Quickstart: Deploy a Managed Apache Spark Cluster with Azure Databricks
Azure Managed Instance for Apache Cassandra provides automated deployment and scaling operations for managed open-source Apache Cassandra datacenters. This feature accelerates hybrid scenarios and reducing ongoing maintenance.
This quickstart demonstrates how to use the Azure portal to create a fully managed Apache Spark cluster inside the Azure Virtual Network of your Azure Managed Instance for Apache Cassandra cluster. You create the Spark cluster in Azure Databricks. Later, you can create or attach notebooks to the cluster, read data from different data sources, and analyze insights.
You can also learn more with detailed instructions on Deploying Azure Databricks in your Azure Virtual Network (Virtual Network Injection).
Prerequisites
If you don't have an Azure subscription, create a free account before you begin.
Create an Azure Databricks cluster
Follow these steps to create an Azure Databricks cluster in a Virtual Network that has the Azure Managed Instance for Apache Cassandra:
Sign in to the Azure portal.
In the left navigation pane, locate Resource groups. Navigate to your resource group that contains the Virtual Network where your managed instance is deployed.
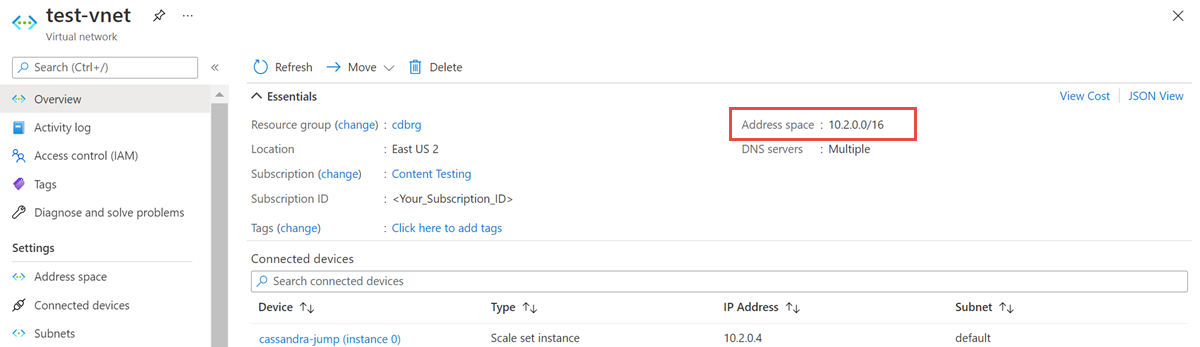
Open the Virtual Network resource, and make a note of the Address space:
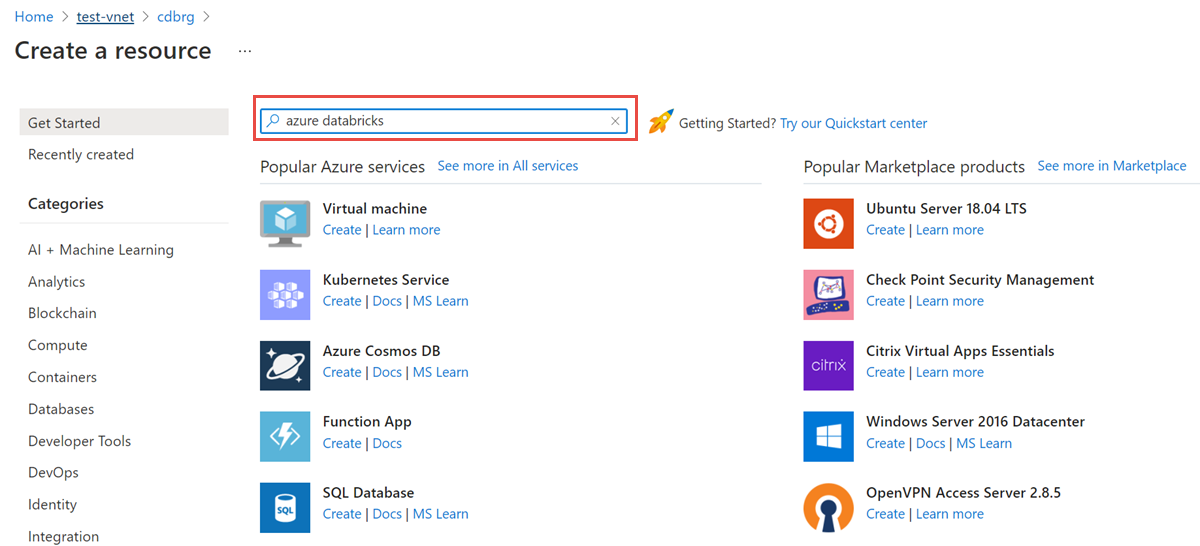
From the resource group, select Add and search for Azure Databricks in the search field:
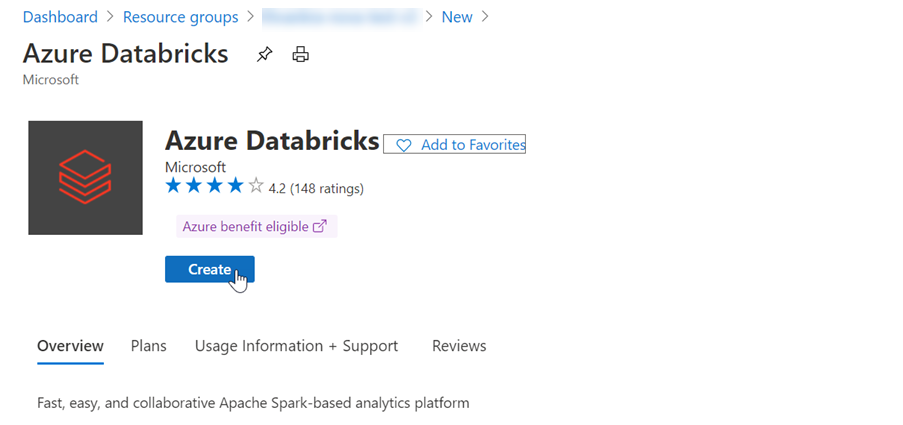
Select Create to create an Azure Databricks account:
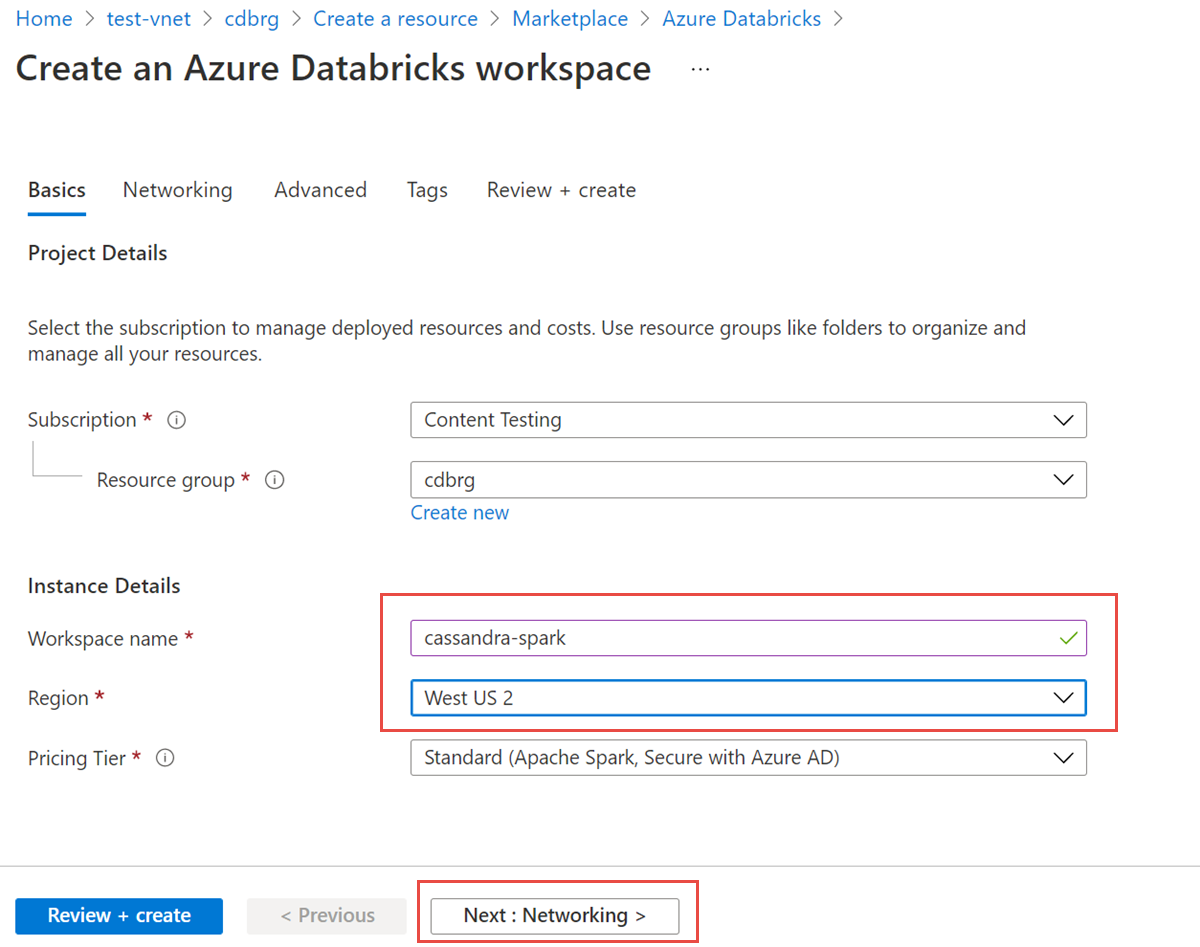
Enter the following values:
- Workspace name Provide a name for your Databricks workspace.
- Region Make sure to select the same region as your Virtual Network.
- Pricing Tier Choose between Standard, Premium, or Trial. For more information on these tiers, see Databricks pricing page.
Next, select the Networking tab, and enter the following details:
- Deploy Azure Databricks workspace in your Virtual Network (VNet) Select Yes.
- Virtual Network From the dropdown, choose the Virtual Network where your managed instance exists.
- Public Subnet Name Enter a name for the public subnet.
- Public Subnet CIDR Range Enter an IP range for the public subnet.
- Private Subnet Name Enter a name for the private subnet.
- Private Subnet CIDR Range Enter an IP range for the private subnet.
To avoid range collisions, ensure that you select higher ranges. If necessary, use a visual subnet calculator to divide the ranges:
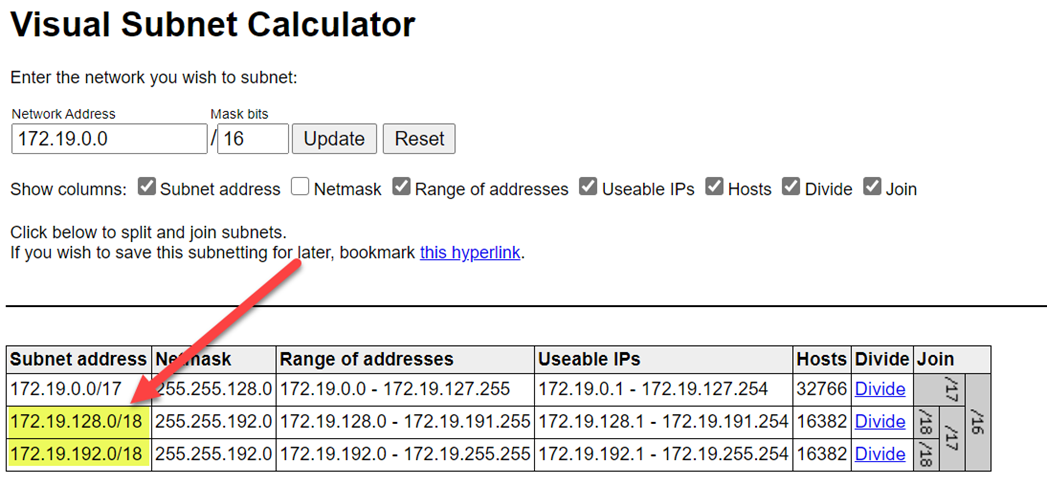
The following screenshot shows example details on the networking pane:
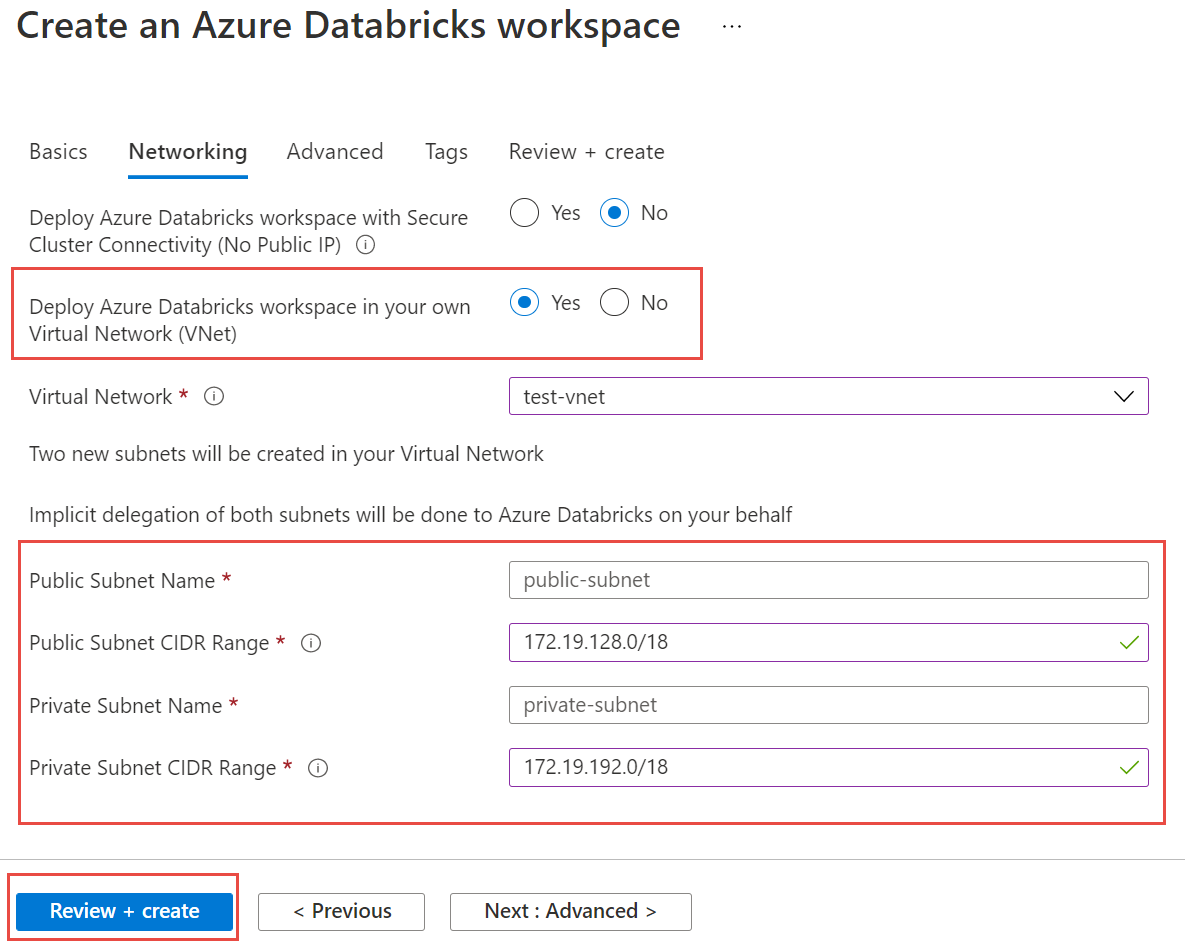
Select Review and create and then Create to deploy the workspace.
Launch Workspace after it's created.
You're redirected to the Azure Databricks portal. From the portal, select New Cluster.
In the New cluster pane, accept default values for all fields other than the following fields:
- Cluster Name Enter a name for the cluster.
- Databricks Runtime Version We recommend selecting Databricks runtime version 7.5 or higher, for Spark 3.x support.
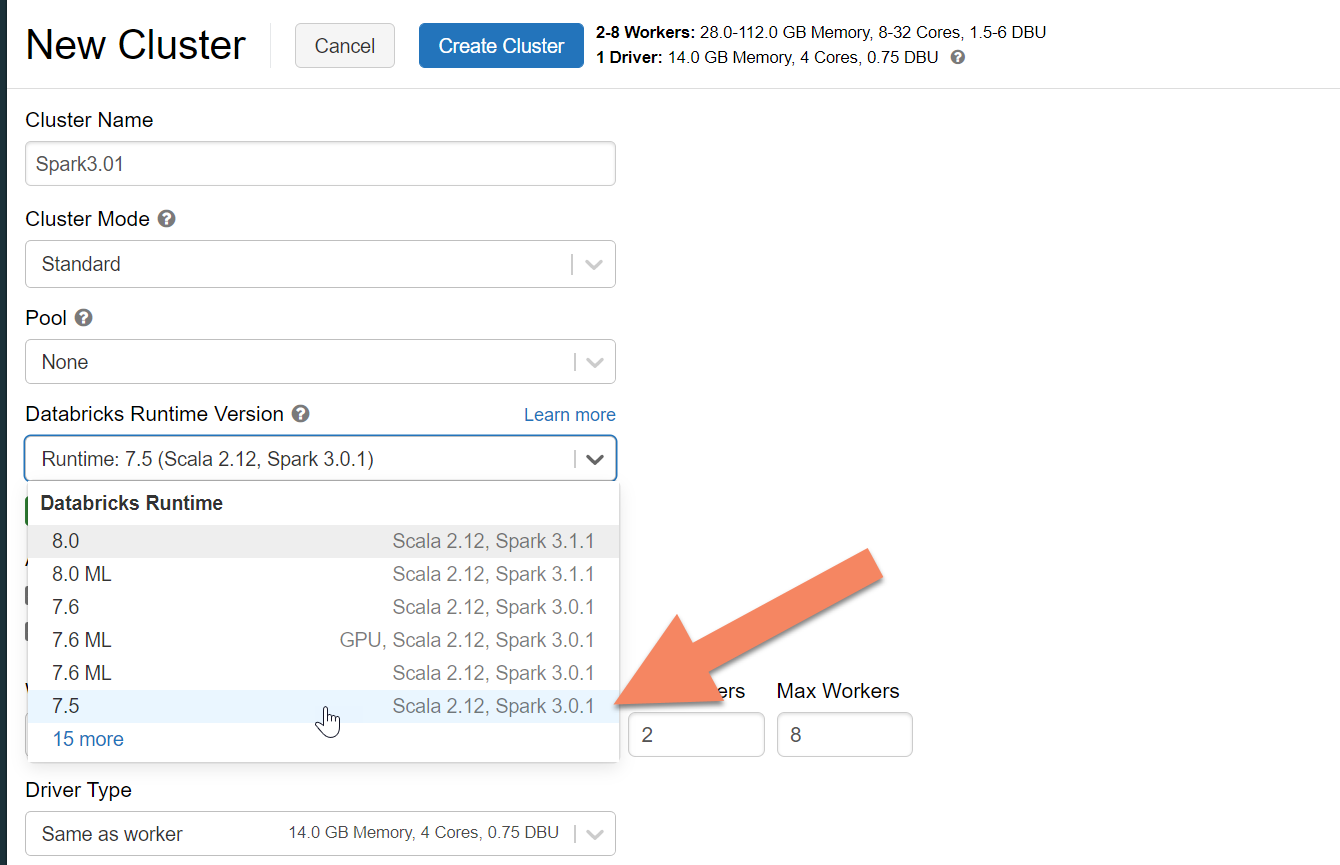
Expand Advanced Options and add the following configuration. Make sure to replace the node IPs and credentials:
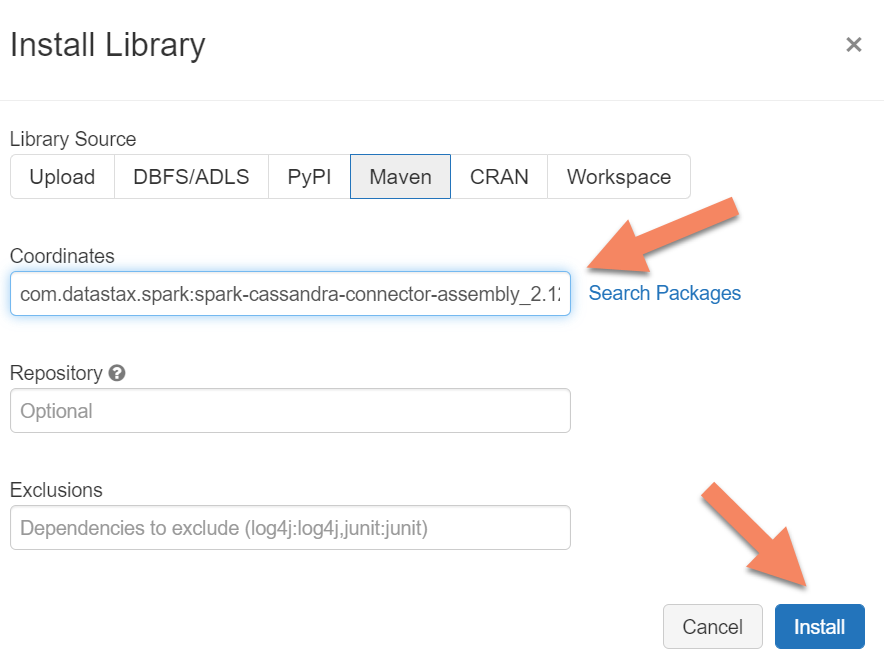
spark.cassandra.connection.host <node1 IP>,<node 2 IP>, <node IP> spark.cassandra.auth.password cassandra spark.cassandra.connection.port 9042 spark.cassandra.auth.username cassandra spark.cassandra.connection.ssl.enabled trueAdd the Apache Spark Cassandra Connector library to your cluster to connect to both native and Azure Cosmos DB Cassandra endpoints. In your cluster, select Libraries > Install New > Maven, and then add
com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0in Maven coordinates.
Clean up resources
If you're not going to continue to use this managed instance cluster, delete it with the following steps:
- From the left-hand menu of Azure portal, select Resource groups.
- From the list, select the resource group you created for this quickstart.
- On the resource group Overview pane, select Delete resource group.
- In the next window, enter the name of the resource group to delete, and then select Delete.
Next steps
In this quickstart, you learned how to create a fully managed Apache Spark cluster inside the Virtual Network of your Azure Managed Instance for Apache Cassandra cluster. Next, you can learn how to manage the cluster and datacenter resources:
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for