Azure Data Lake Storage
An Azure service that provides an enterprise-wide hyper-scale repository for big data analytic workloads and is integrated with Azure Blob Storage.
1,559 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EPM%3C/text%3E%3C/svg%3E)
I have two ADLSv2 storage accounts, both are hierarchical namespace enabled. In my Python Notebook, I'm reading a CSV file from one storage account and writing as parquet file in another storage, after some enrichment.
I am getting below error when writing the parquet file...
StatusCode=400
StatusDescription=An HTTP header that's mandatory for this request is not specified.
ErrorCode=
ErrorMessage=
Any help is greatly appreciated.
Below is my Notebook code snippet...
# Databricks notebook source
# MAGIC %python
# MAGIC
# MAGIC STAGING_MOUNTPOINT = "/mnt/inputfiles"
# MAGIC if STAGING_MOUNTPOINT in [mnt.mountPoint for mnt in dbutils.fs.mounts()]:
# MAGIC dbutils.fs.unmount(STAGING_MOUNTPOINT)
# MAGIC
# MAGIC PERM_MOUNTPOINT = "/mnt/outputfiles"
# MAGIC if PERM_MOUNTPOINT in [mnt.mountPoint for mnt in dbutils.fs.mounts()]:
# MAGIC dbutils.fs.unmount(PERM_MOUNTPOINT)
STAGING_STORAGE_ACCOUNT = "--------"
STAGING_CONTAINER = "--------"
STAGING_FOLDER = --------"
PERM_STORAGE_ACCOUNT = "--------"
PERM_CONTAINER = "--------"
configs = {
"fs.azure.account.auth.type": "OAuth",
"fs.azure.account.oauth.provider.type":
"org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider",
"fs.azure.account.oauth2.client.id": "#####################",
"fs.azure.account.oauth2.client.secret": dbutils.secrets.get(scope="DemoScope",key="DemoSecret"),
"fs.azure.account.oauth2.client.endpoint":
"https://login.microsoftonline.com/**********************/oauth2/token"}
STAGING_SOURCE =
"abfss://{container}@{storage_acct}.blob.core.windows.net/".format(container=STAGING_CONTAINER,
storage_acct=STAGING_STORAGE_ACCOUNT)
try:
dbutils.fs.mount(
source=STAGING_SOURCE,
mount_point=STAGING_MOUNTPOINT,
extra_configs=configs)
except Exception as e:
if "Directory already mounted" in str(e):
pass # Ignore error if already mounted.
else:
raise e
print("Staging Storage mount Success.")
inputDemoFile = "{}/{}/demo.csv".format(STAGING_MOUNTPOINT, STAGING_FOLDER)
readDF = (spark
.read.option("header", True)
.schema(inputSchema)
.option("inferSchema", True)
.csv(inputDemoFile))
LANDING_SOURCE =
"abfss://{container}@{storage_acct}.blob.core.windows.net/".format(container=LANDING_CONTAINER,
storage_acct=PERM_STORAGE_ACCOUNT)
try:
dbutils.fs.mount(
source=PERM_SOURCE,
mount_point=PERM_MOUNTPOINT,
extra_configs=configs)
except Exception as e:
if "Directory already mounted" in str(e):
pass # Ignore error if already mounted.
else:
raise e
print("Landing Storage mount Success.")
ENTITY_NAME="Demo"
outFilePath = "{}/output/{}/{:04d}/{:02d}/{:02d}/{:02d}".format(PERM_MOUNTPOINT, ENTITY_NAME, today.year, today.month, today.day, today.hour)
outFile= "{}/demo.parquet".format(outFilePath)
print("Writing to parquet file: " + outFile)
***Below call is failing…error is
StatusCode=400
StatusDescription=An HTTP header that's mandatory for this request is not specified.
ErrorCode=
ErrorMessage=***
(readDF
.coalesce(1)
.write
.mode("overwrite")
.option("header", "true")
.option("compression", "snappy")
.parquet(outFile)
)

Hello @Porsche Me ,
Couple of important points to note while mounting Storage accounts in Azure Databricks.
For Azure Blob storage:
source = "wasbs://<container-name>@<storage-account-name>.blob.core.windows.net/<directory-name>"For Azure Data Lake Storage gen2:
source = "abfss://<file-system-name>@<storage-account-name>.dfs.core.windows.net/"
To mount an Azure Data Lake Storage Gen2 filesystem or a folder inside it as Azure Databricks file system, the URL should be like abfss://<file-system-name>@<storage-account-name>.dfs.core.windows.net/
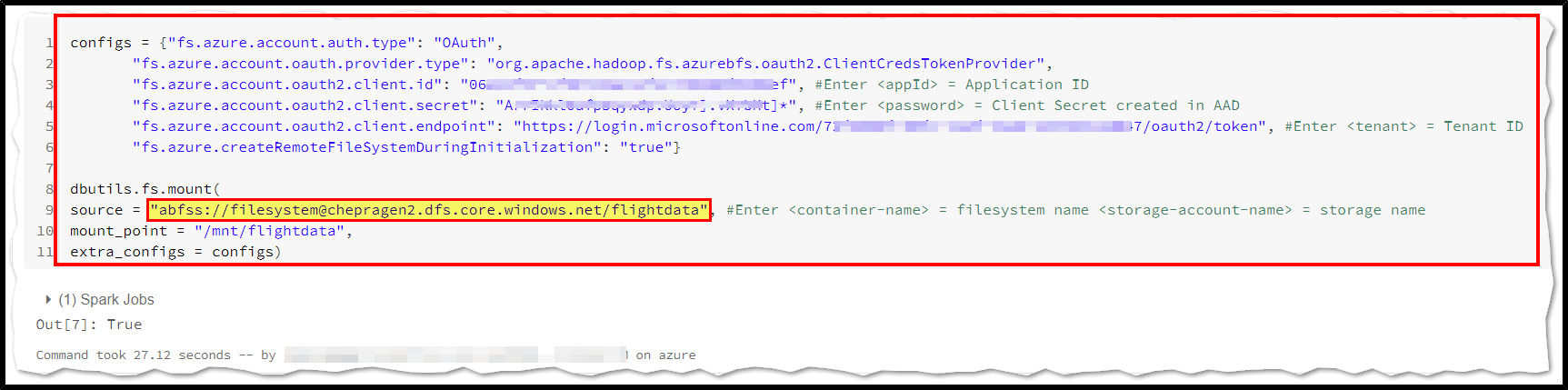
Reference: Azure Databricks - Azure Data Lake Storage Gen2
Hope this helps. Do let us know if you any further queries.
Do click on "Accept Answer" and Upvote on the post that helps you, this can be beneficial to other community members.