Schedule and run an Apache Spark job definition
Learn how to run a Microsoft Fabric Apache Spark job definition and find the job definition status and details.
Prerequisites
Before you get started, you must:
- Create a Microsoft Fabric tenant account with an active subscription. Create an account for free.
- Understand the Spark job definition: see What is an Apache Spark job definition?.
- Create a Spark job definition: see How to create an Apache Spark job definition in Fabric.
How to run a Spark job definition
There are two ways you can run a Spark job definition:
Run a Spark job definition manually by selecting Run from the Spark job definition item in the job list.

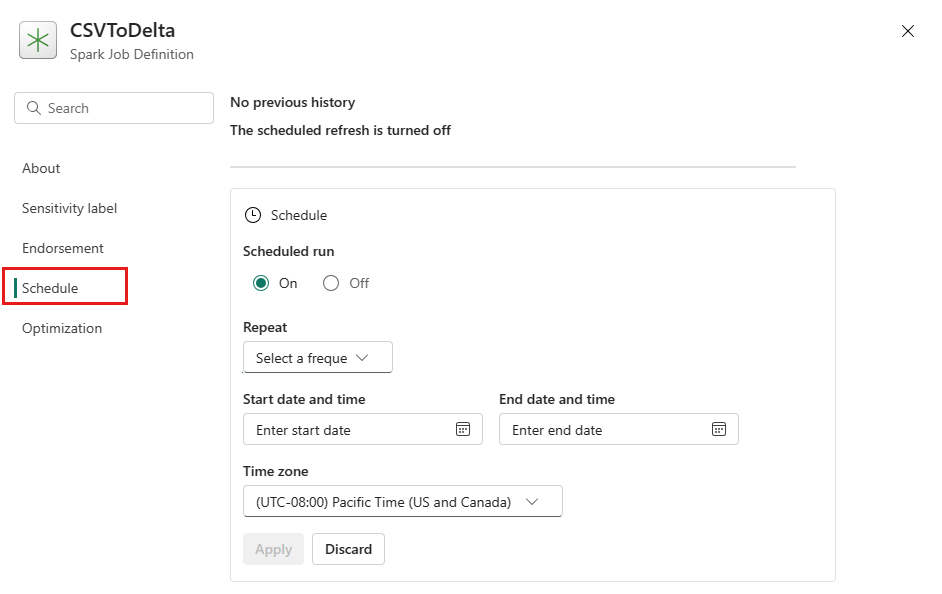
Schedule a Spark job definition by setting up a schedule plan on the Settings tab. Select Settings on the toolbar, then select Schedule.
Important
To run, a Spark job definition must have a main definition file and a default lakehouse context.
Tip
For a manual run, the account of the currently logged in user is used to submit the job. For a run triggered by a schedule, the account of the user who created the schedule plan is used to submit the job.
Three to five seconds after you've submitted the run, a new row appears under the Runs tab. The row shows details about your new run. The Status column shows the near real-time status of the job, and the Run kind column shows if the job is manual or scheduled.

For more information on how to monitor a job, see Monitor your Apache Spark job definition.
How to cancel a running job
Once the job is submitted, you can cancel the job by selecting Cancel active run from the Spark job definition item in the job list.

Spark job definition snapshot
The Spark job definition stores its latest state. To view the snapshot of the history run, select View Snapshot from the Spark job definition item in the job list. The snapshot shows the state of the job definition when the job is submitted, including the main definition file, the reference file, the command line arguments, the referenced lakehouse, and the Spark properties.

From a snapshot, you can take three actions:
- Save as a Spark job definition: Save the snapshot as a new Spark job definition.
- Open Spark job definition: Open the current Spark job definition.
- Restore: Restore the job definition with the snapshot. The job definition is restored to the state when the job was submitted.
