflows for integration between Data Factory/Azure Synapse Analytics, Storage, and Event Grid.
Create a new storage event trigger
This high-level workflow describes how Data Factory interacts with Event Grid to create a storage event trigger. The data flow is the same in Azure Synapse Analytics, with Azure Synapse Analytics pipelines taking the role of the data factory in the following diagram.
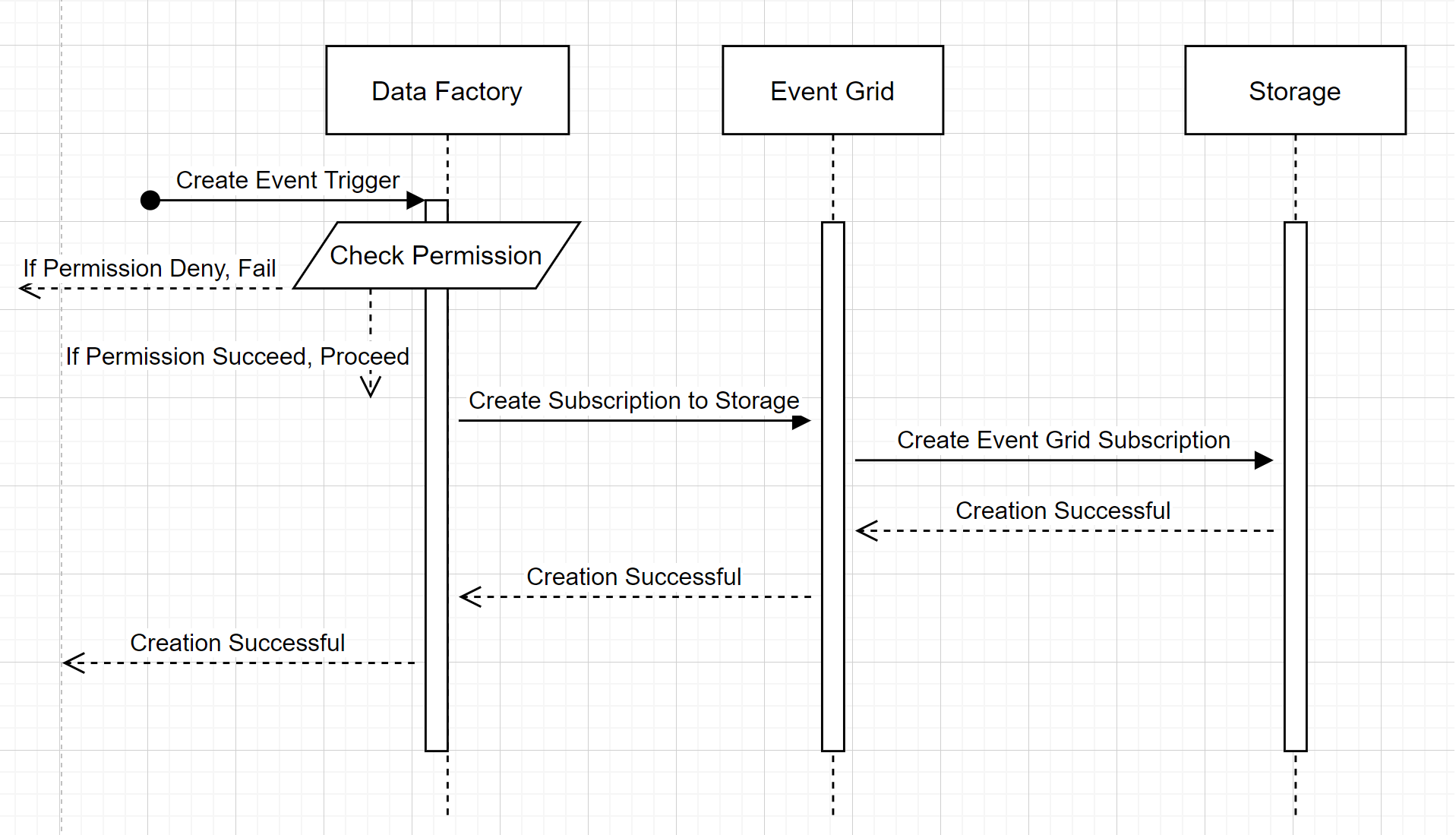
Two noticeable callouts from the workflows:
- Data Factory and Azure Synapse Analytics make no direct contact with the storage account. The request to create a subscription is instead relayed and processed by Event Grid. The service needs no permission to access the storage account for this step.
- Access control and permission checking happen within the service. Before the service sends a request to subscribe to a storage event, it checks the permission for the user. More specifically, it checks whether the Azure account that's signed in and attempting to create the storage event trigger has appropriate access to the relevant storage account. If the permission check fails, trigger creation also fails.
Storage event trigger pipeline run
This high-level workflow describes how storage event trigger pipelines run through Event Grid. For Azure Synapse Analytics, the data flow is the same, with Azure Synapse Analytics pipelines taking the role of Data Factory in the following diagram.
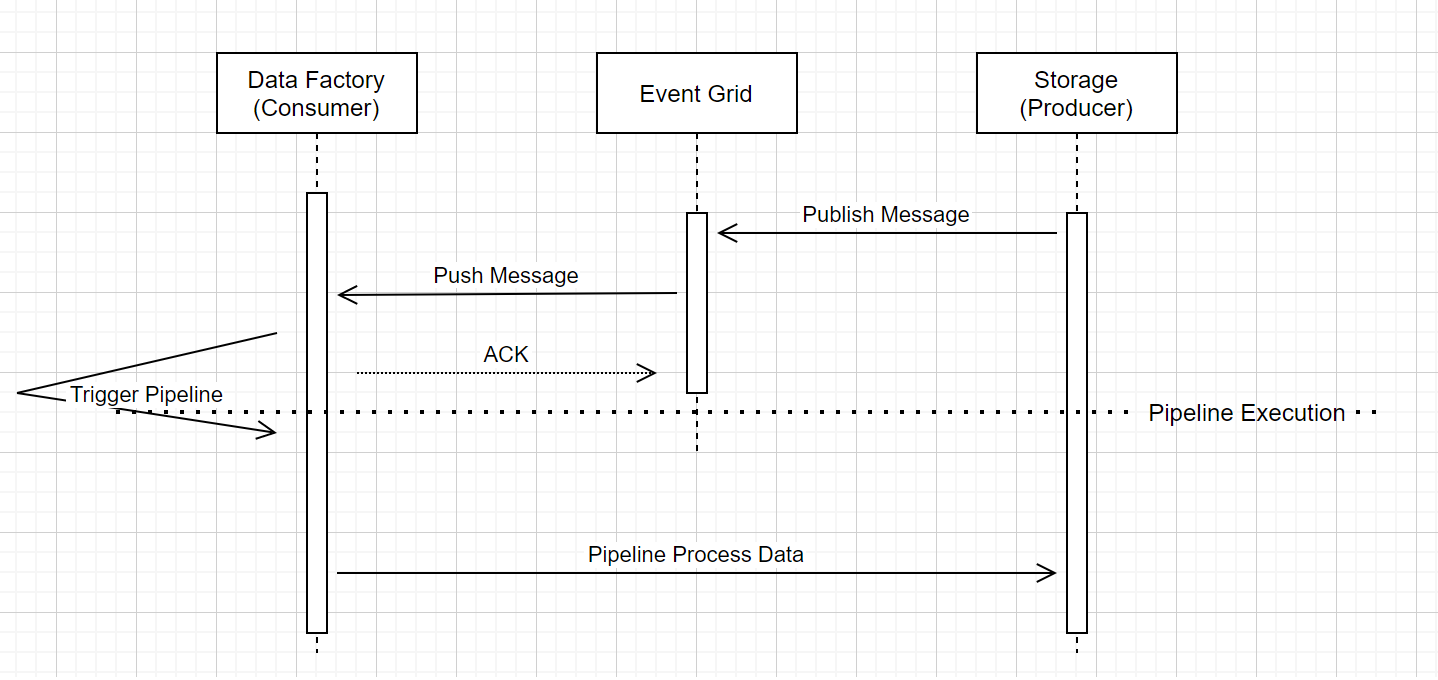
Three noticeable callouts in the workflow are related to event triggering pipelines within the service:
Event Grid uses a Push model that relays the message as soon as possible when storage drops the message into the system. This approach is different from a messaging system, such as Kafka, where a Pull system is used.
The event trigger serves as an active listener to the incoming message and it properly triggers the associated pipeline.
The storage event trigger itself makes no direct contact with the storage account.
- If you have a Copy activity or another activity inside the pipeline to process the data in the storage account, the service makes direct contact with the storage account by using the credentials stored in the linked service. Ensure that the linked service is set up appropriately.
- If you make no reference to the storage account in the pipeline, you don't need to grant permission to the service to access the storage account.
Related content
- For more information about triggers, see Pipeline execution and triggers.
- To reference trigger metadata in a pipeline, see Reference trigger metadata in pipeline runs.