Configure liveness probes
Containerized applications may run for extended periods of time, resulting in broken states that may need to be repaired by restarting the container. Azure Container Instances supports liveness probes so that you can configure your containers within your container group to restart if critical functionality isn't working. The liveness probe behaves like a Kubernetes liveness probe.
This article explains how to deploy a container group that includes a liveness probe, demonstrating the automatic restart of a simulated unhealthy container.
Azure Container Instances also supports readiness probes, which you can configure to ensure that traffic reaches a container only when it's ready for it.
YAML deployment
Create a liveness-probe.yaml file with the following snippet. This file defines a container group that consists of an NGINX container that eventually becomes unhealthy.
apiVersion: 2019-12-01
location: eastus
name: livenesstest
properties:
containers:
- name: mycontainer
properties:
image: mcr.microsoft.com/oss/nginx/nginx:1.15.5-alpine
command:
- "/bin/sh"
- "-c"
- "touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600"
ports: []
resources:
requests:
cpu: 1.0
memoryInGB: 1.5
livenessProbe:
exec:
command:
- "cat"
- "/tmp/healthy"
periodSeconds: 5
osType: Linux
restartPolicy: Always
tags: null
type: Microsoft.ContainerInstance/containerGroups
Run the following command to deploy this container group with the preceding YAML configuration:
az container create --resource-group myResourceGroup --name livenesstest -f liveness-probe.yaml
Start command
The deployment includes a command property defining a starting command that runs when the container first starts running. This property accepts an array of strings. This command simulates the container entering an unhealthy state.
First, it starts a bash session and creates a file called healthy within the /tmp directory. It then sleeps for 30 seconds before deleting the file, then enters a 10-minute sleep:
/bin/sh -c "touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600"
Liveness command
This deployment defines a livenessProbe that supports an exec liveness command that acts as the liveness check. If this command exits with a nonzero value, the container is killed and restarted, signaling the healthy file couldn't be found. If this command exits successfully with exit code 0, no action is taken.
The periodSeconds property designates the liveness command should execute every 5 seconds.
Verify liveness output
Within the first 30 seconds, the healthy file created by the start command exists. When the liveness command checks for the healthy file's existence, the status code returns 0, signaling success, so no restarting occurs.
After 30 seconds, the cat /tmp/healthy command begins to fail, causing unhealthy and killing events to occur.
These events can be viewed from the Azure portal or Azure CLI.
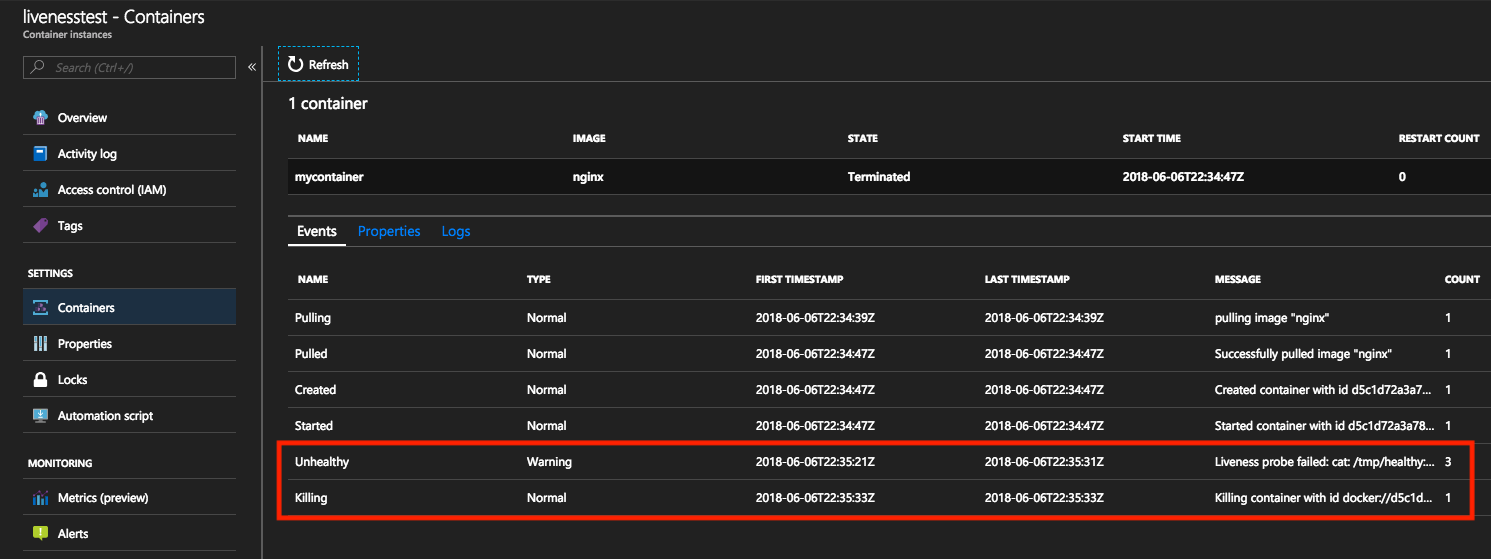
By viewing the events in the Azure portal, events of type Unhealthy are triggered upon the liveness command failing. The subsequent event is of type Killing, signifying a container deletion so a restart can begin. The restart count for the container increments each time this event occurs.
Restarts are completed in-place so resources like public IP addresses and node-specific contents are preserved.

If the liveness probe continuously fails and triggers too many restarts, your container enters an exponential back-off delay.
Liveness probes and restart policies
Restart policies supersede the restart behavior triggered by liveness probes. For example, if you set a restartPolicy = Never and a liveness probe, the container group won't restart because of a failed liveness check. The container group instead adheres to the container group's restart policy of Never.
Next steps
Task-based scenarios may require a liveness probe to enable automatic restarts if a prerequisite function isn't working properly. For more information about running task-based containers, see Run containerized tasks in Azure Container Instances.