Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Azure Confidential Clean Rooms offers a protected environment, called a clean room, that helps organizations overcome the security and privacy challenges of using sensitive data. Organizations can collaborate and analyze data in the clean room using advanced privacy-enhancing features like protected governance and audit, verifiable trust, and controlled access enabled by confidential computing.
Typical scenarios include multi-party big-data analytics on combined datasets, machine learning (ML) training and fine-tuning where the training data and model come from different parties and multi-party ML inferencing on sensitive inputs.
Azure Confidential Clean Rooms for Analytics (Preview)
Azure Confidential Clean Rooms for Analytics is a fully managed service that allows customers and their partners to securely analyze privacy-sensitive datasets. It uses confidential compute enabled Apache Spark-based big-data analytics (Spark SQL) which helps protect their raw data from other collaborators and from the Azure operator by performing computations in a Trusted Execution Environment (TEE).
The following diagram shows how organizations collaborate by using Azure Confidential Clean Rooms for Analytics.
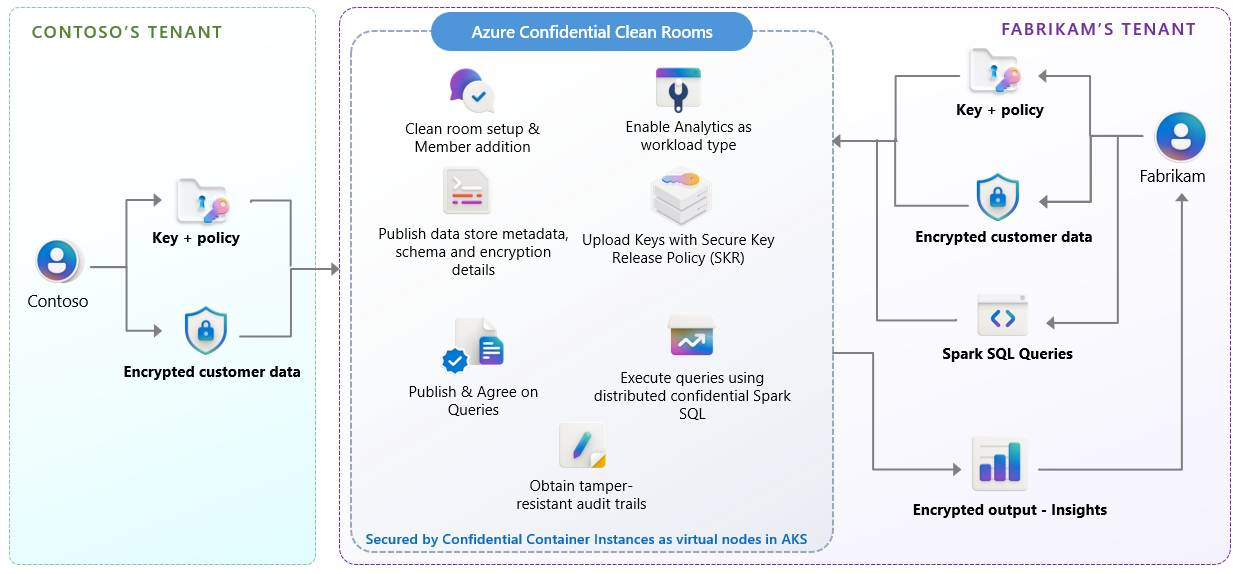
Note
Azure Confidential Clean Rooms for Analytics is currently in limited preview. The preview is subject to the Supplemental Terms of Use for Microsoft Azure Previews. Customers should not use the preview to process personal data or other data that is subject to legal or regulatory compliance requirements. The preview is intended for testing, evaluation, and feedback, and it shouldn't be used in production.
Key features

- Fully managed: Azure takes care of the infrastructure provisioning and scaling with no user intervention, which allows customers to focus on the queries and insights rather than on infrastructure management.
- Confidential Spark SQL: Spark SQL allows you to query large datasets and run complex queries in a distributed computing environment. In the confidential computing enabled version, the Spark driver and executors are fully attested policy-governed enclaves running as virtual nodes on Confidential Azure Container Instances (C-ACI) in an Azure Kubernetes Service (AKS) cluster which helps prevent exfiltration of collaborators’ data during query execution.
- Governance: Helps manage membership to clean rooms, enables and verifies approval for queries from relevant collaborators before executing them, and verifies consent to access sensitive collaborator data. It also helps generate tamper-resistant audit trails containing salient clean-room events. This governance is made possible with the help of an implementation of the Confidential Consortium Framework (CCF).
- Privacy controls: Each contributed dataset declares an
allowedFieldslist so only those columns are exposed to queries. In addition, each published query can declare a minimum row count per input view, under which the query is rejected (pre-conditions) and a minimum count under which aggregated groups in the output are dropped (post-filters). Such guards help prevent re-identification of individuals through the output. - Verifiable trust: Cryptographic remote attestation at each step forms the cornerstone of the service, letting every participant independently verify that the clean room is running known and attested code on genuine confidential hardware.
- Open-source containers: All Microsoft-provided clean-room container images and sidecars are published at
mcr.microsoft.com/cleanroom, and their source code is available in the Azure/azure-cleanroom repository. Their provenance and integrity can be verified using GitHub artifact attestation.
Use cases
Multiparty confidential big-data analytics unlocks value in scenarios where data sensitivity, regulatory pressure, or competitive concerns previously blocked collaboration. The following scenarios are examples of where confidential analytics can provide value. Note that the preview shouldn't be used to process personal data or other data that is subject to legal or regulatory compliance requirements.
Media and advertising
- Collaboration of advertiser CRM data with publisher data for audience targeting and segment activation.
- Collaboration of audience data with measurement partners for measurement and attribution.
Banking and finance
- Collaboration between banks and insurance firms to upsell relevant products to existing customers without sharing raw data from either side.
- Collaboration with retailers to generate customized offers for bank customers, without exposing either party's underlying data.
Government and public sector
- Secure collaboration across government departments to deliver better citizen welfare outcomes.
- Secure collaboration between government and private enterprises on shared-interest workloads such as traffic monitoring and weather systems.
Healthcare
- Enable healthcare firms to combine their data with third-party institutions to accelerate clinical development without exposing underlying patient data. An example can be identifying eligible participants for a clinical trial.
- Combine patient datasets across hospitals to study disease patterns or outcomes without exposing sensitive patient information from either side.
Retail
- Analyze customer behavior across retailers and partners to enable richer personalization and inventory planning, without exposing each retailer's underlying customer data.
Frequently asked questions
Is there a sample to try?
Yes. After your request to join the preview is accepted, use one of the published samples:
- Azure CLI-based sample: analytics-using-managedcleanroom — README-CLI
- REST API-based sample: analytics-using-managedcleanroom — README-API
Can more than two organizations participate in a collaboration?
Yes. Azure Confidential Clean Rooms allows multiple data providers to share data in a single clean room.
Which data formats are supported as input and output?
CSV, Parquet, and JSON.
How does the service limit which columns are exposed to queries?
Each contributed dataset declares an
allowedFieldslist, so only those columns are exposed to queries running in the clean room. Every other column in the source storage is excluded from access.How does the service prevent individual-level re-identification from the output?
Every published query can declare a minimum row count per input view, under which the query is rejected (pre-conditions) and a minimum count under which aggregated groups in the output are dropped (post-filters). The query composer can set these, and other collaborators can review and approve them.
Who has to approve a query?
All collaborators whose datasets are referenced by a query must approve it.
Joining the preview
Azure Confidential Clean Rooms for Analytics is currently in limited preview. If you're interested in joining the preview, fill in and submit this form.
After you submit the form, we'll review your request. If we accept your request, we'll contact you with detailed steps for joining. Keep in mind that because the preview is limited, we might not be able to accept all requests.
If you have workload requirements outside Spark SQL analytics — such as custom analytics pipelines, machine learning training and fine-tuning, or inferencing — fill in and submit the same form, and we'll get back to you.