Configuration options to minimize network latency with SAP applications
Important
In November 2021 we made significant changes in the way how proximity placement groups should be used with SAP workload in zonal deployments.
SAP applications based on the SAP NetWeaver or SAP S/4HANA architecture are sensitive to network latency between the SAP application tier and the SAP database tier. This sensitivity is the result of most of the business logic running in the application layer. Because the SAP application layer runs the business logic, it issues queries to the database tier at a high frequency, at a rate of thousands or tens of thousands per second. In most cases, the nature of these queries is simple. They can often be run on the database tier in 500 microseconds or less.
The time spent on the network to send such a query from the application tier to the database tier and receive the result sent back has a major impact on the time it takes to run business processes. This sensitivity to network latency is why you might want to achieve certain minimum network latency in SAP deployment projects. See SAP Note #1100926 - FAQ: Network performance for guidelines on how to classify the network latency.
In many Azure regions, the number of datacenters has grown. At the same time, customers, especially for high-end SAP systems, are using more special VM families like Mv2 or Mv3 family and newer. These Azure virtual machine types aren't always available in each of the datacenters that collect into an Azure region. These facts can create opportunities to optimize network latency between the SAP application layer and the SAP DBMS layer.
Azure provides different deployment options for SAP workloads. For the chosen deployment type you have options to optimize network latency, if needed. Detailed information about each option is thoroughly described in the following sections within this article:
Proximity Placement Groups
Proximity placement groups enable the grouping of different VM types under a single network spine, ensuring optimal low network latency between them. When the first VM is deployed in proximity placement group, that VM gets bound to a specific network spine. As all the other VMs that are going to be deployed into the same proximity placement group, those VMs get grouped under the same network spine. As appealing as this prospect sounds, the usage of the construct introduces some restrictions and pitfalls as well:
- You can't assume that all Azure VM types are available in every and all Azure datacenters or under each and every network spine. As a result, the combination of different VM types within one proximity placement group can be severely restricted. These restrictions occur because the host hardware that is needed to run a certain VM type might not be present in the datacenter or under the network spine to which the proximity placement group was assigned
- As you resize parts of the VMs that are within one proximity placement group, you can't automatically assume that in all cases the new VM type is available in the same datacenter or under the network spine the proximity placement group got assigned to
- As Azure decommissions hardware it might force certain VMs of a proximity placement group into another Azure datacenter or another network spine. For details covering this case, read the document Proximity placement groups
Important
As a result of the potential restrictions, proximity placement groups should be only used:
- When necessary in certain scenarios (see later)
- When the network latency between application layer and DBMS layer is too high and impacts the workload
- Only on granularity of a single SAP system and not for a whole system landscape or a complete SAP landscape
- In a way to keep the different VM types and the number of VMs within a proximity placement group to a minimum
The scenarios where proximity placement groups can be used to optimize network latency:
- You want to deploy the critical resources of your SAP workload across different availability zones and on the other hand need VMs of the application tier to be spread across different fault domains by using availability sets in each of the zones. In this case, as later described in the document, proximity placement groups are the glue needed.
- You deploy the SAP workload with availability sets. Where the SAP database tier, the SAP application tier and ASCS/SCS VMs are grouped in three different availability sets. In such a case, you want to make sure that the availability sets aren't spread across the complete Azure region since this could, dependent on the Azure region, result in network latency that could impact SAP workload negatively.
- You use proximity placement groups to group VMs together to achieve lowest possible network latency between the services hosted in the VMs. For example, latency within an availability zone alone does not meet the application requirements.
As for deployment scenario #2, in many regions, especially regions without availability zones and most regions with availability zones, the network latency independent on where the VMs land is acceptable. Though there are some regions of Azure that can't provide a sufficiently good experience without collocating the three different availability sets without the usage of proximity placement groups.
What are proximity placement groups?
An Azure proximity placement group is a logical construct. When a proximity placement group is defined, it's bound to an Azure region and an Azure resource group. When VMs are deployed, a proximity placement group is referenced by:
- The first Azure VM deployed under a network spine with many Azure compute units and low network latency. Such a network spine often matches a single Azure datacenter. You can think of the first virtual machine as a "scope VM" that is deployed into a compute scale unit based on Azure allocation algorithms that are eventually combined with deployment parameters.
- All subsequent VMs deployed that reference the proximity placement group are going to be deployed under the same network spine as the first virtual machine.
Note
If there's no host hardware deployed that could run a specific VM type under the network spine where the first VM was placed, the deployment of the requested VM type won’t succeed. You’ll get an allocation failure message that indicates that the VM can't be supported within the perimeter of the proximity placement group.
To reduce risk of the above, it's recommended to use the intent option when creating the proximity placement group. The intent option allows you to list the VM types that you're intending to include into the proximity placement group. This list of VM types will be taken to find the best datacenter that hosts these VM types. If such a datacenter is found, the PPG is going to be created and is scoped for the datacenter that fulfills the VM SKU requirements. If there's no such datacenter found, the creation of the proximity placement group is going to fail. You can find more information in the documentation PPG - Use intent to specify VM sizes. Be aware that actual capacity situations aren't taken into account in the checks triggered by the intent option. As a result, there still could be allocation errors rooted in insufficient capacity available.
A single Azure resource group can have multiple proximity placement groups assigned to it. But a proximity placement group can be assigned to only one Azure resource group.
For more information and deployment examples of proximity placement groups, see the available documentation.
Proximity placement groups with zonal deployments
It's important to provide a reasonably low network latency between the SAP application tier and the DBMS tier. In most situations a zonal deployment alone fulfills this requirement. For a limited set of scenarios, a zonal deployment alone might not meet the application latency requirements. Such situations require VM placement as close as possible and enable reasonably low network latency, an Azure proximity placement group can be defined for such an SAP system.
Avoid bundling several SAP production or nonproduction systems into a single proximity placement group. Avoid bundles of SAP systems because the more systems you group in a proximity placement group, the higher the chances:
- That you require a VM type that isn't available under the network spine into which the proximity placement group was assigned to.
- That resources of nonmainstream VMs, like M-Series VMs, could eventually be unfulfilled when you need to expand the number of VMs into a proximity placement group over time.
Based on many improvements deployed by Microsoft into the Azure regions to reduce network latency within an Azure availability zone, the deployment guidance when using proximity placement groups for zonal deployments, looks like:
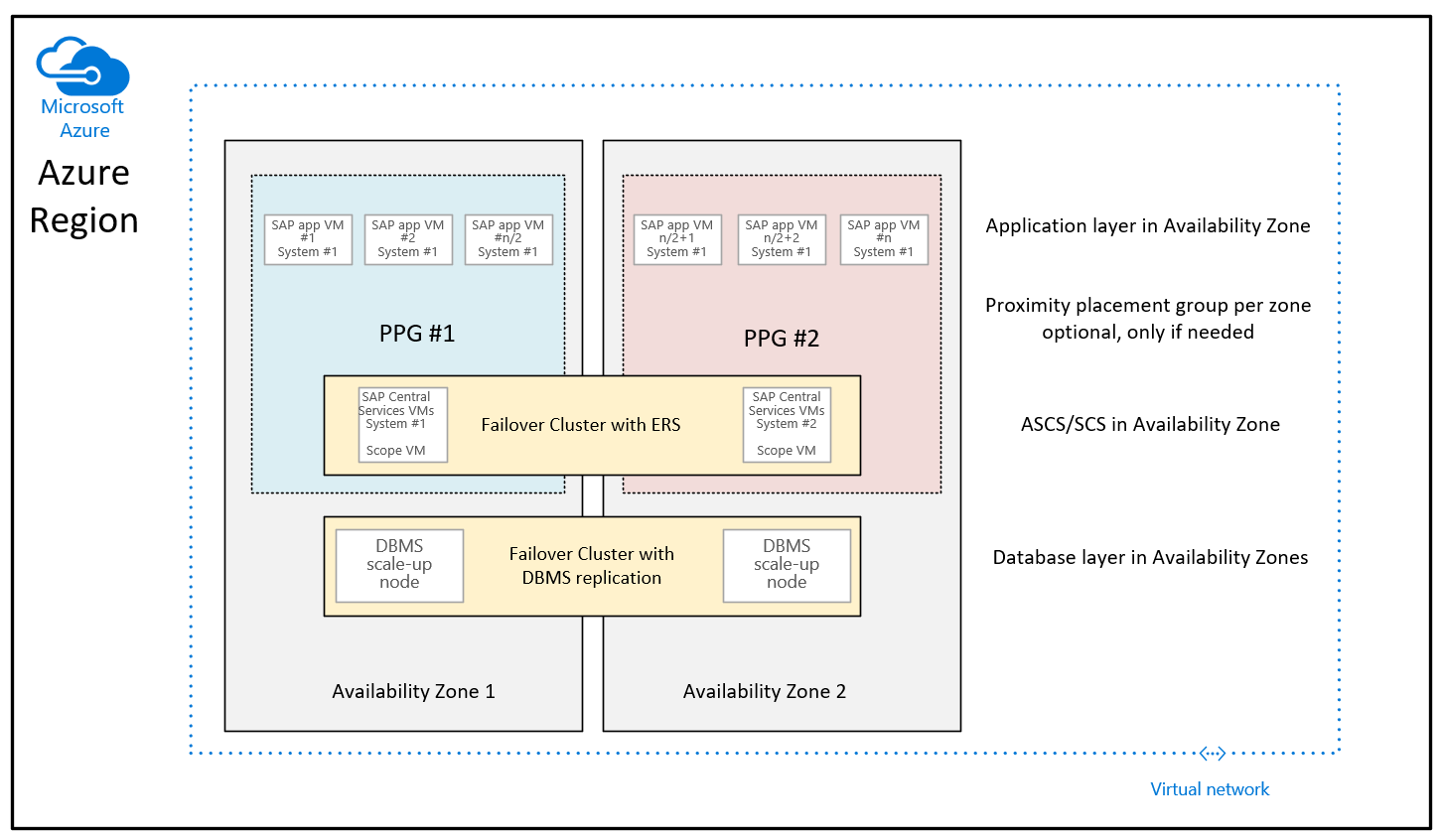
The difference to the recommendation given so far is that the database VMs in the two zones are no more a part of the proximity placement groups. The proximity placement groups per zone are now scoped with the deployment of the VM running the SAP ASCS/SCS instances. This also means that for the regions where availability zones are collected by multiple datacenters, the ASCS/SCS instance, and the application tier could run under one network spine and the database VMs could run under another network spine. Though with the network improvements made, the network latency between the SAP application tier and the DBMS tier still should be sufficient for sufficiently good performance and throughput. The advantage of this new configuration is that you have more flexibility in resizing VMs or moving to new VM types with either the DBMS layer or/and the application layer of the SAP system.
For the special case of using Azure NetApp Files for the DBMS environment and the Azure NetApp Files related functionality of Azure NetApp Files application volume group for SAP HANA and its necessity for proximity placement groups, check the document NFS v4.1 volumes on Azure NetApp Files for SAP HANA.
Proximity placement groups with availability set deployments
In this case, the purpose is to use proximity placement groups to collocate the VMs that are deployed through different availability sets. In this usage scenario, you aren't using a controlled deployment across different availability zones in a region. Instead you want to deploy the SAP system by using availability sets. As a result, you have at least an availability set for the DBMS VMs, ASCS/SCS VMs, and the application tier VMs. Since you can't specify at deployment time of a VM an availability set AND an availability zone, you can't control where the VMs in the different availability sets are going to be allocated. This could result in some Azure regions that the network latency between different VMs, still could be too high to give a sufficiently good performance experience. So the resulting architecture would look like:
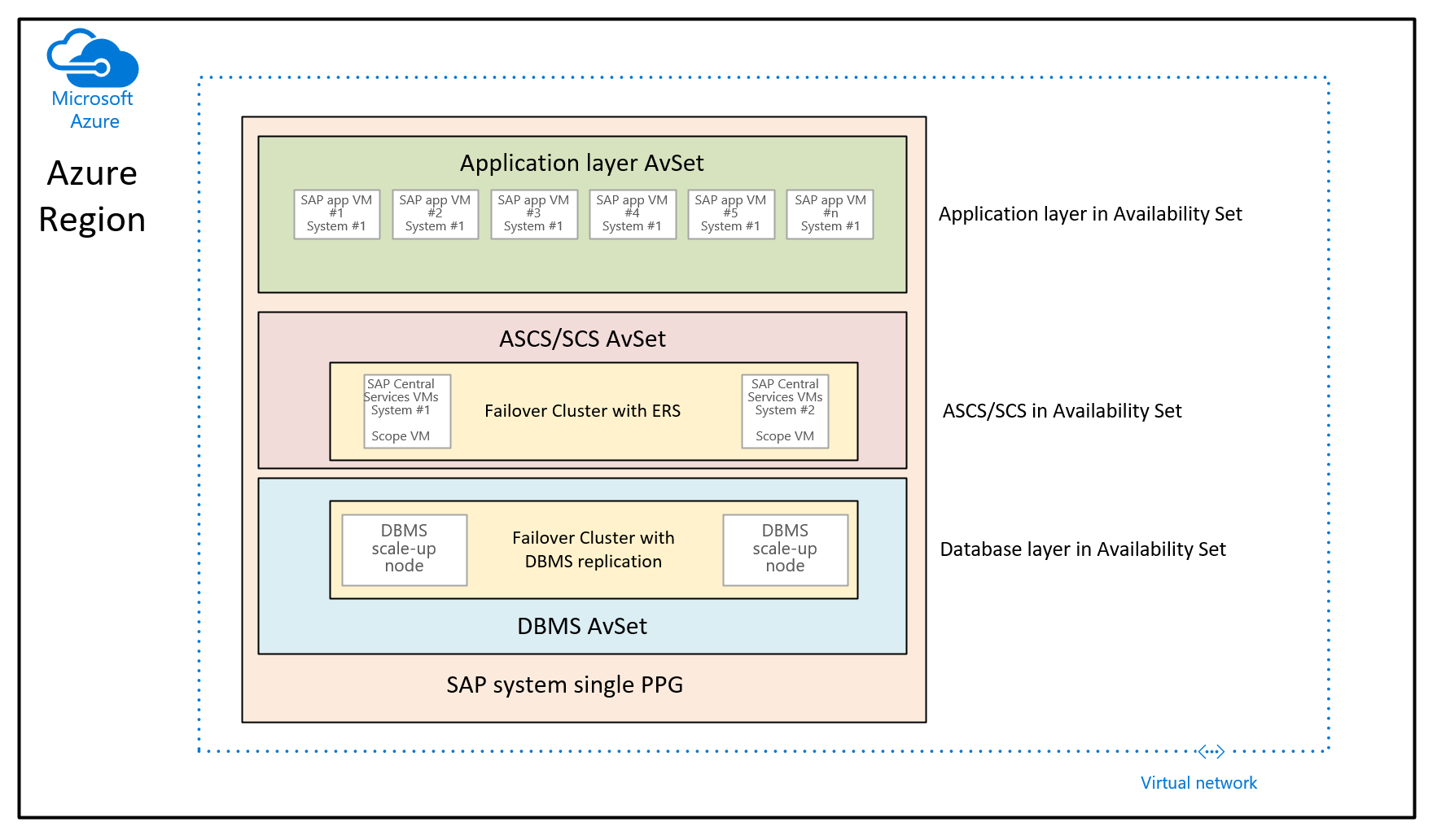
In this graphic, a single proximity placement group would be assigned to a single SAP system. This PPG gets assigned to the three availability sets. The proximity placement group is then scoped by deploying the first database tier VMs into the DBMS availability set. This architecture recommendation collocates all VMs under the same network spine. It's introducing the restrictions mentioned earlier in this article. Therefore, the proximity placement group architecture should be used sparsely.
Combine availability sets and availability zones with proximity placement groups
One of the problems to using availability zones for SAP system deployments is that you can’t deploy the SAP application tier by using availability sets within the specific availability zone. You want the SAP application tier to be deployed in the same zones as the SAP ASCS/SCS VMs. Referencing an availability zone and an availability set when deploying a single VM isn't possible so far. But just deploying a VM instructing an availability zone, you lose the ability to make sure the application layer VMs are spread across different update and failure domains.
By using proximity placement groups, you can bypass this restriction. Here's the deployment sequence:
- Create a proximity placement group.
- Deploy your anchor VM, recommended being the ASCS/SCS VM, by referencing an availability zone.
- Create an availability set that references the Azure proximity placement group. (See the command later in this article.)
- Deploy the application layer VMs by referencing the availability set and the proximity placement group.
Important
It is important to understand that disks of the application layer VMs are not guaranteed to be allocated in the same availability zone as the VMs are directed to using the proximity placement group. The result of the deployment shown in the next steps may be that the VMs are allocated in the same network spine and with that the same availability zone as the anchor VM. But the respective disks (base VHD and mounted Azure block storage disks) may not be allocated under the same network spine or even the same availability zone. Instead the disks of those VMs can be allocated in any of the datacenters of the specific region. Though the disks of the anchor VM that got deployed by defining a zone are going to be deployed in the same zone as the VM got deployed.
Instead of deploying the first VM as demonstrated in the previous section, you reference an availability zone and the proximity placement group when you deploy the VM:
New-AzVm -ResourceGroupName "ppgexercise" -Name "centralserviceszone1" -Location "westus2" -OpenPorts 80,3389 -Zone "1" -ProximityPlacementGroup "collocate" -Size "Standard_E8s_v4"
A successful deployment of this virtual machine would host the ASCS/SCS instance of the SAP system in one availability zone. In this case, the VM and the base VHD of the VM and potentially mounted Azure block storage disks are allocated within the same availability zone. The scope of the proximity placement group is fixed to one of the network spines in the availability zone you defined.
In the next step, you need to create the availability sets you want to use for the application layer of your SAP system.
Define and create the proximity placement group. The command for creating the availability set requires an additional reference to the proximity placement group ID (not the name). You can get the ID of the proximity placement group by using this command:
Get-AzProximityPlacementGroup -ResourceGroupName "ppgexercise" -Name "collocate"
When you create the availability set, you need to consider additional parameters when you're using managed disks (default unless specified otherwise) and proximity placement groups:
New-AzAvailabilitySet -ResourceGroupName "ppgexercise" -Name "ppgavset" -Location "westus2" -ProximityPlacementGroupId "/subscriptions/my very long ppg id string" -sku "aligned" -PlatformUpdateDomainCount 3 -PlatformFaultDomainCount 2
Ideally, you should use three fault domains. But the number of supported fault domains can vary from region to region. In this case, the maximum number of fault domains possible for the specific regions is two. To deploy your application layer VMs, you need to add a reference to your availability set name and the proximity placement group name, as shown here:
New-AzVm -ResourceGroupName "ppgexercise" -Name "appinstance1" -Location "westus2" -OpenPorts 80,3389 -AvailabilitySetName "myppgavset" -ProximityPlacementGroup "collocate" -Size "Standard_E16s_v4"
Note
The disks of the VMs deployed into the availability set above are not forced to be allocated in the same availability zone as the VM is. Though you achieved that the application layer VMs are spread across different fault domains under the same network spine as the anchor VM is allocated, the disks, though also allocated in different fault domains may be allocated in different locations on a region wide scope.
The result of this deployment is:
- A Central Services for your SAP system that's located in a specific availability zone(s).
- An SAP application layer that's located through availability sets in the same network spine as the SAP Central services (ASCS/SCS) VM or VMs.
Note
Because you deploy one DBMS and ASCS/SCS VMs into one zone and the second DBMS and ASCS/SCS VMs into another zone to create a high availability configurations, you'll need a different proximity placement group for each of the zones. The same is true for any availability set that you use.
Change proximity placement group configurations of an existing system
If you implemented proximity placement groups as of the recommendations given so far, and you want to adjust to the new configuration, you can do so with the methods described in these articles:
- Deploy VMs to proximity placement groups using Azure CLI.
- Deploy VMs to proximity placement groups using PowerShell.
You can also use these commands for cases where you're getting allocation errors in cases where you can't move to a new VM type with an existing VM in the proximity placement group.
Virtual Machine Scale Set with Flexible orchestration
To avoid the limitations associated with proximity placement group, it's advised to deploy SAP workload across availability zones using flexible scale set with FD=1. This deployment strategy ensures that VMs deployed in each zone aren't restricted to a single datacenter or network spine, and all SAP system components, such as databases, ASCS/ERS, and application tier are scoped within a zone. With all SAP system components being scoped at the zonal level, the network latency between different components of a single SAP system must be sufficient to ensure satisfactory performance and throughput. The key benefit of this new deployment option with flexible scale set with FD=1 is that it provides greater flexibility in resizing VMs or switching to new VM types for all layers of SAP system. Also, the scale set would allocate VMs across multiple fault domains within a single zone, which is ideal for running multiple VMs of the application tier in each zone. For more information, see virtual machine scale set for SAP workload document.
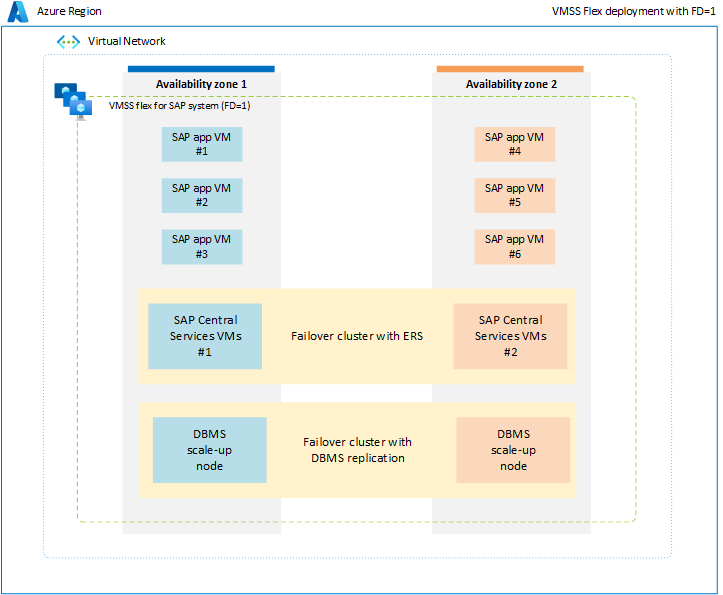
In a nonproduction or non-HA environment, it's possible to deploy all SAP system components, including the database, ASCS, and application tier, within a single zone using a flexible scale set with FD=1.
Previously recommended deployment options
This section includes details about previously recommended deployment options to optimize network latency for SAP. With new features and Azure growth over time, details within this section should only be applied in rare cases only.
Proximity placement groups for whole SAP system with zonal deployments
The proximity placement group usage that we recommended so far, looks like in this graphic.

You create a proximity placement group (PPG) in each of the two availability zones you deployed your SAP system into. All the VMs of a particular zone are part of the individual proximity placement group of that particular zone. You start in each zone with deploying the DBMS VM to scope the PPG and then deploy the ASCS VM into the same zone and PPG. In a third step, you create an Azure availability set, assign the availability set to the scoped PPG and deploy the SAP application layer into it. The advantage of this configuration was that all the components are nicely aligned underneath the same network spine. The large disadvantage is that your flexibility in resizing virtual machines can be limited.
Based on many improvements deployed by Microsoft into the Azure regions to reduce network latency within an Azure availability zone, the current deployment guidance for zonal deployments in this article exists.
Proximity placement groups and HANA Large Instances
If some of your SAP systems rely on HANA Large Instances for the database layer, you can experience significant improvements in network latency between the HANA Large Instances unit and Azure VMs when you're using HANA Large Instances units that are deployed in Revision 4 rows or stamps. One improvement is that HANA Large Instances units, as they're deployed, deploy with a proximity placement group. You can use that proximity placement group to deploy your application layer VMs. As a result, those VMs will be deployed in the same datacenter that hosts your HANA Large Instances unit.
To determine whether your HANA Large Instances unit is deployed in a Revision 4 stamp or row, check the article Azure HANA Large Instances control through Azure portal. In the attributes overview of your HANA Large Instances unit, you can also determine the name of the proximity placement group because it was created when your HANA Large Instances unit was deployed. The name that appears in the attributes overview is the name of the proximity placement group that you should deploy your application layer VMs into.
As compared to SAP systems that use only Azure virtual machines, when you use HANA Large Instances, you have less flexibility in deciding how many Azure resource groups to use. All the HANA Large Instances units of a HANA Large Instances tenant are grouped in a single resource group, as described this article. Unless you deploy into different tenants to separate, for example, production and non-production systems or other systems, all your HANA Large Instances units will be deployed in one HANA Large Instances tenant. This tenant has a one-to-one relationship with a resource group. But a separate proximity placement group will be defined for each of the single units.
As a result, the relationships among Azure resource groups and proximity placement groups for a single tenant will be as shown here:

Next steps
Check out the documentation: