SAP HANA availability within one Azure region
This article describes several availability scenarios for SAP HANA within one Azure region. Azure has many regions, spread throughout the world. For the list of Azure regions, see Azure regions. For deploying SAP HANA on VMs within one Azure region, Microsoft offers deployment of a single VM with a HANA instance. For increased availability, you can deploy two VMs with two HANA instances using either a flexible scale set with FD=1, availability zones or an availability set that uses HANA system replication for availability.
Azure regions that provide Availability Zones consist of multiple data centers, each with its own power source, cooling, and network infrastructure. The purpose of offering different zones within a single Azure region is to enable the deployment of applications across two or three available Availability Zones. By distributing your application deployment across zones, any power or networking issues affecting a specific Azure Availability Zone infrastructure wouldn't fully disrupt your application's functionality within the Azure region. While there might be some reduced capacity, such as the potential loss of VMs in one zone, the VMs in the remaining zones would continue to operate without interruption. To set up two HANA instances in separate VMs spanning across different zones, you have the option to deploy VMs using either the flexible scale set with FD=1 or availability zones deployment option.
For increased availability within a region, it's advised to deploy two VMs with two HANA instances using an availability set. An Azure Availability Set is a logical grouping capability that ensures that the VM resources configured within Availability Set are failure-isolated from each other when they're deployed within an Azure datacenter. Azure ensures that the VMs you place within an Availability Set run across multiple physical servers, compute racks, storage units, and network switches. In some Azure documentation, this configuration is referred to as placements in different update and fault domains. These placements usually are within an Azure datacenter. Assuming that power source and network issues would affect the datacenter that you're deploying, all your capacity in one Azure region would be affected.
The placement of datacenters that represent Azure Availability Zones is a compromise between delivering acceptable network latency between services deployed in different zones, and a distance between datacenters. Natural catastrophes ideally wouldn't affect the power, network supply, and infrastructure for all Availability Zones in this region. However, as monumental natural catastrophes have shown, Availability Zones might not always provide the availability that you want within one region. Think about Hurricane Maria that hit the island of Puerto Rico on September 20, 2017. The hurricane basically caused a nearly 100 percent blackout on the 90-mile-wide island.
Single-VM scenario
In a single-VM scenario, you create an Azure VM for the SAP HANA instance. You use Azure Premium Storage to host the operating system disk and all your data disks. The Azure uptime SLA of 99.9 percent and the SLAs of other Azure components is sufficient for you to fulfill your availability SLAs for your customers. In this scenario, you have no need to use an Azure Availability Set for VMs that run the DBMS layer. In this scenario, you rely on two different features:
- Azure VM auto restart (also referred to as Azure service healing)
- SAP HANA auto restart
Azure VM auto restart, or service healing, is a functionality in Azure that works on two levels:
- The Azure server host checks the health of a VM that's hosted on the server host.
- The Azure fabric controller monitors the health and availability of the server host.
A health check functionality monitors the health of every VM that's hosted on an Azure server host. If a VM falls into a non-healthy state, a reboot of the VM can be initiated by the Azure host agent that checks the health of the VM. The fabric controller checks the health of the host by checking many different parameters that might indicate issues with the host hardware. It also checks on the accessibility of the host via the network. An indication of problems with the host can lead to the following events:
- If the host signals a bad health state, a reboot of the host and a restart of the VMs that were running on the host is triggered.
- If the host isn't in a healthy state after successful reboot, a redeployment of the VMs that were originally on the now unhealthy node onto a healthy host server is initiated. In this case, the original host is marked as not healthy. It won't be used for further deployments until it's cleared or replaced.
- If the unhealthy host has problems during the reboot process, an immediate restart of the VMs on a healthy host is triggered.
With the host and VM monitoring provided by Azure, Azure VMs that experience host issues are automatically restarted on a healthy Azure host.
Important
Azure service healing will not restart Linux VMs where the guest OS is in a kernel panic state. The default settings of the commonly used Linux releases, are not automatically restarting VMs or server where the Linux kernel is in panic state. Instead the default foresees to keep the OS in kernel panic state to be able to attach a kernel debugger to analyze. Azure is honoring that behavior by not automatically restarting a VM with the guest OS in such a state. Assumption is that such occurrences are extremely rare. You could overwrite the default behavior to enable a restart of the VM. To change the default behavior enable the parameter 'kernel.panic' in /etc/sysctl.conf. The time you set for this parameter is in seconds. Common recommended values are to wait for 20-30 seconds before triggering the reboot through this parameter. For more information, see sysctl.conf.
The second feature that you rely on in this scenario is the fact that the HANA service that runs in a restarted VM starts automatically after the VM reboots. You can set up HANA service auto restart through the watchdog services of the various HANA services.
You might improve this single-VM scenario by adding a cold failover node to an SAP HANA configuration. In the SAP HANA documentation, this setup is called host autofailover. This configuration might make sense in an on-premises deployment situation where the server hardware is limited, and you dedicate a single-server node as the host autofailover node for a set of production hosts. But in Azure, where the underlying infrastructure of Azure provides a healthy target server for a successful VM restart, it doesn't make sense to deploy SAP HANA host autofailover. Because of Azure service healing, there's no reference architecture that foresees a standby node for HANA host autofailover.
Special case of SAP HANA scale-out configurations in Azure
High availability architectures based on standby node or HANA System Replication can be found in following documents. In cases where standby nodes or HANA system replication high availability isn't used in SAP HANA scale-out configurations, you can depend on Azure VMs' service healing capabilities and the automatic restart of the SAP HANA instance once the VM is operational again.
- RedHat Enterprise Linux
- SUSE Linux Enterprise Server
Availability scenarios for two different VMs
To ensure the availability of the HANA system within a specific region, you have the option to configure two VMs across the availability zones of the region or within the region. To achieve this objective, you can configure the VMs using flexible scale set, availability zones or availability set deployment option. The base setup in Azure would look like:
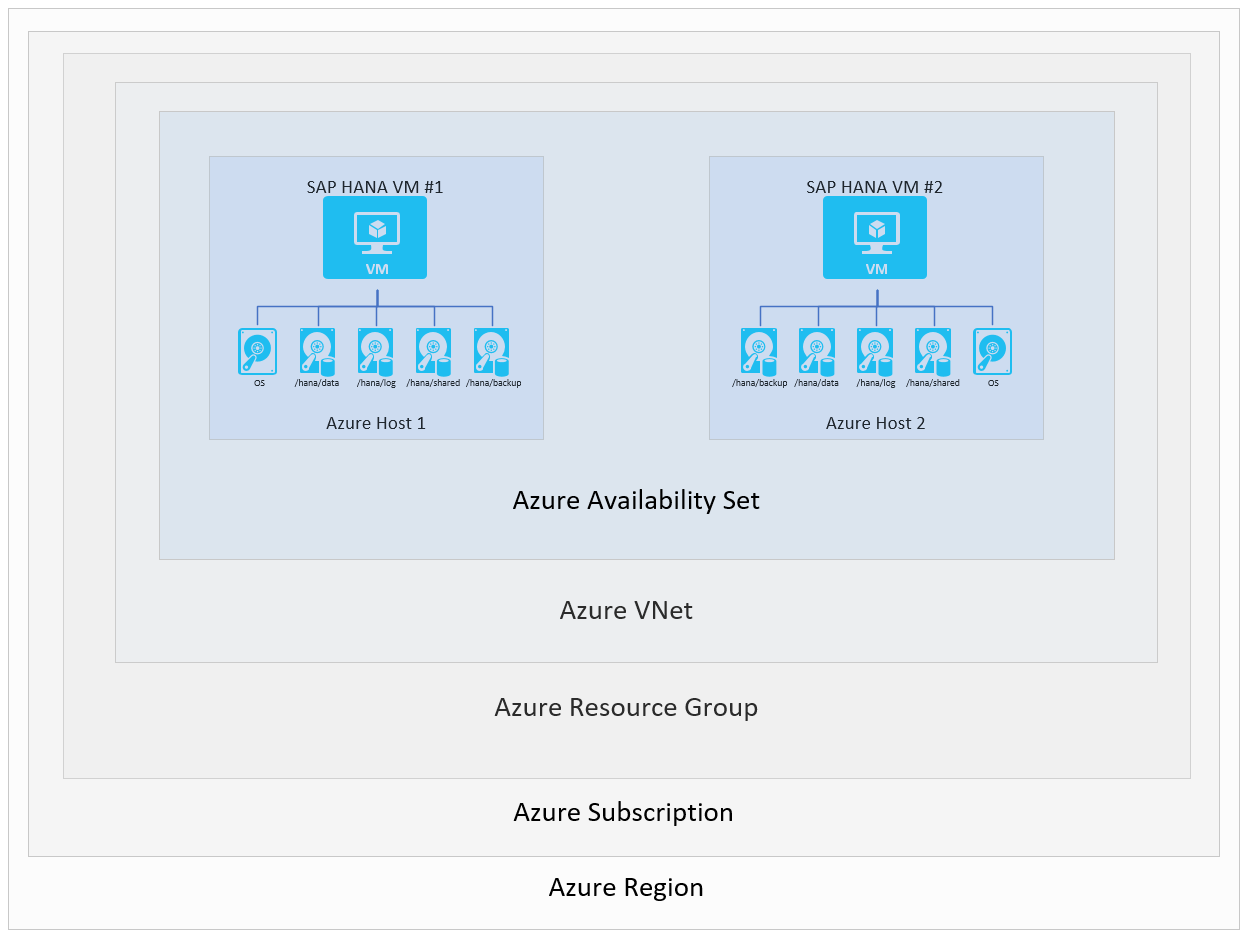
To illustrate the different SAP HANA availability scenarios, a few of the layers in the diagram are omitted. The diagram shows only layers that depict VMs, hosts, Availability Sets, and Azure regions. Azure Virtual Network instances, resource groups, and subscriptions don't play a role in the scenarios described in this section.
Replicate backups to a second virtual machine
One of the most rudimentary setups is to use backups. In particular, you might have transaction log backups shipped from one VM to another Azure VM. You can choose the Azure Storage type. In this setup, you're responsible for scripting the copy of scheduled backups that are conducted on the first VM to the second VM. If you need to use the second VM instances, you must restore the full, incremental/differential, and transaction log backups to the point that you need.
The architecture looks like:
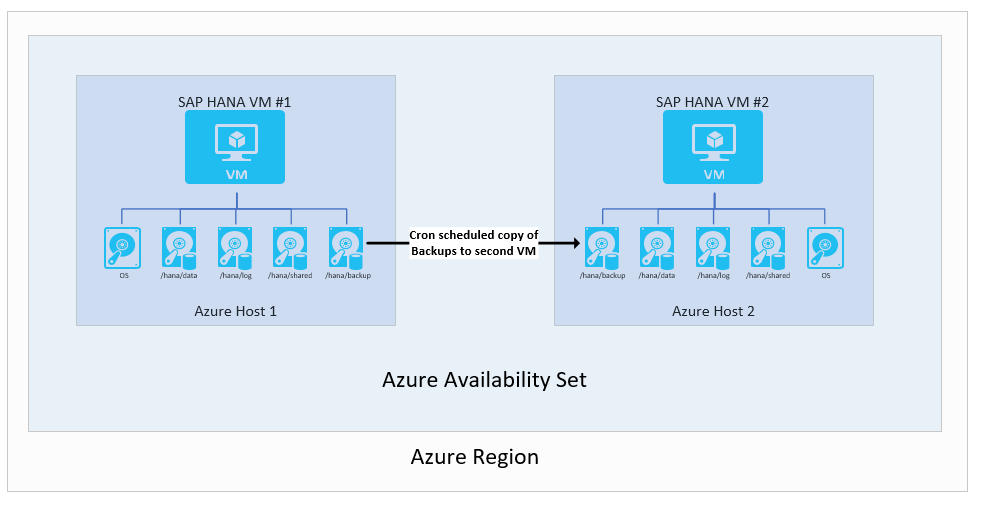
This setup isn't well suited to achieving great Recovery Point Objective (RPO) and Recovery Time Objective (RTO) times. RTO times especially would suffer due to the need to fully restore the complete database by using the copied backups. However, this setup is useful for recovering from unintended data deletion on the main instances. With this setup, at any time, you can restore to a certain point in time, extract the data, and import the deleted data into your main instance. Hence, it might make sense to use a backup copy method in combination with other high-availability functionality.
While backups are being copied, you might be able to use a smaller VM than the main VM that the SAP HANA instance is running on. Keep in mind that you can attach a smaller number of VHDs to smaller VMs. For information about the limits of individual VM types, see Sizes for Linux virtual machines in Azure.
SAP HANA system replication without automatic failover
The scenarios described in this section use SAP HANA system replication. For the SAP documentation, see System replication. Scenarios without automatic failover aren't common for configurations within one Azure region. A configuration without automatic failover, though avoiding a Pacemaker setup, obligates you to monitor and failover manually. Since this takes and efforts as well, most customers are relying on Azure service healing instead. There are some edge cases where this configuration might help in terms of failure scenarios. Or, in some cases, a customer might want to realize more efficiency.
SAP HANA system replication without auto failover and without data preload
In this scenario, you use SAP HANA system replication to move data in a synchronous manner to achieve an RPO of 0. On the other hand, you have a long enough RTO that you don't need either failover or data preloading into the HANA instance cache. In this case, it's possible to achieve further economy in your configuration by taking the following actions:
- Run another SAP HANA instance in the second VM. The SAP HANA instance in the second VM takes most of the memory of the virtual machine. In case a failover to the second VM, you need to shut down the running SAP HANA instance that has the data fully loaded in the second VM, so that the replicated data can be loaded into the cache of the targeted HANA instance in the second VM.
- Use a smaller VM size on the second VM. If a failover occurs, you have an additional step before the manual failover. In this step, you resize the VM to the size of the source VM.
The scenario looks like:
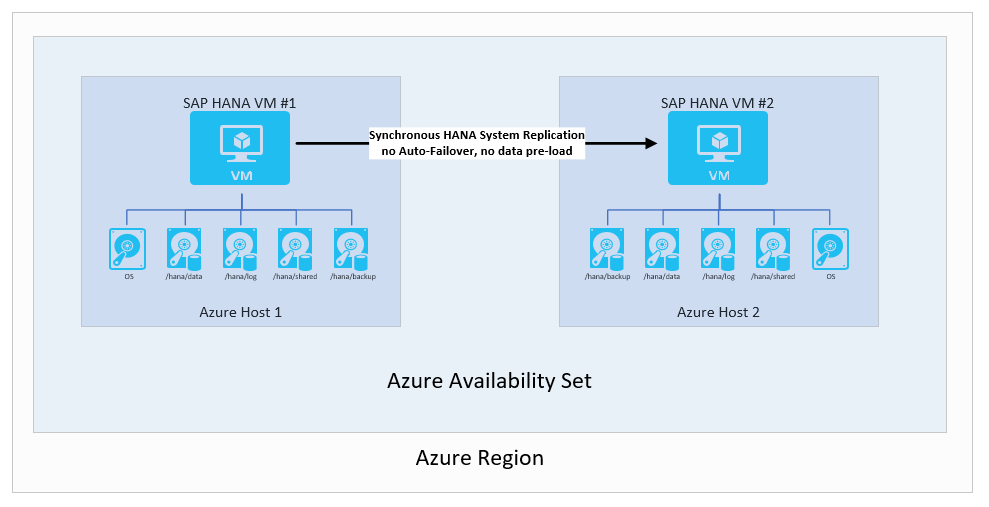
Note
Even if you don't use data preload in the HANA system replication target, you need at least 64 GB of memory. You also need enough memory in addition to 64 GB to keep the rowstore data in the memory of the target instance.
SAP HANA system replication without auto failover and with data preload
In this scenario, data that's replicated to the HANA instance in the second VM is preloaded. This eliminates the two advantages of not preloading data. In this case, you can't run another SAP HANA system on the second VM. You also can't use a smaller VM size. Hence, customers rarely implement this scenario.
SAP HANA system replication with automatic failover
In the standard and most common availability configuration within one Azure region, two Azure VMs running Linux with HA packages have a failover cluster defined. The HA Linux cluster is based on the Pacemaker framework using SLES or RHEL with a fencing device SLES or RHEL as an example.
From an SAP HANA perspective, the replication mode that's used is synced and an automatic failover is configured. In the second VM, the SAP HANA instance acts as a hot standby node. The standby node receives a synchronous stream of change records from the primary SAP HANA instance. As transactions are committed by the application at the HANA primary node, the primary HANA node waits to confirm the commit to the application until the secondary SAP HANA node confirms that it received the commit record. SAP HANA offers two synchronous replication modes. For details and for a description of differences between these two synchronous replication modes, see the SAP article Replication modes for SAP HANA system replication.
The overall configuration looks like:
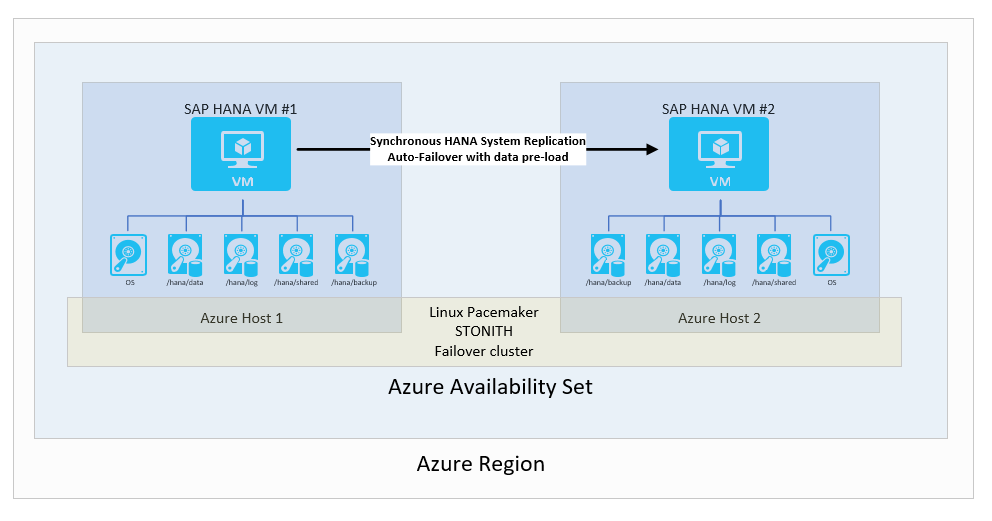
You might choose this solution because it enables you to achieve an RPO=0 and a low RTO. Configure the SAP HANA client connectivity so that the SAP HANA clients use the virtual IP address to connect to the HANA system replication configuration. Such a configuration eliminates the need to reconfigure the application if a failover to the secondary node occurs. In this scenario, the Azure VM SKUs for the primary and secondary VMs must be the same.
Next steps
For step-by-step guidance on setting up these configurations in Azure, see:
- Set up SAP HANA system replication in Azure VMs
- High availability for SAP HANA by using system replication
For more information about SAP HANA availability across Azure regions, see:
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for