Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
APPLIES TO:  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Tip
Try out Data Factory in Microsoft Fabric, an all-in-one analytics solution for enterprises. Microsoft Fabric covers everything from data movement to data science, real-time analytics, business intelligence, and reporting. Learn how to start a new trial for free!
This quickstart describes how to use .NET SDK to create an Azure Data Factory. The pipeline you create in this data factory copies data from one folder to another folder in an Azure blob storage. For a tutorial on how to transform data using Azure Data Factory, see Tutorial: Transform data using Spark.
Prerequisites
Azure subscription
If you don't have an Azure subscription, create a free account before you begin.
Azure roles
To create Data Factory instances, the user account that you use to sign in to Azure must be a member of the contributor or owner role, or an administrator of the Azure subscription. To view the permissions that you have in the subscription, go to the Azure portal, select your username in the upper-right corner, select "..." icon for more options, and then select My permissions. If you have access to multiple subscriptions, select the appropriate subscription.
To create and manage child resources for Data Factory - including datasets, linked services, pipelines, triggers, and integration runtimes - the following requirements are applicable:
- To create and manage child resources in the Azure portal, you must belong to the Data Factory Contributor role at the resource group level or above.
- To create and manage child resources with PowerShell or the SDK, the contributor role at the resource level or above is sufficient.
For sample instructions about how to add a user to a role, see the Add roles article.
For more info, see the following articles:
Azure Storage account
You use a general-purpose Azure Storage account (specifically Blob storage) as both source and destination data stores in this quickstart. If you don't have a general-purpose Azure Storage account, see Create a storage account to create one.
Get the storage account name
You need the name of your Azure Storage account for this quickstart. The following procedure provides steps to get the name of your storage account:
- In a web browser, go to the Azure portal and sign in using your Azure username and password.
- From the Azure portal menu, select All services, then select Storage > Storage accounts. You can also search for and select Storage accounts from any page.
- In the Storage accounts page, filter for your storage account (if needed), and then select your storage account.
You can also search for and select Storage accounts from any page.
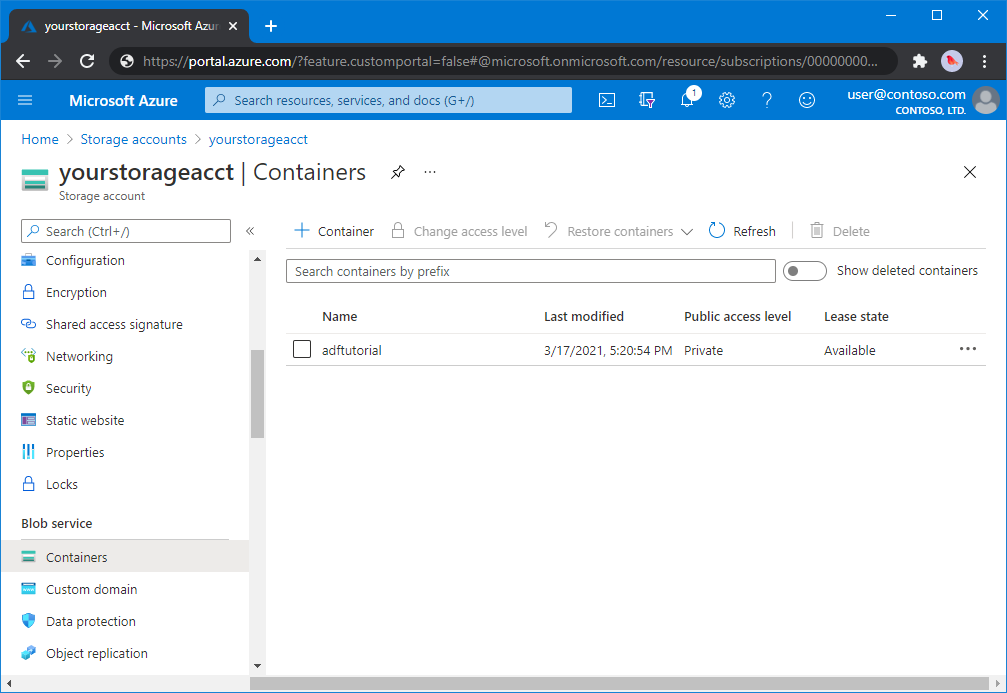
Create a blob container
In this section, you create a blob container named adftutorial in Azure Blob storage.
From the storage account page, select Overview > Containers.
On the <Account name> - Containers page's toolbar, select Container.
In the New container dialog box, enter adftutorial for the name, and then select OK. The <Account name> - Containers page is updated to include adftutorial in the list of containers.
Add an input folder and file for the blob container
In this section, you create a folder named input in the container you created, and then upload a sample file to the input folder. Before you begin, open a text editor such as Notepad, and create a file named emp.txt with the following content:
John, Doe
Jane, Doe
Save the file in the C:\ADFv2QuickStartPSH folder. (If the folder doesn't already exist, create it.) Then return to the Azure portal and follow these steps:
In the <Account name> - Containers page where you left off, select adftutorial from the updated list of containers.
- If you closed the window or went to another page, sign in to the Azure portal again.
- From the Azure portal menu, select All services, then select Storage > Storage accounts. You can also search for and select Storage accounts from any page.
- Select your storage account, and then select Containers > adftutorial.
On the adftutorial container page's toolbar, select Upload.
In the Upload blob page, select the Files box, and then browse to and select the emp.txt file.
Expand the Advanced heading. The page now displays as shown:
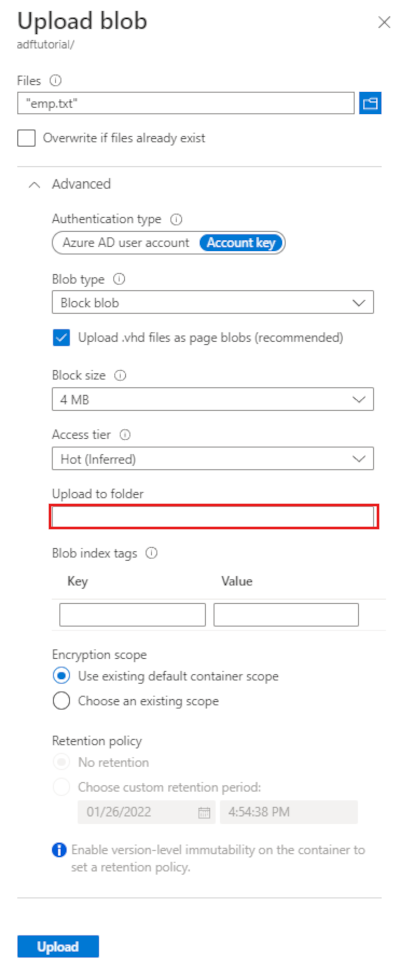
In the Upload to folder box, enter input.
Select the Upload button. You should see the emp.txt file and the status of the upload in the list.
Select the Close icon (an X) to close the Upload blob page.
Keep the adftutorial container page open. You use it to verify the output at the end of this quickstart.
Visual Studio
The walkthrough in this article uses Visual Studio 2019. The procedures for Visual Studio 2013, 2015, or 2017 differ slightly.
Create an application in Microsoft Entra ID
From the sections in How to: Use the portal to create a Microsoft Entra application and service principal that can access resources, follow the instructions to do these tasks:
- In Create a Microsoft Entra application, create an application that represents the .NET application you're creating in this tutorial. For the sign-on URL, you can provide a dummy URL as shown in the article (
https://contoso.org/exampleapp). - In Get values for signing in, get the application ID and tenant ID, and note down these values that you use later in this tutorial.
- In Certificates and secrets, get the authentication key, and note down this value that you use later in this tutorial.
- In Assign the application to a role, assign the application to the Contributor role at the subscription level so that the application can create data factories in the subscription.
Create a Visual Studio project
Next, create a C# .NET console application in Visual Studio:
- Launch Visual Studio.
- In the Start window, select Create a new project > Console App (.NET Framework). .NET version 4.5.2 or above is required.
- In Project name, enter ADFv2QuickStart.
- Select Create to create the project.
Install NuGet packages
Select Tools > NuGet Package Manager > Package Manager Console.
In the Package Manager Console pane, run the following commands to install packages. For more information, see the Azure.ResourceManager.DataFactory NuGet package.
Install-Package Azure.ResourceManager.DataFactory -IncludePrerelease Install-Package Azure.Identity
Create a data factory
Open Program.cs and include the following statements to add references to namespaces.
using Azure; using Azure.Core; using Azure.Core.Expressions.DataFactory; using Azure.Identity; using Azure.ResourceManager; using Azure.ResourceManager.DataFactory; using Azure.ResourceManager.DataFactory.Models; using Azure.ResourceManager.Resources; using System; using System.Collections.Generic;Add the following code to the Main method that sets the variables. Replace the placeholders with your own values. For a list of Azure regions in which Data Factory is currently available, select the regions that interest you on the following page, and then expand Analytics to locate Data Factory: Products available by region. The data stores (Azure Storage, Azure SQL Database, and more) and computes (HDInsight and others) used by data factory can be in other regions.
// Set variables string tenantID = "<your tenant ID>"; string applicationId = "<your application ID>"; string authenticationKey = "<your authentication key for the application>"; string subscriptionId = "<your subscription ID where the data factory resides>"; string resourceGroup = "<your resource group where the data factory resides>"; string region = "<the location of your resource group>"; string dataFactoryName = "<specify the name of data factory to create. It must be globally unique.>"; string storageAccountName = "<your storage account name to copy data>"; string storageKey = "<your storage account key>"; // specify the container and input folder from which all files // need to be copied to the output folder. string inputBlobContainer = "<blob container to copy data from, e.g. containername>"; string inputBlobPath = "<path to existing blob(s) to copy data from, e.g. inputdir/file>"; //specify the contains and output folder where the files are copied string outputBlobContainer = "<blob container to copy data from, e.g. containername>"; string outputBlobPath = "<the blob path to copy data to, e.g. outputdir/file>"; // name of the Azure Storage linked service, blob dataset, and the pipeline string storageLinkedServiceName = "AzureStorageLinkedService"; string blobDatasetName = "BlobDataset"; string pipelineName = "Adfv2QuickStartPipeline";Add the following code to the Main method that creates a data factory.
ArmClient armClient = new ArmClient( new ClientSecretCredential(tenantID, applicationId, authenticationKey, new TokenCredentialOptions { AuthorityHost = AzureAuthorityHosts.AzurePublicCloud }), subscriptionId, new ArmClientOptions { Environment = ArmEnvironment.AzurePublicCloud } ); ResourceIdentifier resourceIdentifier = SubscriptionResource.CreateResourceIdentifier(subscriptionId); SubscriptionResource subscriptionResource = armClient.GetSubscriptionResource(resourceIdentifier); Console.WriteLine("Get an existing resource group " + resourceGroupName + "..."); var resourceGroupOperation = subscriptionResource.GetResourceGroups().Get(resourceGroupName); ResourceGroupResource resourceGroupResource = resourceGroupOperation.Value; Console.WriteLine("Create a data factory " + dataFactoryName + "..."); DataFactoryData dataFactoryData = new DataFactoryData(AzureLocation.EastUS2); var dataFactoryOperation = resourceGroupResource.GetDataFactories().CreateOrUpdate(WaitUntil.Completed, dataFactoryName, dataFactoryData); Console.WriteLine(dataFactoryOperation.WaitForCompletionResponse().Content); // Get the data factory resource DataFactoryResource dataFactoryResource = dataFactoryOperation.Value;
Create a linked service
Add the following code to the Main method that creates an Azure Storage linked service.
You create linked services in a data factory to link your data stores and compute services to the data factory. In this Quickstart, you only need to create one Azure Blob Storage linked service for both the copy source and the sink store; it's named "AzureBlobStorageLinkedService" in the sample.
// Create an Azure Storage linked service
Console.WriteLine("Create a linked service " + storageLinkedServiceName + "...");
AzureBlobStorageLinkedService azureBlobStorage = new AzureBlobStorageLinkedService()
{
ConnectionString = azureBlobStorageConnectionString
};
DataFactoryLinkedServiceData linkedServiceData = new DataFactoryLinkedServiceData(azureBlobStorage);
var linkedServiceOperation = dataFactoryResource.GetDataFactoryLinkedServices().CreateOrUpdate(WaitUntil.Completed, storageLinkedServiceName, linkedServiceData);
Console.WriteLine(linkedServiceOperation.WaitForCompletionResponse().Content);
Create a dataset
Add the following code to the Main method that creates an Delimited text dataset.
You define a dataset that represents the data to copy from a source to a sink. In this example, this Delimited text dataset references to the Azure Blob Storage linked service you created in the previous step. The dataset takes two parameters whose value is set in an activity that consumes the dataset. The parameters are used to construct the "container" and the "folderPath" pointing to where the data resides/is stored.
// Create an Azure Blob dataset
DataFactoryLinkedServiceReference linkedServiceReference = new DataFactoryLinkedServiceReference(DataFactoryLinkedServiceReferenceType.LinkedServiceReference, storageLinkedServiceName);
DelimitedTextDataset delimitedTextDataset = new DelimitedTextDataset(linkedServiceReference)
{
DataLocation = new AzureBlobStorageLocation
{
Container = DataFactoryElement<string>.FromExpression("@dataset().container"),
FileName = DataFactoryElement<string>.FromExpression("@dataset().path")
},
Parameters =
{
new KeyValuePair<string, EntityParameterSpecification>("container",new EntityParameterSpecification(EntityParameterType.String)),
new KeyValuePair<string, EntityParameterSpecification>("path",new EntityParameterSpecification(EntityParameterType.String))
},
FirstRowAsHeader = false,
QuoteChar = "\"",
EscapeChar = "\\",
ColumnDelimiter = ","
};
DataFactoryDatasetData datasetData = new DataFactoryDatasetData(delimitedTextDataset);
var datasetOperation = dataFactoryResource.GetDataFactoryDatasets().CreateOrUpdate(WaitUntil.Completed, blobDatasetName, datasetData);
Console.WriteLine(datasetOperation.WaitForCompletionResponse().Content);
Create a pipeline
Add the following code to the Main method that creates a pipeline with a copy activity.
In this example, this pipeline contains one activity and takes four parameters: the input blob container and path, and the output blob container and path. The values for these parameters are set when the pipeline is triggered/run. The copy activity refers to the same blob dataset created in the previous step as input and output. When the dataset is used as an input dataset, input container and path are specified. And, when the dataset is used as an output dataset, the output container and path are specified.
// Create a pipeline with a copy activity
Console.WriteLine("Creating pipeline " + pipelineName + "...");
DataFactoryPipelineData pipelineData = new DataFactoryPipelineData()
{
Parameters =
{
new KeyValuePair<string, EntityParameterSpecification>("inputContainer",new EntityParameterSpecification(EntityParameterType.String)),
new KeyValuePair<string, EntityParameterSpecification>("inputPath",new EntityParameterSpecification(EntityParameterType.String)),
new KeyValuePair<string, EntityParameterSpecification>("outputContainer",new EntityParameterSpecification(EntityParameterType.String)),
new KeyValuePair<string, EntityParameterSpecification>("outputPath",new EntityParameterSpecification(EntityParameterType.String))
},
Activities =
{
new CopyActivity("CopyFromBlobToBlob",new DataFactoryBlobSource(),new DataFactoryBlobSink())
{
Inputs =
{
new DatasetReference(DatasetReferenceType.DatasetReference,blobDatasetName)
{
Parameters =
{
new KeyValuePair<string, BinaryData>("container", BinaryData.FromString("\"@pipeline().parameters.inputContainer\"")),
new KeyValuePair<string, BinaryData>("path", BinaryData.FromString("\"@pipeline().parameters.inputPath\""))
}
}
},
Outputs =
{
new DatasetReference(DatasetReferenceType.DatasetReference,blobDatasetName)
{
Parameters =
{
new KeyValuePair<string, BinaryData>("container", BinaryData.FromString("\"@pipeline().parameters.outputContainer\"")),
new KeyValuePair<string, BinaryData>("path", BinaryData.FromString("\"@pipeline().parameters.outputPath\""))
}
}
}
}
}
};
var pipelineOperation = dataFactoryResource.GetDataFactoryPipelines().CreateOrUpdate(WaitUntil.Completed, pipelineName, pipelineData);
Console.WriteLine(pipelineOperation.WaitForCompletionResponse().Content);
Create a pipeline run
Add the following code to the Main method that triggers a pipeline run.
This code also sets values of the inputContainer, inputPath, outputContainer, and outputPath parameters specified in the pipeline with the actual values of the source and sink blob paths.
// Create a pipeline run
Console.WriteLine("Creating pipeline run...");
Dictionary<string, BinaryData> parameters = new Dictionary<string, BinaryData>()
{
{ "inputContainer",BinaryData.FromObjectAsJson(inputBlobContainer) },
{ "inputPath",BinaryData.FromObjectAsJson(inputBlobPath) },
{ "outputContainer",BinaryData.FromObjectAsJson(outputBlobContainer) },
{ "outputPath",BinaryData.FromObjectAsJson(outputBlobPath) }
};
var pipelineResource = dataFactoryResource.GetDataFactoryPipeline(pipelineName);
var runResponse = pipelineResource.Value.CreateRun(parameters);
Console.WriteLine("Pipeline run ID: " + runResponse.Value.RunId);
Monitor a pipeline run
Add the following code to the Main method to continuously check the status until it finishes copying the data.
// Monitor the pipeline run Console.WriteLine("Checking pipeline run status..."); DataFactoryPipelineRunInfo pipelineRun; while (true) { pipelineRun = dataFactoryResource.GetPipelineRun(runResponse.Value.RunId.ToString()); Console.WriteLine("Status: " + pipelineRun.Status); if (pipelineRun.Status == "InProgress" || pipelineRun.Status == "Queued") System.Threading.Thread.Sleep(15000); else break; }Add the following code to the Main method that retrieves copy activity run details, such as the size of the data that's read or written.
// Check the copy activity run details Console.WriteLine("Checking copy activity run details..."); var queryResponse = dataFactoryResource.GetActivityRun(pipelineRun.RunId.ToString(), new RunFilterContent(DateTime.UtcNow.AddMinutes(-10), DateTime.UtcNow.AddMinutes(10))); var enumerator = queryResponse.GetEnumerator(); enumerator.MoveNext(); if (pipelineRun.Status == "Succeeded") Console.WriteLine(enumerator.Current.Output); else Console.WriteLine(enumerator.Current.Error); Console.WriteLine("\nPress any key to exit..."); Console.ReadKey();
Run the code
Build and start the application, then verify the pipeline execution.
The console prints the progress of creating data factory, linked service, datasets, pipeline, and pipeline run. It then checks the pipeline run status. Wait until you see the copy activity run details with the size of the read/write data. Then use tools such as Azure Storage Explorer to check the blob(s) is copied to "outputBlobPath" from "inputBlobPath" as you specified in the variables.
Sample output
Create a data factory quickstart-adf...
{
"name": "quickstart-adf",
"type": "Microsoft.DataFactory/factories",
"properties": {
"provisioningState": "Succeeded",
"version": "2018-06-01"
},
"location": "eastus2"
}
Create a linked service AzureBlobStorage...
{
"name": "AzureBlobStorage",
"type": "Microsoft.DataFactory/factories/linkedservices",
"properties": {
"type": "AzureBlobStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<storageAccountName>;",
"encryptedCredential": "<encryptedCredential>"
}
}
}
Creating dataset BlobDelimitedDataset...
{
"name": "BlobDelimitedDataset",
"type": "Microsoft.DataFactory/factories/datasets",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"type": "LinkedServiceReference",
"referenceName": "AzureBlobStorage"
},
"parameters": {
"container": {
"type": "String"
},
"path": {
"type": "String"
}
},
"typeProperties": {
"location": {
"container": {
"type": "Expression",
"value": "@dataset().container"
},
"type": "AzureBlobStorageLocation",
"fileName": {
"type": "Expression",
"value": "@dataset().path"
}
},
"columnDelimiter": ",",
"quoteChar": "\"",
"escapeChar": "\\",
"firstRowAsHeader": false
}
}
}
Creating pipeline Adfv2QuickStartPipeline...
{
"properties": {
"activities": [
{
"inputs": [
{
"type": "DatasetReference",
"referenceName": "BlobDelimitedDataset",
"parameters": {
"container": "@pipeline().parameters.inputContainer",
"path": "@pipeline().parameters.inputPath"
}
}
],
"outputs": [
{
"type": "DatasetReference",
"referenceName": "BlobDelimitedDataset",
"parameters": {
"container": "@pipeline().parameters.outputContainer",
"path": "@pipeline().parameters.outputPath"
}
}
],
"name": "CopyFromBlobToBlob",
"type": "Copy",
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "BlobSink"
}
}
}
],
"parameters": {
"inputContainer": {
"type": "String"
},
"inputPath": {
"type": "String"
},
"outputContainer": {
"type": "String"
},
"outputPath": {
"type": "String"
}
}
}
}
Creating pipeline run...
Pipeline run ID: 3aa26ffc-5bee-4db9-8bac-ccbc2d7b51c1
Checking pipeline run status...
Status: InProgress
Status: Succeeded
Checking copy activity run details...
{
"dataRead": 1048,
"dataWritten": 1048,
"filesRead": 1,
"filesWritten": 1,
"sourcePeakConnections": 1,
"sinkPeakConnections": 1,
"copyDuration": 8,
"throughput": 1.048,
"errors": [],
"effectiveIntegrationRuntime": "AutoResolveIntegrationRuntime (East US 2)",
"usedDataIntegrationUnits": 4,
"billingReference": {
"activityType": "DataMovement",
"billableDuration": [
{
"meterType": "AzureIR",
"duration": 0.06666666666666667,
"unit": "DIUHours"
}
],
"totalBillableDuration": [
{
"meterType": "AzureIR",
"duration": 0.06666666666666667,
"unit": "DIUHours"
}
]
},
"usedParallelCopies": 1,
"executionDetails": [
{
"source": {
"type": "AzureBlobStorage"
},
"sink": {
"type": "AzureBlobStorage"
},
"status": "Succeeded",
"start": "2023-12-15T10:25:33.9991558Z",
"duration": 8,
"usedDataIntegrationUnits": 4,
"usedParallelCopies": 1,
"profile": {
"queue": {
"status": "Completed",
"duration": 5
},
"transfer": {
"status": "Completed",
"duration": 1,
"details": {
"listingSource": {
"type": "AzureBlobStorage",
"workingDuration": 0
},
"readingFromSource": {
"type": "AzureBlobStorage",
"workingDuration": 0
},
"writingToSink": {
"type": "AzureBlobStorage",
"workingDuration": 0
}
}
}
},
"detailedDurations": {
"queuingDuration": 5,
"transferDuration": 1
}
}
],
"dataConsistencyVerification": {
"VerificationResult": "NotVerified"
}
}
Press any key to exit...
Verify the output
The pipeline automatically creates the output folder in the adftutorial blob container. Then, it copies the emp.txt file from the input folder to the output folder.
- In the Azure portal, on the adftutorial container page that you stopped at in the Add an input folder and file for the blob container section above, select Refresh to see the output folder.
- In the folder list, select output.
- Confirm that the emp.txt is copied to the output folder.
Clean up resources
To programmatically delete the data factory, add the following lines of code to the program:
Console.WriteLine("Deleting the data factory");
dataFactoryResource.Delete(WaitUntil.Completed);
Next steps
The pipeline in this sample copies data from one location to another location in an Azure blob storage. Go through the tutorials to learn about using Data Factory in more scenarios.