Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
This article describes how to use the Azure Log Analytics destination for Apache Spark diagnostics in Azure Synapse Analytics by using the Log Ingestion API.
Azure Synapse Apache Spark diagnostic emission provides a unified configuration model for collecting Spark diagnostics across supported destinations. For Azure Log Analytics, the Log Ingestion API is the recommended ingestion mechanism.
This article explains how to configure emitter properties, route Apache Spark logs, event logs, and metrics to Log Analytics, and query the ingested data for monitoring and troubleshooting purposes.
Migrate from the Data Collector API
If you are currently using the HTTP Data Collector API in Azure Synapse Analytics, migrate to the Log Ingestion API to align with the latest Azure Monitor ingestion architecture and best practices.
Key changes in the new model:
- Schema definitions are explicitly defined through Data Collection Rules (DCRs), providing predictable schema validation and more consistent query results compared to the previous free-form payload approach.
- Ingestion flow is routed through Data Collection Endpoints (DCEs) and DCR mappings, offering a more controlled and reliable ingestion path than posting data directly to the Data Collector API endpoint.
- Authentication supports both service principal with client secret and certificate-based authentication.
- The emitter type changes from
AzureLogAnalyticstoAzureLogIngestion. - Migration typically involves creating DCR and DCE resources, updating Azure Synapse Apache Spark pool configurations (for example, Spark configuration or diagnostic settings), and validating that data is successfully ingested into custom tables in Azure Log Analytics.
Log Ingestion API overview
For Apache Spark diagnostics in Azure Synapse Analytics, the Log Ingestion API provides a structured ingestion model for authentication, schema definition, routing, and data delivery into Azure Log Analytics.
Key components
| Component | Purpose |
|---|---|
| App registration credentials | Provides Microsoft Entra app identity used to authenticate Log Ingestion API requests with either a client secret or certificate. |
| Log Analytics table | Provides the target custom table where ingested Spark diagnostics are stored for querying and monitoring. |
| Data Collection Rule (DCR) | Defines input streams, schema mapping, and optional transformations for ingestion. |
| Data Collection Endpoint (DCE) | Provides the ingestion endpoint URI (dceUri) used by clients to send data through DCR-based routing. |
Only user-created DCRs configured for Log Ingestion API can be used for programmatic ingestion.
Step-by-step configuration
Step 1. Prepare Log Analytics workspace
A Log Analytics workspace is required to receive Spark diagnostics. It's the basic storage and query unit for Azure Monitor Logs.
If you don't have one, create a Log Analytics workspace in the Azure portal.
Important
As you complete the following steps, create the Data Collection Endpoint (DCE) and Data Collection Rule (DCR) resources in the same region as the Log Analytics workspace.
Step 2. Create a Data Collection Endpoint (DCE)
Create a Data Collection Endpoint (DCE) in the Azure portal. The DCE provides the endpoint URI that you configure in Spark properties for Log Ingestion API. The region of the DCE must be the same as the region of your Log Analytics workspace.
Users can optionally create one or more table types (logs, events, metrics) depending on their scenario, and each table type has its own corresponding DCR configuration and stream name. Only create and configure the table types you actually need.
In the Azure portal, go to Monitor in the left navigation pane.
Under Settings, select Data collection endpoints, and then select Create.
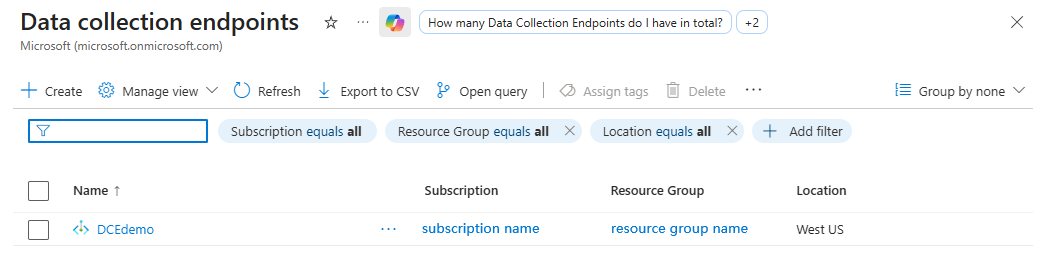
Create the endpoint, then note the DCE name (for example,
DCEdemo).

Step 3. Prepare sample JSON schema
When creating custom log tables, you must configure a Data Collection Rule (DCR). Based on the data stream definitions specified in the DCR, the system automatically generates the corresponding table schema in your Log Analytics workspace.
The following predefined JSON schema samples each map to a specific data type. Download the sample that fits your scenario, and upload it when you create the associated custom table and DCR.
- Spark event logs - Event table JSON schema sample
- Spark driver and executor logs - Log table JSON schema sample
- Spark metrics - Metric table JSON schema sample
Step 4. Create custom table (Direct Ingest)
Create a custom table in your Log Analytics workspace with the Log Ingestion API option, and upload the JSON schema sample to the associated DCR. This step is required to set up the destination for Spark diagnostics and ensure that the ingested data conforms to the expected schema. The region of the Log Analytics workspace, DCE, and DCR must be the same for successful ingestion.
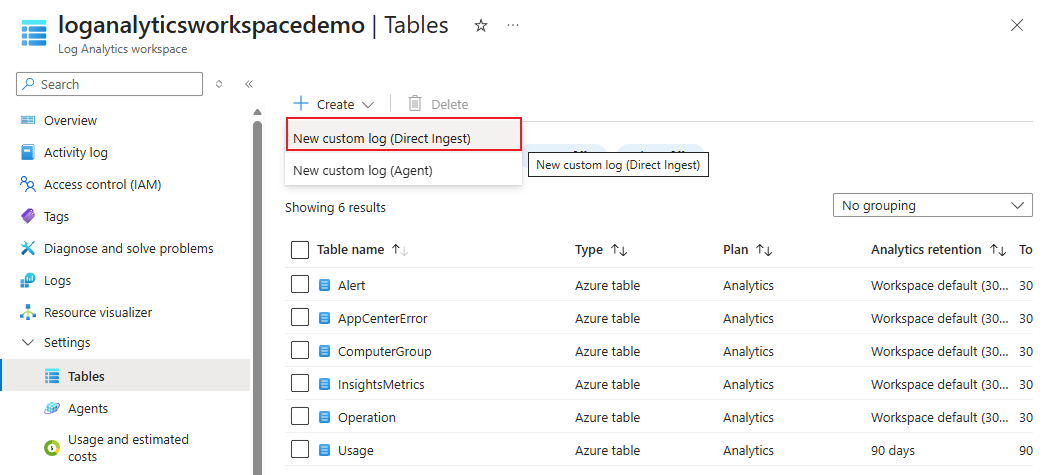
In the Azure portal, open your Log Analytics workspace (for example, loganalyticsworkspacedemo).
Select Tables > Create > New custom log (Direct Ingest).
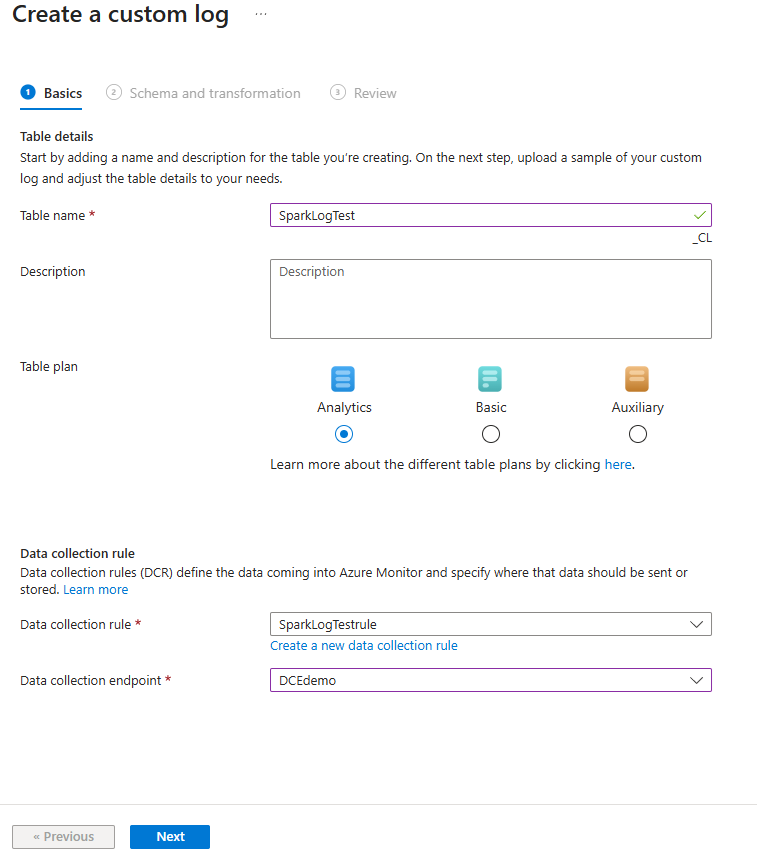
Enter the table settings:
- Table name: For example, SparkLogTest (suffix "_CL" is auto-added).
- Table Plan: Analytics
- Data Collection Rule: Create a new DCR (for example, SparkLogTestrule).
- Data Collection Endpoint: Select the DCE from the Create a Data Collection Endpoint (DCE) step (for example, DCEdemo).
Select Next.
In Schema and Transformation, upload the JSON schema sample. You don't need to configure DCR transformation because the schema is fully stabilized on the client side.


Step 5. Prepare service principal and collect DCR identifier
Register an app in Microsoft Entra ID.

Record the TenantId, ClientId, and ClientSecret (if you use client secret authentication). You use these values in the Spark configuration in Step 6.
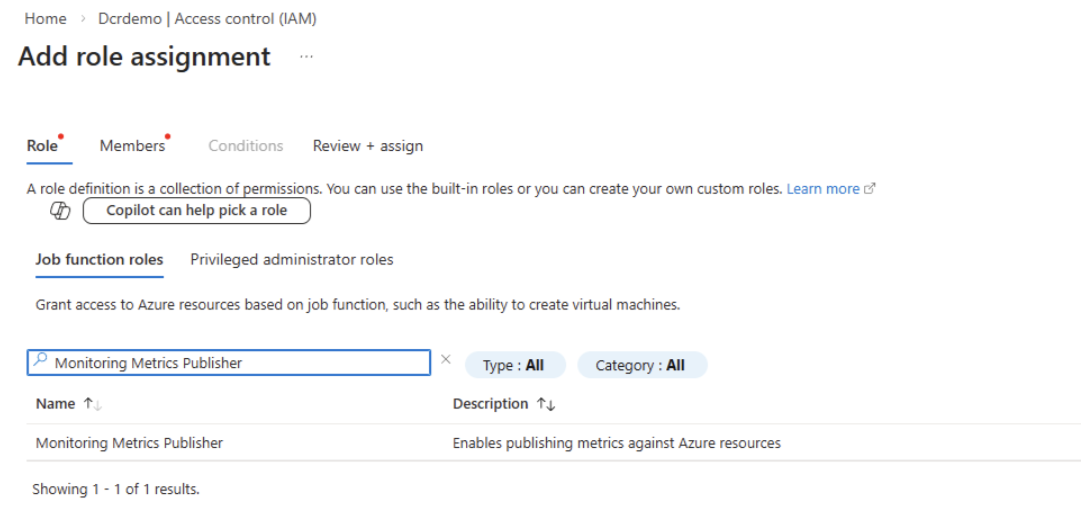
Grant the app the Monitoring Metrics Publisher role on each table's DCR resource. For role assignment steps, see Assign Azure roles using the Azure portal.
Retrieve the stream name and DCR ID. You can retrieve the DCR ID and stream name for each table you created from the Data Collection Rule (DCR) resource JSON view in the Azure portal.
The stream name format is always:
Custom-<Log Analytics table name>. For example, if your table name isAppLogs_CL, the stream name will be:Custom-AppLogs_CL.In the next step, you will configure the corresponding
logStream,eventStream,metricStreamvalues and logDcr , eventDcr, metricDcr values in the Spark configuration using these stream names.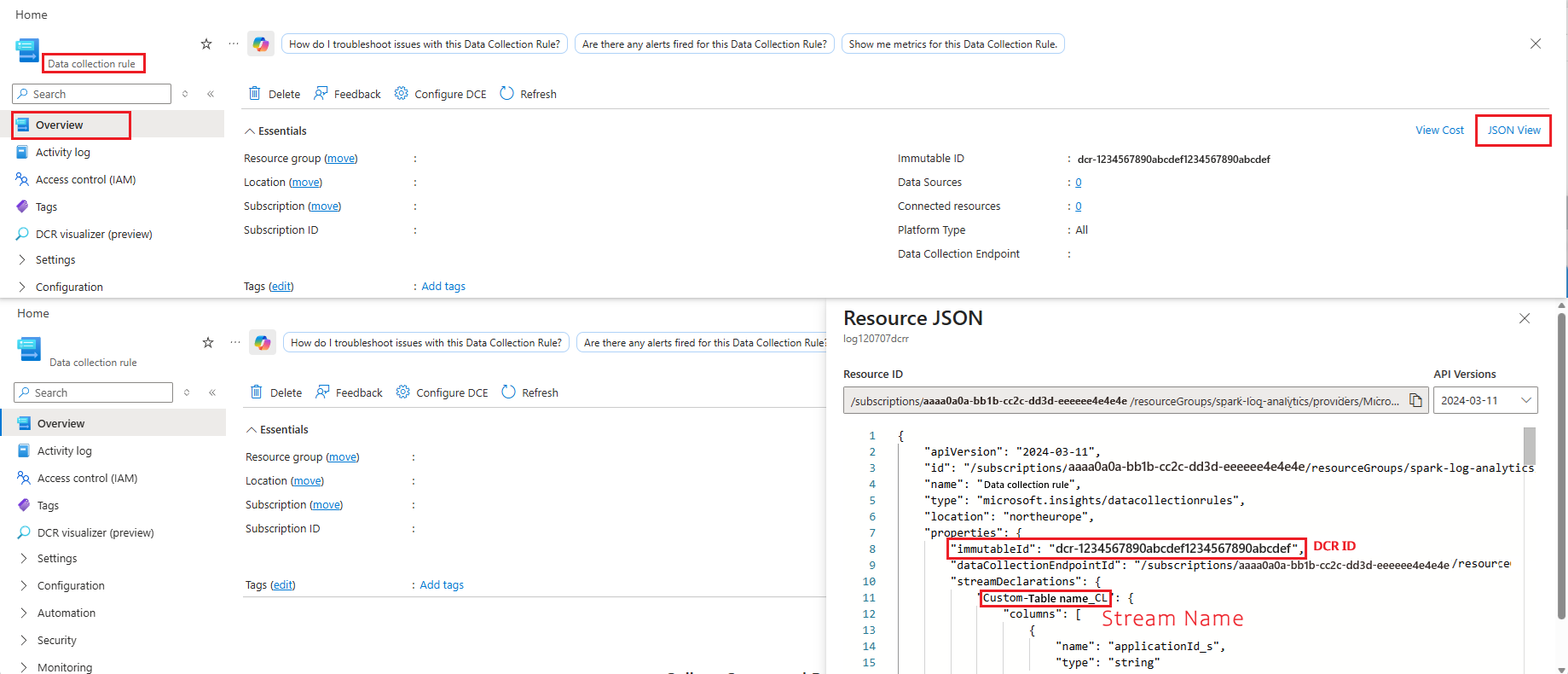



Step 6. Configure Spark properties
To configure Spark, create an Apache Spark Configuration in Azure Synapse Analytics and choose one of the following authentication options. Use only one option for a given emitter.
An Apache Spark Configuration in Azure Synapse Analytics stores Spark settings and libraries that notebooks and Spark job definitions use at runtime. For steps to create one, see Manage Apache Spark configuration.
- Choose Option 1 if you want a simpler setup by using a client secret.
- Choose Option 2 if your organization requires certificate-based authentication and centralized certificate management in Azure Key Vault.
- Choose Option 3 if you use certificate-based authentication and want to retrieve the certificate from Azure Key Vault through a Synapse linked service (workspace MSI accesses Key Vault).
In either option, you can click the Import button to quickly load a configuration YAML file.
Option 1: Configure with service principal and client secret
Use this option for quick setup with service principal credentials and a client secret.
Create an Apache Spark configuration.
Add the following Spark properties with the appropriate values to the environment artifact, or select Import in the ribbon to download the sample yaml file, which already contains the required properties.
spark.synapse.diagnostic.emitters: <EMITTER_NAME> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.type: AzureLogIngestion spark.synapse.diagnostic.emitter.<EMITTER_NAME>.categories: DriverLog,ExecutorLog,EventLog,Metrics spark.synapse.diagnostic.emitter.<EMITTER_NAME>.dceUri: https://<DCE_NAME>.<REGION>.ingest.monitor.azure.com spark.synapse.diagnostic.emitter.<EMITTER_NAME>.logDcr: <LOG_DCR_ID> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.logStream: <LOG_STREAM_NAME> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.eventDcr: <EVENT_DCR_ID> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.eventStream: <EVENT_STREAM_NAME> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.metricDcr: <METRIC_DCR_ID> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.metricStream: <METRIC_STREAM_NAME> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.tenantId: <SP_TENANT_ID> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.clientId: <SP_CLIENT_ID> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.secret: <SP_CLIENT_SECRET>Save and publish the changes.
Option 2: Configure with service principal certificate authentication
Use this option when your organization requires certificate-based authentication.
Before you start, ensure that your service principal is created with a certificate. For more information, see Create a service principal containing a certificate using Azure CLI.
Create an Apache Spark configuration.
Add the following Spark properties with the appropriate values to the environment artifact, or select Import in the ribbon to download the sample yaml file, which already contains the required properties.
spark.synapse.diagnostic.emitters: "<EMITTER_NAME>" spark.synapse.diagnostic.emitter.<EMITTER_NAME>.type: "AzureLogIngestion" spark.synapse.diagnostic.emitter.<EMITTER_NAME>.categories: "DriverLog,ExecutorLog,EventLog,Metrics" spark.synapse.diagnostic.emitter.<EMITTER_NAME>.dceUri: "https://<DCE_NAME>.<REGION>.ingest.monitor.azure.com" spark.synapse.diagnostic.emitter.<EMITTER_NAME>.logDcr: "<LOG_DCR_ID>" spark.synapse.diagnostic.emitter.<EMITTER_NAME>.logStream: "<LOG_STREAM_NAME>" spark.synapse.diagnostic.emitter.<EMITTER_NAME>.eventDcr: "<EVENT_DCR_ID>" spark.synapse.diagnostic.emitter.<EMITTER_NAME>.eventStream: "<EVENT_STREAM_NAME>" spark.synapse.diagnostic.emitter.<EMITTER_NAME>.metricDcr: "<METRIC_DCR_ID>" spark.synapse.diagnostic.emitter.<EMITTER_NAME>.metricStream: "<METRIC_STREAM_NAME>" spark.synapse.diagnostic.emitter.<EMITTER_NAME>.tenantId: "<SP_TENANT_ID>" spark.synapse.diagnostic.emitter.<EMITTER_NAME>.clientId: "<SP_CLIENT_ID>" spark.synapse.diagnostic.emitter.<EMITTER_NAME>.certificate.keyVault: "https://<KEYVAULT_NAME>.vault.azure.net/" spark.synapse.diagnostic.emitter.<EMITTER_NAME>.certificate.keyVault.certificateName: "<SP_CERT_NAME>"Save and publish changes.
Option 3: Configure with a linked service
Note
In this option, you need to grant read certificate permission to workspace managed identity. For more information, see Provide access to Key Vault keys, certificates, and secrets with an Azure role-based access control.
To configure a Key Vault linked service in Synapse Studio to store the service principal certificate, follow these steps:
Follow all the steps in the preceding section, "Option 2."
Create a Key Vault linked service in Synapse Studio:
a. Go to Synapse Studio > Manage > Linked services, and then select New.
b. In the search box, search for Azure Key Vault.
c. Enter a name for the linked service.
d. Choose your key vault, and select Create.
Add a
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.certificate.keyVault.linkedServiceitem to the Apache Spark configuration.Add the following Spark properties with the appropriate values to the spark configuration, or select Import in the ribbon to download the sample yaml file, which already contains the required properties.
spark.synapse.diagnostic.emitters: <EMITTER_NAME>
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.type: AzureLogIngestion
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.categories: DriverLog,ExecutorLog,EventLog,Metrics
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.dceUri: https://<DCE_NAME>.<REGION>.ingest.monitor.azure.com
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.logDcr: <LOG_DCR_ID>
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.logStream: <LOG_STREAM_NAME>
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.eventDcr: <EVENT_DCR_ID>
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.eventStream: <EVENT_STREAM_NAME>
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.metricDcr: <METRIC_DCR_ID>
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.metricStream: <METRIC_STREAM_NAME>
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.tenantId: <SP_TENANT_ID>
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.clientId: <SP_CLIENT_ID>
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.certificate.keyVault: https://<KEYVAULT_NAME>.vault.azure.net/
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.certificate.keyVault.certificateName: <SP_CERT_NAME>
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.certificate.keyVault.linkedService: <AZURE_KEY_VAULT_LINKED_SERVICE>
For a list of Apache Spark configurations, see Available Apache Spark configurations
Step 7. Attach the Apache Spark configuration to notebooks or Spark job definitions, or set it as the workspace default
Use one of the following approaches based on your scope:
- Attach the Apache Spark configuration to specific notebooks or Spark job definitions when you want targeted rollout, testing, or per-item control.
- Set the Apache Spark configuration as the workspace default when you want consistent Spark diagnostics settings applied across the workspace.
To apply the configuration to notebooks or Spark job definition:
- Navigate to your notebook or Spark job definition in Azure Synapse Analytics Studio.
- Select or configure the target Apache Spark pool associated with the notebook or Spark job definition.
- Ensure the required Spark configurations (for example, Log Ingestion settings) are applied to the Apache Spark pool or session.
- Start or run the Spark session for the configuration to take effect.
To configure the settings at the workspace or Apache Spark pool level:
- Navigate to Manage in Azure Synapse Studio.
- Go to Apache Spark pools and select the target Apache Spark pool.
- Configure the required Spark settings (for example, diagnostics or log ingestion-related properties).
- Save the configuration. The settings will apply to all new Spark sessions created in this pool.
Step 8. Submit an Apache Spark application and view the logs and metrics
Here's how:
Submit an Apache Spark application to the Apache Spark pool configured in the previous step. You can use any of the following ways to do so:
- Run a notebook in Synapse Studio.
- In Synapse Studio, submit an Apache Spark batch job through an Apache Spark job definition.
- Run a pipeline that contains Apache Spark activity.
Go to the specified Log Analytics workspace, and then view the application metrics and logs when the Apache Spark application starts to run.
Write custom application logs
You can use the Apache Log4j library to write custom logs.
Example for Scala:
%%spark
val logger = org.apache.log4j.LogManager.getLogger("com.contoso.LoggerExample")
logger.info("info message")
logger.warn("warn message")
logger.error("error message")
//log exception
try {
1/0
} catch {
case e:Exception =>logger.warn("Exception", e)
}
// run job for task level metrics
val data = sc.parallelize(Seq(1,2,3,4)).toDF().count()
Example for PySpark:
%%pyspark
logger = sc._jvm.org.apache.log4j.LogManager.getLogger("com.contoso.PythonLoggerExample")
logger.info("info message")
logger.warn("warn message")
logger.error("error message")
Query data with Kusto
The following is an example of querying Apache Spark events:
SparkEventTest_CL
| where workspaceName_s == "{SynapseWorkspace}" and Event_s== "EventName"
| order by TimeGenerated desc
| limit 100
Here's an example of querying the Apache Spark application driver and executors logs:
SparkLogTest_CL
| where workspaceName_s == "{SynapseWorkspace}" and Message contains "SampleMessage"
| order by TimeGenerated desc
| limit 100
And here's an example of querying Apache Spark metrics:
SparkMetricsTest_CL
| where workspaceName_s == "{SynapseWorkspace}" and name_s== "{MetricsName}"
| order by TimeGenerated desc
| limit 100
Create and manage alerts
Users can query to evaluate metrics and logs at a set frequency, and fire an alert based on the results. For more information, see Create, view, and manage log alerts by using Azure Monitor.
Synapse workspace with data exfiltration protection enabled
After the Synapse workspace is created with data exfiltration protection enabled.
When you want to enable this feature, you need to create managed private endpoint connection requests to Azure Monitor private link scopes (AMPLS) in the workspace’s approved Microsoft Entra tenants.
You can follow below steps to create a managed private endpoint connection to Azure Monitor private link scopes (AMPLS):
- If there's no existing AMPLS, you can follow Azure Monitor Private Link connection setup to create one.
- Navigate to your AMPLS in Azure portal, on the Azure Monitor Resources page, select Add to add connection to your Azure Log Analytics workspace.
- Navigate to Synapse Studio > Manage > Managed private endpoints, select New button, select Azure Monitor Private Link Scopes, and continue.
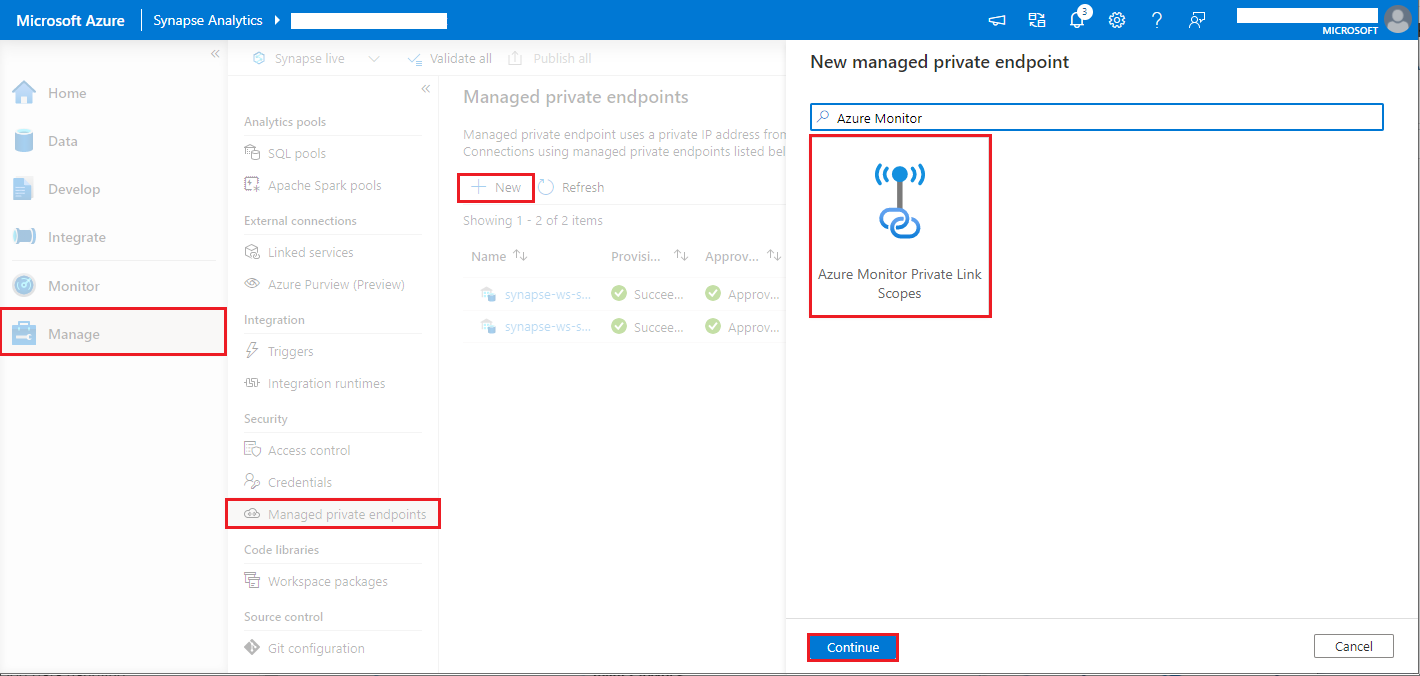
- Choose your Azure Monitor Private Link Scope you created, and select Create button.
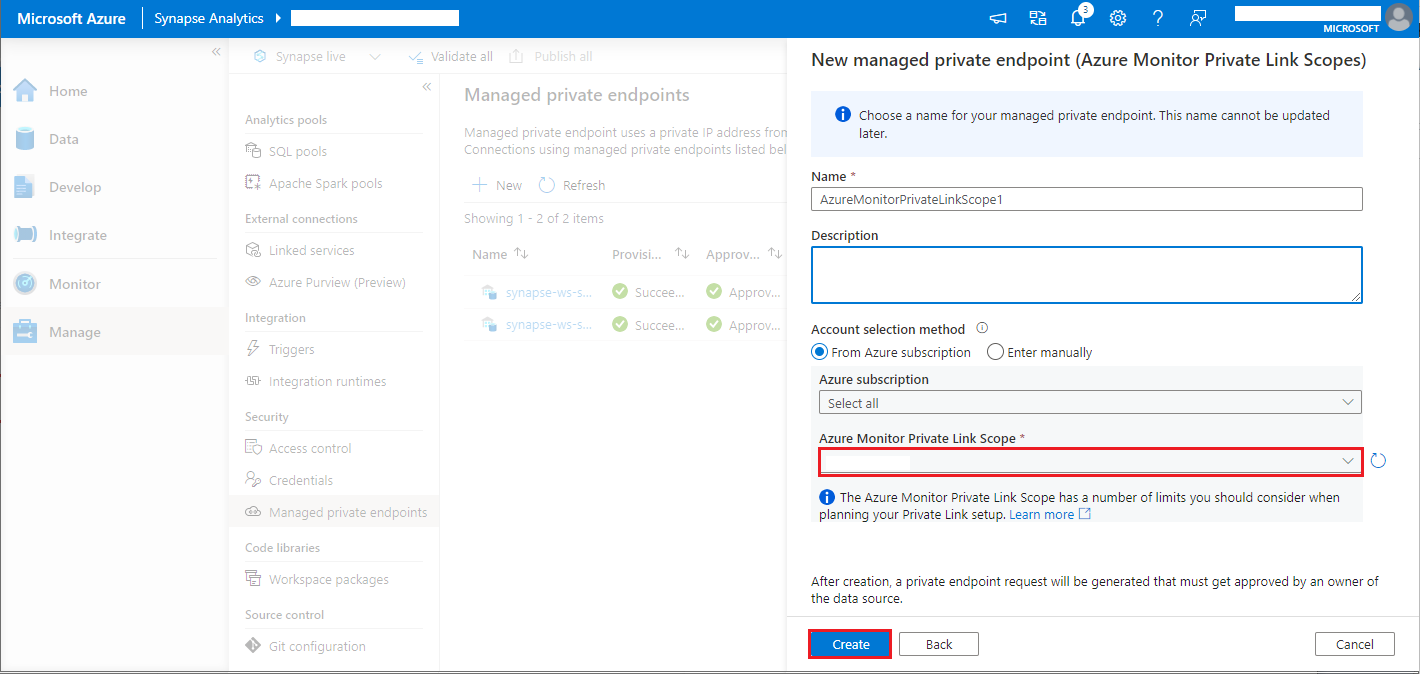
- Wait a few minutes for private endpoint provisioning.
- Navigate to your AMPLS in Azure portal again, on the Private Endpoint connections page, select the connection provisioned and Approve.
Note
- The AMPLS object has many limits you should consider when planning your Private Link setup. See AMPLS limits for a deeper review of these limits.
- Check if you have right permission to create managed private endpoint.
Available configurations
| Configuration | Description |
|---|---|
spark.synapse.diagnostic.emitters |
The comma-separated destination names of diagnostic emitters. For example, MyDest1,MyDest2. |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.type |
Built-in destination type. To enable Azure Log Analytics via Log Ingestion API, set this value to AzureLogIngestion. |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.categories |
The comma-separated selected log categories. Available values include DriverLog, ExecutorLog, EventLog, Metrics. If not set, the default value is all categories. |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.dceUri |
The Data Collection Endpoint (DCE) URI used for ingestion when routing data via Data Collection Rules (DCRs). |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.logDcr |
The Data Collection Rule (DCR) resource ID used to route Spark logs to the destination. |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.logStream |
The stream name defined in the Data Collection Rule (DCR) for Spark logs. |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.eventDcr |
The Data Collection Rule (DCR) resource ID used to route Spark event logs. |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.eventStream |
The stream name defined in the Data Collection Rule (DCR) for Spark event logs. |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.metricDcr |
The Data Collection Rule (DCR) resource ID used to route Spark metrics. |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.metricStream |
The stream name defined in the Data Collection Rule (DCR) for Spark metrics. |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.tenantId |
The Microsoft Entra tenant ID used for authentication. |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.clientId |
The client (application) ID registered in Microsoft Entra ID. |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.secret |
The client secret associated with the Microsoft Entra ID application, used together with the tenant ID and client ID to authenticate the emitter when sending diagnostic data. This setting is mutually exclusive with certificate-based authentication—configure either the client secret or the certificate, but not both. |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.certificate.keyVault |
The Azure Key Vault URI that stores the authentication certificate. |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.certificate.keyVault.certificateName |
The name of the certificate stored in Azure Key Vault, used for authentication. |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.certificate.keyVault.linkedService |
The Azure Key Vault linked service name in Synapse. When specified, the workspace managed identity uses this linked service to retrieve the certificate from Azure Key Vault. |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.filter.eventName.match |
The comma-separated Spark listener event names; you can specify which events to collect. For example, SparkListenerApplicationStart,SparkListenerApplicationEnd. |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.filter.loggerName.match |
The comma-separated Log4j logger names; you can specify which logs to collect. For example, org.apache.spark.SparkContext,org.example.Logger. |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.filter.metricName.match |
The comma-separated Spark metric name suffixes; you can specify which metrics to collect. For example, jvm.heap.used. |
Note
Authentication is mutually exclusive: configure one of secret (plain text) or certificate.keyVault + certificate.keyVault.certificateName (optionally with certificate.keyVault.linkedService).
Retrieving the client secret from Azure Key Vault (with or without a linked service) is not supported by the Log Ingestion destination. If you need to keep credentials in Key Vault, use the certificate-based path.