Ingest data into OneLake and analyze with Azure Databricks
In this guide, you will:
Create a pipeline in a workspace and ingest data into your OneLake in Delta format.
Read and modify a Delta table in OneLake with Azure Databricks.
Prerequisites
Before you start, you must have:
A workspace with a Lakehouse item.
A premium Azure Databricks workspace. Only premium Azure Databricks workspaces support Microsoft Entra credential passthrough. When creating your cluster, enable Azure Data Lake Storage credential passthrough in the Advanced Options.
A sample dataset.
Ingest data and modify the Delta table
Navigate to your lakehouse in the Power BI service and select Get data and then select New data pipeline.
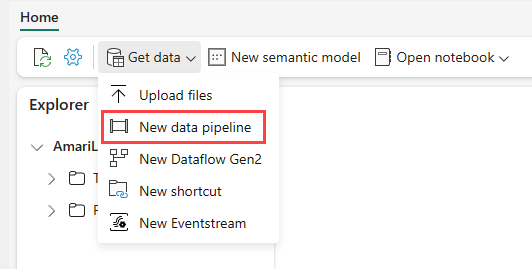
In the New Pipeline prompt, enter a name for the new pipeline and then select Create.
For this exercise, select the NYC Taxi - Green sample data as the data source and then select Next.
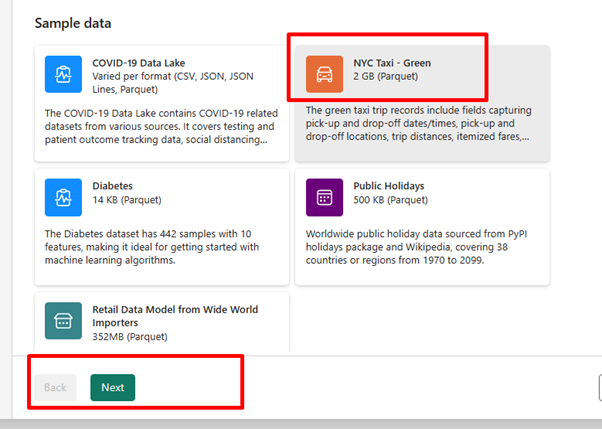
On the preview screen, select Next.
For data destination, select the name of the lakehouse you want to use to store the OneLake Delta table data. You can choose an existing lakehouse or create a new one.
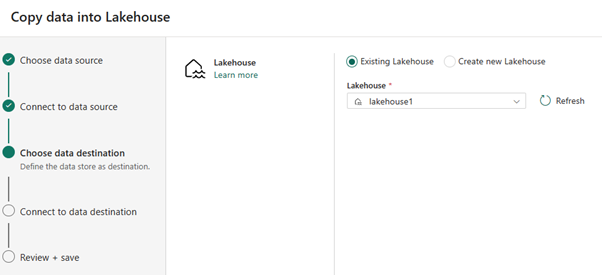
Select where you want to store the output. Choose Tables as the Root folder and enter "nycsample" as the table name.
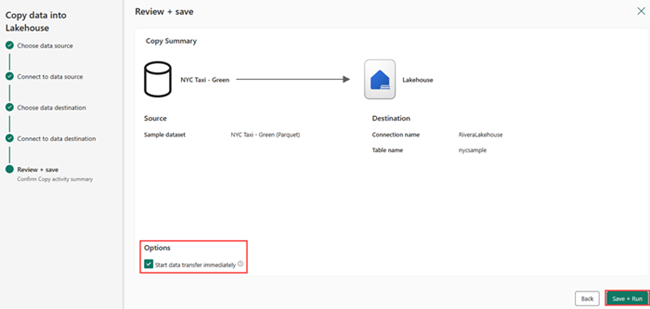
On the Review + Save screen, select Start data transfer immediately and then select Save + Run.
When the job is complete, navigate to your lakehouse and view the delta table listed under /Tables folder.
Right-click on the created table name, select Properties, and copy the Azure Blob Filesystem (ABFS) path.
Open your Azure Databricks notebook. Read the Delta table on OneLake.
olsPath = "abfss://<replace with workspace name>@onelake.dfs.fabric.microsoft.com/<replace with item name>.Lakehouse/Tables/nycsample" df=spark.read.format('delta').option("inferSchema","true").load(olsPath) df.show(5)Update the Delta table data by changing a field value.
%sql update delta.`abfss://<replace with workspace name>@onelake.dfs.fabric.microsoft.com/<replace with item name>.Lakehouse/Tables/nycsample` set vendorID = 99999 where vendorID = 1;