Document Intelligence ID document model
Important
- Document Intelligence public preview releases provide early access to features that are in active development. Features, approaches, and processes may change, prior to General Availability (GA), based on user feedback.
- The public preview version of Document Intelligence client libraries default to REST API version 2024-07-31-preview.
- Public preview version 2024-07-31-preview is currently only available in the following Azure regions. Note that the custom generative (document field extraction) model in AI Studio is only available in North Central US region:
- East US
- West US2
- West Europe
- North Central US
This content applies to: ![]() v4.0 (preview) | Previous versions:
v4.0 (preview) | Previous versions: ![]() v3.1 (GA)
v3.1 (GA) ![]() v3.0 (GA)
v3.0 (GA) ![]() v2.1 (GA)
v2.1 (GA)
This content applies to: ![]() v3.1 (GA) | Latest version:
v3.1 (GA) | Latest version: ![]() v4.0 (preview) | Previous versions:
v4.0 (preview) | Previous versions: ![]() v3.0
v3.0 ![]() v2.1
v2.1
This content applies to: ![]() v3.0 (GA) | Latest versions:
v3.0 (GA) | Latest versions: ![]() v4.0 (preview)
v4.0 (preview) ![]() v3.1 | Previous version:
v3.1 | Previous version: ![]() v2.1
v2.1
This content applies to: ![]() v2.1 | Latest version:
v2.1 | Latest version: ![]() v4.0 (preview)
v4.0 (preview)
Document Intelligence Identity document (ID) model combines Optical Character Recognition (OCR) with deep learning models to analyze and extract key information from identity documents. The API analyzes identity documents (including the following) and returns a structured JSON data representation:
- Passport book, passport card worldwide
- Driver's license from United States, Europe, India, Canada, and Australia
- United States identification cards, residency permit (green card), social security card, military ID
- European identification cards, residency permits
- India PAN card, Aadhaar card
- Canada identification cards, residency permit (maple card)
- Australia photo card, key-pass ID (including digital version)
Document Intelligence can analyze and extract information from government-issued identification documents (IDs) using its prebuilt IDs model. It combines our powerful Optical Character Recognition (OCR) capabilities with ID recognition capabilities to extract key information from Worldwide Passports and U.S. Driver's Licenses (all 50 states and D.C.). The IDs API extracts key information from these identity documents, such as first name, surname, date of birth, document number, and more. This API is available in the Document Intelligence v2.1 as a cloud service.
Identity document processing
Identity document processing involves extracting data from identity documents either manually or by using OCR-based technology. ID document processing is an important step in any business operation that requires proof of identity. Examples include customer verification in banks and other financial institutions, mortgage applications, medical visits, claim processing, hospitality industry, and more. Individuals provide some proof of their identity via driver licenses, passports, and other similar documents so that the business can efficiently verify them before providing services and benefits.
Sample U.S. Driver's License processed with Document Intelligence Studio
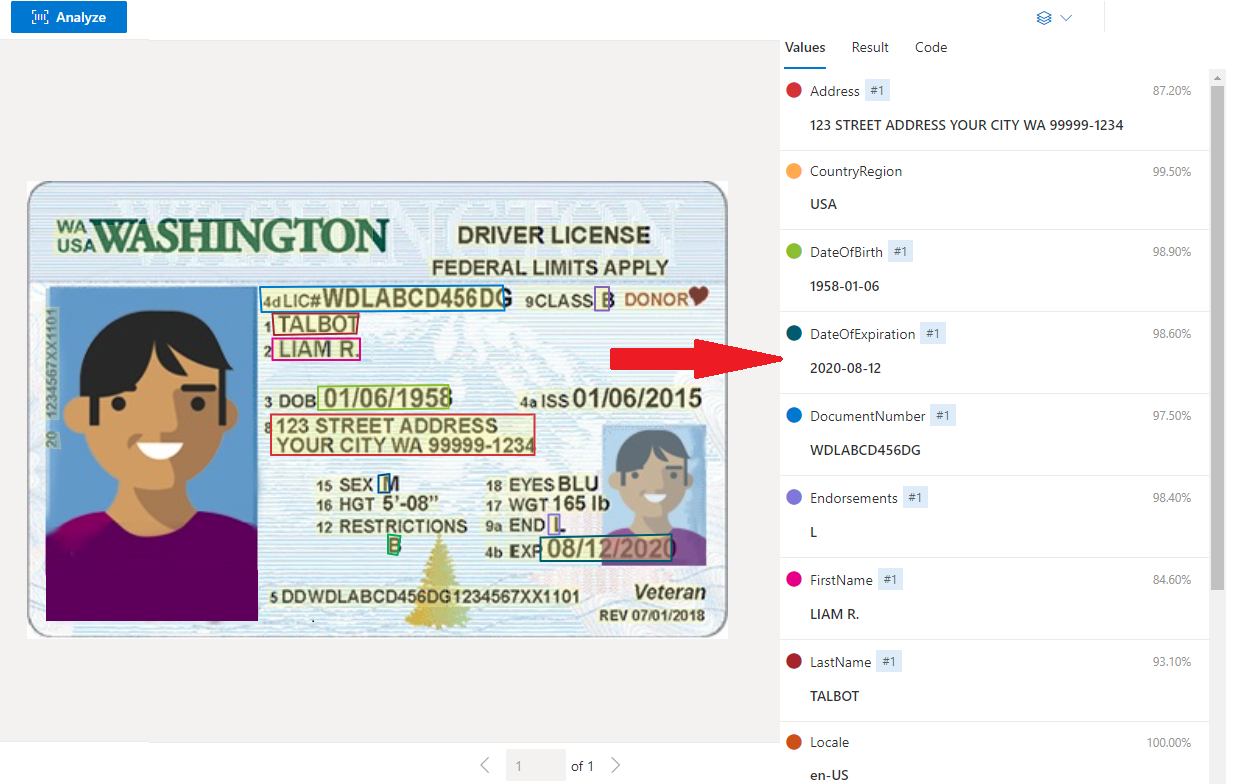
Data extraction
The prebuilt IDs service extracts the key values from worldwide passports and U.S. Driver's Licenses and returns them in an organized structured JSON response.
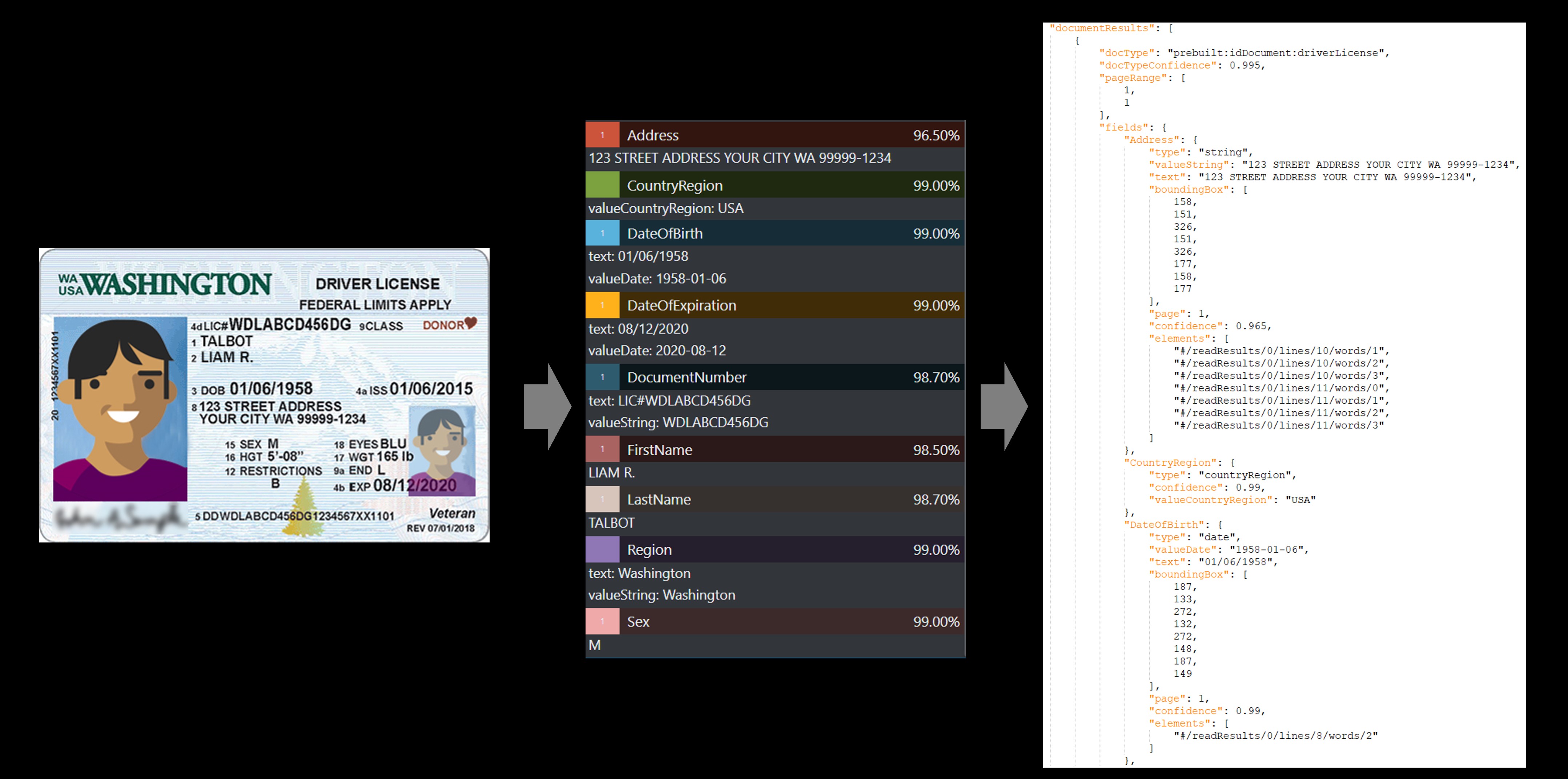
Driver's license example
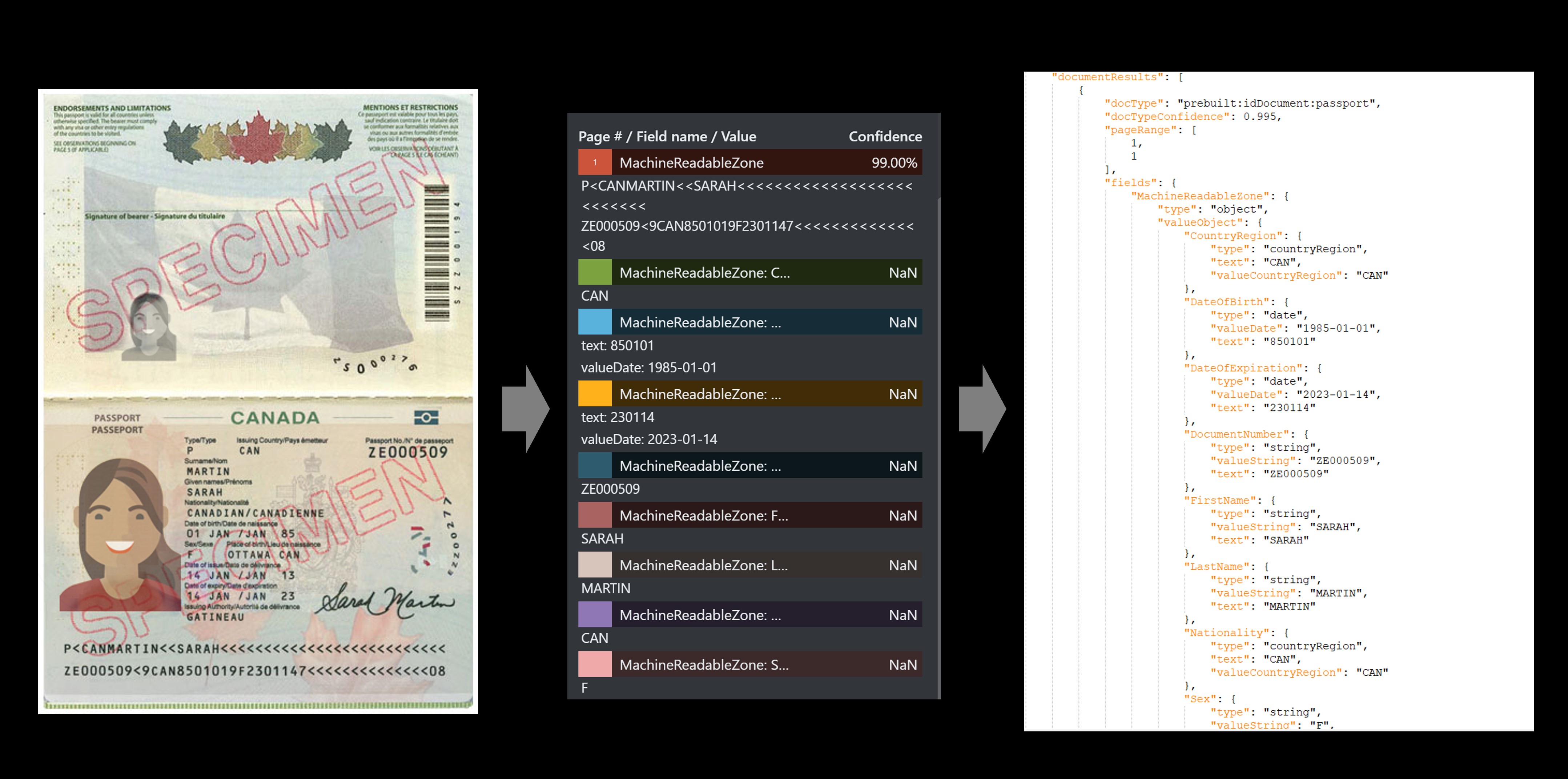
Passport example
Development options
Document Intelligence v4.0 (2024-07-31-preview) supports the following tools, applications, and libraries:
| Feature | Resources | Model ID |
|---|---|---|
| ID document model | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-idDocument |
Document Intelligence v3.1 supports the following tools, applications, and libraries:
| Feature | Resources | Model ID |
|---|---|---|
| ID document model | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-idDocument |
Document Intelligence v3.0 supports the following tools, applications, and libraries:
| Feature | Resources | Model ID |
|---|---|---|
| ID document model | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-idDocument |
Document Intelligence v2.1 supports the following tools, applications, and libraries:
| Feature | Resources |
|---|---|
| ID document model | • Document Intelligence labeling tool • REST API • Client-library SDK • Document Intelligence Docker container |
Input requirements
Supported file formats:
Model PDF Image: JPEG/JPG,PNG,BMP,TIFF,HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLRead ✔ ✔ ✔ Layout ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview, 2023-10-31-preview) General Document ✔ ✔ Prebuilt ✔ ✔ Custom extraction ✔ ✔ Custom classification ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview) For best results, provide one clear photo or high-quality scan per document.
For PDF and TIFF, up to 2,000 pages can be processed (with a free tier subscription, only the first two pages are processed).
The file size for analyzing documents is 500 MB for paid (S0) tier and
4MB for free (F0) tier.Image dimensions must be between 50 pixels x 50 pixels and 10,000 pixels x 10,000 pixels.
If your PDFs are password-locked, you must remove the lock before submission.
The minimum height of the text to be extracted is 12 pixels for a 1024 x 768 pixel image. This dimension corresponds to about
8point text at 150 dots per inch (DPI).For custom model training, the maximum number of pages for training data is 500 for the custom template model and 50,000 for the custom neural model.
For custom extraction model training, the total size of training data is 50 MB for template model and
1GB for the neural model.For custom classification model training, the total size of training data is
1GB with a maximum of 10,000 pages. For 2024-07-31-preview and later, the total size of training data is2GB with a maximum of 10,000 pages.
Supported file formats: JPEG, PNG, PDF, and TIFF.
Supported number of pages for PDF and TIFF files: up to 2,000 pages or only the first two pages for free-tier subscribers.
Supported file size: less than 50 MB TOTAL; minimum pixels: 50 x 50 px; maximum pixels 10,000 x 10,000 px.
ID document model data extraction
Extract data, including name, birth date, and expiration date, from ID documents. You need the following resources:
An Azure subscription—you can create one for free.
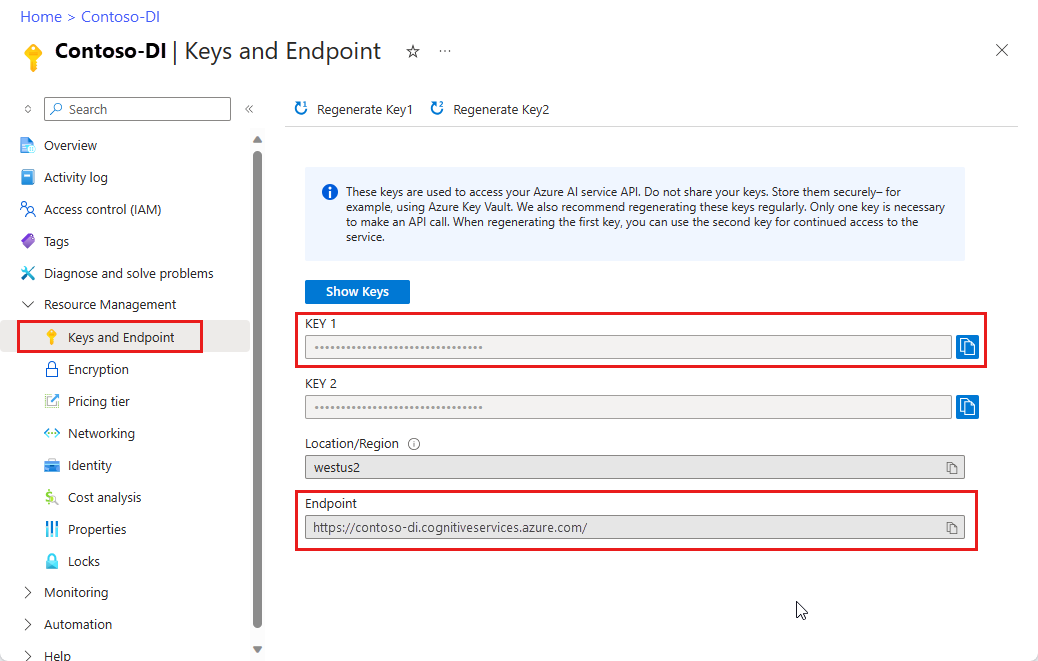
A Document Intelligence instance in the Azure portal. You can use the free pricing tier (
F0) to try the service. After your resource deploys, select Go to resource to get your key and endpoint.
Note
Document Intelligence Studio is available with v3.1 and v3.0 APIs and later versions.
On the Document Intelligence Studio home page, select Identity documents.
You can analyze the sample invoice or upload your own files.
Select the Run analysis button and, if necessary, configure the Analyze options:

Document Intelligence Sample Labeling tool
Navigate to the Document Intelligence Sample Tool.
On the sample tool home page, select the Use prebuilt model to get data tile.
Select the Form Type to analyze from the dropdown menu.
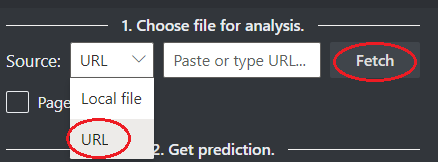
Choose a URL for the file you would like to analyze from the below options:
In the Source field, select URL from the dropdown menu, paste the selected URL, and select the Fetch button.
In the Document Intelligence service endpoint field, paste the endpoint that you obtained with your Document Intelligence subscription.
In the key field, paste the key you obtained from your Document Intelligence resource.
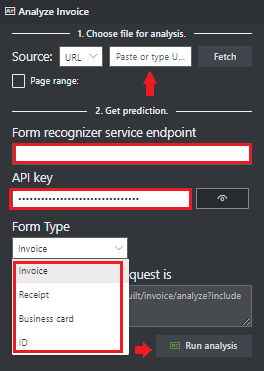
Select Run analysis. The Document Intelligence Sample Labeling tool calls the Analyze Prebuilt API and analyzes the document.
View the results - see the key-value pairs extracted, line items, highlighted text extracted, and tables detected.
Download the JSON output file to view the detailed results.
- The "readResults" node contains every line of text with its respective bounding box placement on the page.
- The "selectionMarks" node shows every selection mark (checkbox, radio mark) and whether its status is selected or unselected.
- The "pageResults" section includes the tables extracted. For each table, Document Intelligence extracts the text, row, and column index, row and column spanning, bounding box, and more.
- The "documentResults" field contains key/value pairs information and line items information for the most relevant parts of the document.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Note
The Sample Labeling tool does not support the BMP file format. This is a limitation of the tool not the Document Intelligence Service.
Supported document types
| Region | Document types |
|---|---|
| Worldwide | Passport Book, Passport Card |
| United States | Driver License, Identification Card, Residency Permit (Green card), Social Security Card, Military ID |
| Europe | Driver License, Identification Card, Residency Permit |
| India | Driver License, PAN Card, Aadhaar Card |
| Canada | Driver License, Identification Card, Residency Permit (Maple Card) |
| Australia | Driver License, Photo Card, Key-pass ID (including digital version) |
Field extractions
For supported document extraction fields, refer to the ID document model schema page in our GitHub sample repository.
Supported document types
The ID document model currently supports US driver licenses and the biographical page from international passports (excluding visa and other travel documents) extraction.
Fields extracted
| Name | Type | Description | Value |
|---|---|---|---|
| Country | country | Country code compliant with ISO 3166 standard | "USA" |
| DateOfBirth | date | DOB in YYYY-MM-DD format | "1980-01-01" |
| DateOfExpiration | date | Expiration date in YYYY-MM-DD format | "2019-05-05" |
| DocumentNumber | string | Relevant passport number, driver's license number, etc. | "340020013" |
| FirstName | string | Extracted given name and middle initial if applicable | "JENNIFER" |
| LastName | string | Extracted surname | "BROOKS" |
| Nationality | country | Country code compliant with ISO 3166 standard | "USA" |
| Sex | gender | Possible extracted values include "M" "F" "X" | "F" |
| MachineReadableZone | object | Extracted Passport MRZ including two lines of 44 characters each |
"P<USABROOKS<<JENNIFER<<<<<<<<<<<<<<<<<<<<<<< 3400200135USA8001014F1905054710000307<715816" |
| DocumentType | string | Document type, for example, Passport, Driver's License | "passport" |
| Address | string | Extracted address (Driver's License only) | "123 STREET ADDRESS YOUR CITY WA 99999-1234" |
| Region | string | Extracted region, state, province, etc. (Driver's License only) | "Washington" |
Migration guide
- Follow our Document Intelligence v3.1 migration guide to learn how to use the v3.0 version in your applications and workflows.
Next steps
Try processing your own forms and documents with the Document Intelligence Studio.
Complete a Document Intelligence quickstart and get started creating a document processing app in the development language of your choice.
Try processing your own forms and documents with the Document Intelligence Sample Labeling tool.
Complete a Document Intelligence quickstart and get started creating a document processing app in the development language of your choice.