Quickstart: Recognize intents with the Speech service and LUIS
Important
LUIS will be retired on October 1st 2025. As of April 1st 2023 you can't create new LUIS resources. We recommend migrating your LUIS applications to conversational language understanding to benefit from continued product support and multilingual capabilities.
Conversational Language Understanding (CLU) is available for C# and C++ with the Speech SDK version 1.25 or later. See the quickstart to recognize intents with the Speech SDK and CLU.
Reference documentation | Package (NuGet) | Additional samples on GitHub
In this quickstart, you'll use the Speech SDK and the Language Understanding (LUIS) service to recognize intents from audio data captured from a microphone. Specifically, you'll use the Speech SDK to capture speech, and a prebuilt domain from LUIS to identify intents for home automation, like turning on and off a light.
Prerequisites
- Azure subscription - Create one for free
- Create a Language resource in the Azure portal. You can use the free pricing tier (
F0) to try the service, and upgrade later to a paid tier for production. You won't need a Speech resource this time. - Get the Language resource key and region. After your Language resource is deployed, select Go to resource to view and manage keys.
Create a LUIS app for intent recognition
To complete the intent recognition quickstart, you'll need to create a LUIS account and a project using the LUIS preview portal. This quickstart requires a LUIS subscription in a region where intent recognition is available. A Speech service subscription isn't required.
The first thing you'll need to do is create a LUIS account and app using the LUIS preview portal. The LUIS app that you create will use a prebuilt domain for home automation, which provides intents, entities, and example utterances. When you're finished, you'll have a LUIS endpoint running in the cloud that you can call using the Speech SDK.
Follow these instructions to create your LUIS app:
When you're done, you'll need four things:
- Re-publish with Speech priming toggled on
- Your LUIS Primary key
- Your LUIS Location
- Your LUIS App ID
Here's where you can find this information in the LUIS preview portal:
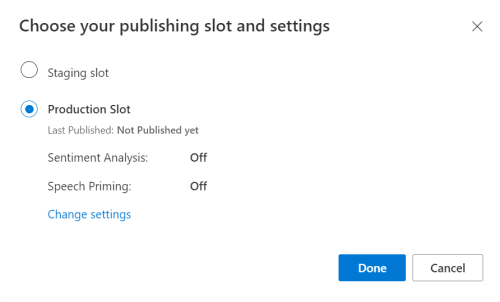
From the LUIS preview portal, select your app then select the Publish button.
Select the Production slot, if you're using
en-USselect change settings, and toggle the Speech priming option to the On position. Then select the Publish button.Important
Speech priming is highly recommended as it will improve speech recognition accuracy.
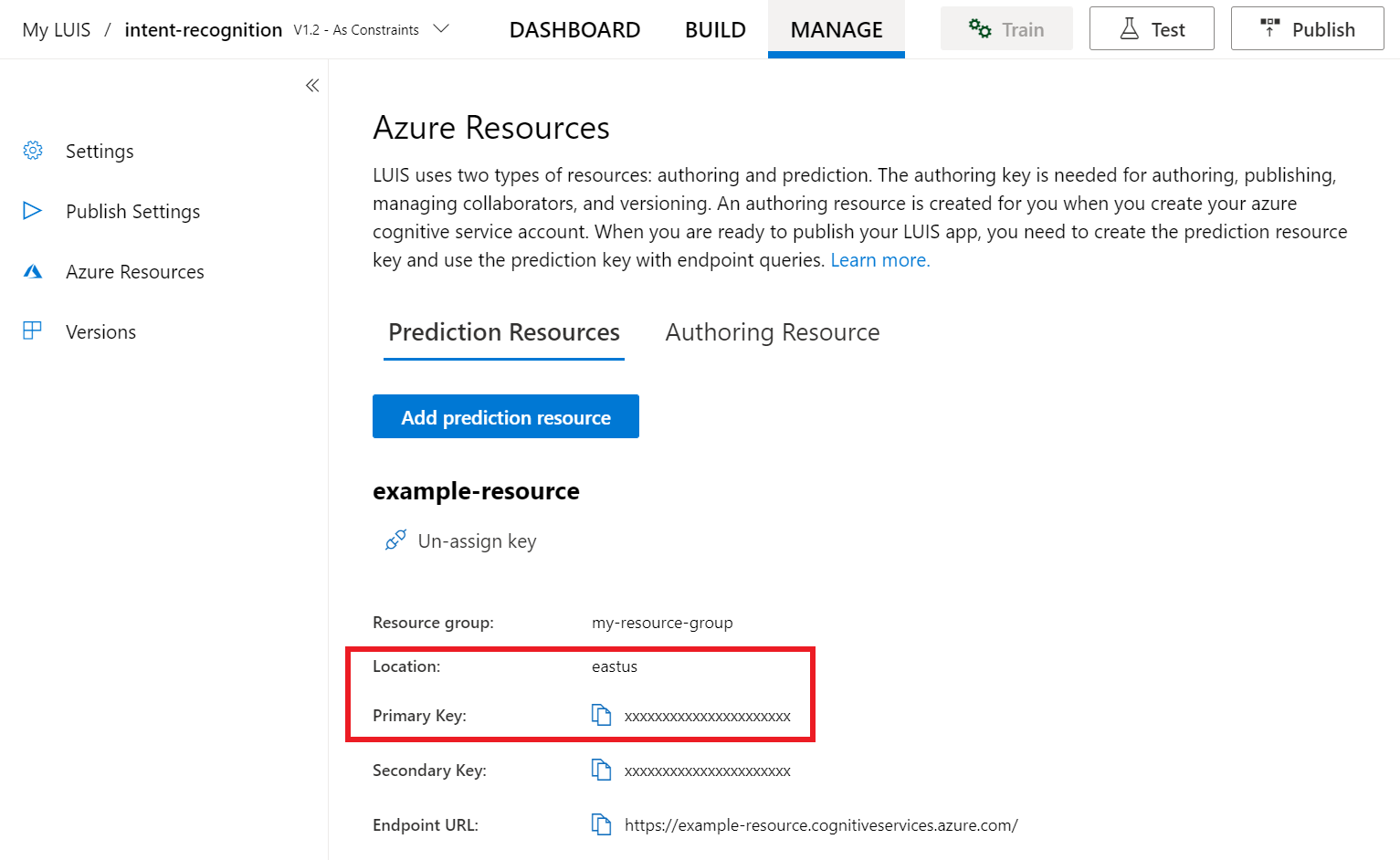
From the LUIS preview portal, select Manage, then select Azure Resources. On this page, you'll find your LUIS key and location (sometimes referred to as region) for your LUIS prediction resource.
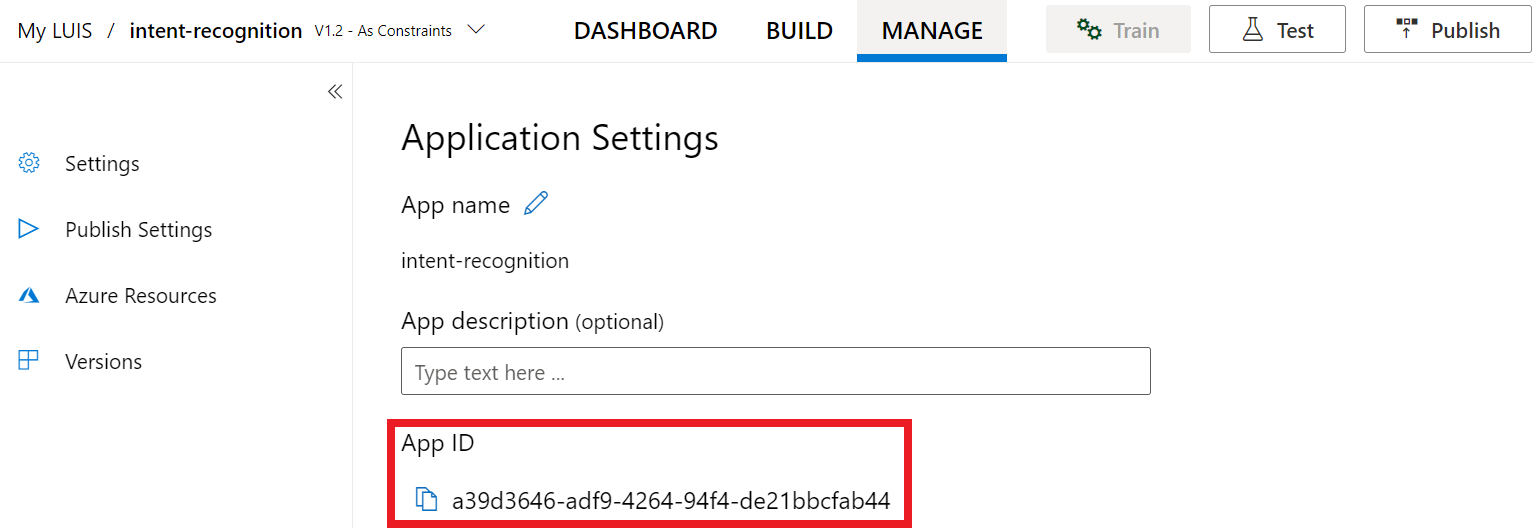
After you've got your key and location, you'll need the app ID. Select Settings. your app ID is available on this page.
Open your project in Visual Studio
Next, open your project in Visual Studio.
- Launch Visual Studio 2019.
- Load your project and open
Program.cs.
Start with some boilerplate code
Let's add some code that works as a skeleton for our project. Make note that you've created an async method called RecognizeIntentAsync().
using System;
using System.Threading.Tasks;
using Microsoft.CognitiveServices.Speech;
using Microsoft.CognitiveServices.Speech.Intent;
namespace helloworld
{
class Program
{
public static async Task RecognizeIntentAsync()
{
}
static async Task Main()
{
await RecognizeIntentAsync();
Console.WriteLine("Please press <Return> to continue.");
Console.ReadLine();
}
}
}
Create a Speech configuration
Before you can initialize an IntentRecognizer object, you need to create a configuration that uses the key and location for your LUIS prediction resource.
Important
Your starter key and authoring keys will not work. You must use your prediction key and location that you created earlier. For more information, see Create a LUIS app for intent recognition.
Insert this code in the RecognizeIntentAsync() method. Make sure you update these values:
- Replace
"YourLanguageUnderstandingSubscriptionKey"with your LUIS prediction key. - Replace
"YourLanguageUnderstandingServiceRegion"with your LUIS location. Use Region identifier from region.
Tip
If you need help finding these values, see Create a LUIS app for intent recognition.
Important
Remember to remove the key from your code when you're done, and never post it publicly. For production, use a secure way of storing and accessing your credentials like Azure Key Vault. See the Azure AI services security article for more information.
var config = SpeechConfig.FromSubscription(
"YourLanguageUnderstandingSubscriptionKey",
"YourLanguageUnderstandingServiceRegion");
This sample uses the FromSubscription() method to build the SpeechConfig. For a full list of available methods, see SpeechConfig Class.
The Speech SDK will default to recognizing using en-us for the language, see How to recognize speech for information on choosing the source language.
Initialize an IntentRecognizer
Now, let's create an IntentRecognizer. This object is created inside of a using statement to ensure the proper release of unmanaged resources. Insert this code in the RecognizeIntentAsync() method, right below your Speech configuration.
// Creates an intent recognizer using microphone as audio input.
using (var recognizer = new IntentRecognizer(config))
{
}
Add a LanguageUnderstandingModel and intents
You need to associate a LanguageUnderstandingModel with the intent recognizer, and add the intents that you want recognized. We're going to use intents from the prebuilt domain for home automation. Insert this code in the using statement from the previous section. Make sure that you replace "YourLanguageUnderstandingAppId" with your LUIS app ID.
Tip
If you need help finding this value, see Create a LUIS app for intent recognition.
// Creates a Language Understanding model using the app id, and adds specific intents from your model
var model = LanguageUnderstandingModel.FromAppId("YourLanguageUnderstandingAppId");
recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName1", "id1");
recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName2", "id2");
recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName3", "any-IntentId-here");
This example uses the AddIntent() function to individually add intents. If you want to add all intents from a model, use AddAllIntents(model) and pass the model.
Recognize an intent
From the IntentRecognizer object, you're going to call the RecognizeOnceAsync() method. This method lets the Speech service know that you're sending a single phrase for recognition, and that once the phrase is identified to stop recognizing speech.
Inside the using statement, add this code below your model.
// Starts recognizing.
Console.WriteLine("Say something...");
// Starts intent recognition, and returns after a single utterance is recognized. The end of a
// single utterance is determined by listening for silence at the end or until a maximum of about 30
// seconds of audio is processed. The task returns the recognition text as result.
// Note: Since RecognizeOnceAsync() returns only a single utterance, it is suitable only for single
// shot recognition like command or query.
// For long-running multi-utterance recognition, use StartContinuousRecognitionAsync() instead.
var result = await recognizer.RecognizeOnceAsync();
Display recognition results (or errors)
When the recognition result is returned by the Speech service, you'll want to do something with it. We're going to keep it simple and print the results to console.
Inside the using statement, below RecognizeOnceAsync(), add this code:
// Checks result.
switch (result.Reason)
{
case ResultReason.RecognizedIntent:
Console.WriteLine($"RECOGNIZED: Text={result.Text}");
Console.WriteLine($" Intent Id: {result.IntentId}.");
var json = result.Properties.GetProperty(PropertyId.LanguageUnderstandingServiceResponse_JsonResult);
Console.WriteLine($" Language Understanding JSON: {json}.");
break;
case ResultReason.RecognizedSpeech:
Console.WriteLine($"RECOGNIZED: Text={result.Text}");
Console.WriteLine($" Intent not recognized.");
break;
case ResultReason.NoMatch:
Console.WriteLine($"NOMATCH: Speech could not be recognized.");
break;
case ResultReason.Canceled:
var cancellation = CancellationDetails.FromResult(result);
Console.WriteLine($"CANCELED: Reason={cancellation.Reason}");
if (cancellation.Reason == CancellationReason.Error)
{
Console.WriteLine($"CANCELED: ErrorCode={cancellation.ErrorCode}");
Console.WriteLine($"CANCELED: ErrorDetails={cancellation.ErrorDetails}");
Console.WriteLine($"CANCELED: Did you update the subscription info?");
}
break;
}
Check your code
At this point, your code should look like this:
Note
We've added some comments to this version.
//
// Copyright (c) Microsoft. All rights reserved.
// Licensed under the MIT license. See LICENSE.md file in the project root for full license information.
//
// <skeleton_1>
using System;
using System.Threading.Tasks;
using Microsoft.CognitiveServices.Speech;
using Microsoft.CognitiveServices.Speech.Intent;
namespace helloworld
{
class Program
{
public static async Task RecognizeIntentAsync()
{
// </skeleton_1>
// Creates an instance of a speech config with specified subscription key
// and service region. Note that in contrast to other services supported by
// the Cognitive Services Speech SDK, the Language Understanding service
// requires a specific subscription key from https://www.luis.ai/.
// The Language Understanding service calls the required key 'endpoint key'.
// Once you've obtained it, replace with below with your own Language Understanding subscription key
// and service region (e.g., "westus").
// The default language is "en-us".
// <create_speech_configuration>
var config = SpeechConfig.FromSubscription(
"YourLanguageUnderstandingSubscriptionKey",
"YourLanguageUnderstandingServiceRegion");
// </create_speech_configuration>
// <create_intent_recognizer_1>
// Creates an intent recognizer using microphone as audio input.
using (var recognizer = new IntentRecognizer(config))
{
// </create_intent_recognizer_1>
// <add_intents>
// Creates a Language Understanding model using the app id, and adds specific intents from your model
var model = LanguageUnderstandingModel.FromAppId("YourLanguageUnderstandingAppId");
recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName1", "id1");
recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName2", "id2");
recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName3", "any-IntentId-here");
// </add_intents>
// To add all of the possible intents from a LUIS model to the recognizer, uncomment the line below:
// recognizer.AddAllIntents(model);
// <recognize_intent>
// Starts recognizing.
Console.WriteLine("Say something...");
// Starts intent recognition, and returns after a single utterance is recognized. The end of a
// single utterance is determined by listening for silence at the end or until a maximum of about 30
// seconds of audio is processed. The task returns the recognition text as result.
// Note: Since RecognizeOnceAsync() returns only a single utterance, it is suitable only for single
// shot recognition like command or query.
// For long-running multi-utterance recognition, use StartContinuousRecognitionAsync() instead.
var result = await recognizer.RecognizeOnceAsync();
// </recognize_intent>
// <print_results>
// Checks result.
switch (result.Reason)
{
case ResultReason.RecognizedIntent:
Console.WriteLine($"RECOGNIZED: Text={result.Text}");
Console.WriteLine($" Intent Id: {result.IntentId}.");
var json = result.Properties.GetProperty(PropertyId.LanguageUnderstandingServiceResponse_JsonResult);
Console.WriteLine($" Language Understanding JSON: {json}.");
break;
case ResultReason.RecognizedSpeech:
Console.WriteLine($"RECOGNIZED: Text={result.Text}");
Console.WriteLine($" Intent not recognized.");
break;
case ResultReason.NoMatch:
Console.WriteLine($"NOMATCH: Speech could not be recognized.");
break;
case ResultReason.Canceled:
var cancellation = CancellationDetails.FromResult(result);
Console.WriteLine($"CANCELED: Reason={cancellation.Reason}");
if (cancellation.Reason == CancellationReason.Error)
{
Console.WriteLine($"CANCELED: ErrorCode={cancellation.ErrorCode}");
Console.WriteLine($"CANCELED: ErrorDetails={cancellation.ErrorDetails}");
Console.WriteLine($"CANCELED: Did you update the subscription info?");
}
break;
}
// </print_results>
// <create_intent_recognizer_2>
}
// </create_intent_recognizer_2>
// <skeleton_2>
}
static async Task Main()
{
await RecognizeIntentAsync();
Console.WriteLine("Please press <Return> to continue.");
Console.ReadLine();
}
}
}
// </skeleton_2>
Build and run your app
Now you're ready to build your app and test our speech recognition using the Speech service.
- Compile the code - From the menu bar of Visual Studio, choose Build > Build Solution.
- Start your app - From the menu bar, choose Debug > Start Debugging or press F5.
- Start recognition - It'll prompt you to speak a phrase in English. Your speech is sent to the Speech service, transcribed as text, and rendered in the console.
Reference documentation | Package (NuGet) | Additional samples on GitHub
In this quickstart, you'll use the Speech SDK and the Language Understanding (LUIS) service to recognize intents from audio data captured from a microphone. Specifically, you'll use the Speech SDK to capture speech, and a prebuilt domain from LUIS to identify intents for home automation, like turning on and off a light.
Prerequisites
- Azure subscription - Create one for free
- Create a Language resource in the Azure portal. You can use the free pricing tier (
F0) to try the service, and upgrade later to a paid tier for production. You won't need a Speech resource this time. - Get the Language resource key and region. After your Language resource is deployed, select Go to resource to view and manage keys.
Create a LUIS app for intent recognition
To complete the intent recognition quickstart, you'll need to create a LUIS account and a project using the LUIS preview portal. This quickstart requires a LUIS subscription in a region where intent recognition is available. A Speech service subscription isn't required.
The first thing you'll need to do is create a LUIS account and app using the LUIS preview portal. The LUIS app that you create will use a prebuilt domain for home automation, which provides intents, entities, and example utterances. When you're finished, you'll have a LUIS endpoint running in the cloud that you can call using the Speech SDK.
Follow these instructions to create your LUIS app:
When you're done, you'll need four things:
- Re-publish with Speech priming toggled on
- Your LUIS Primary key
- Your LUIS Location
- Your LUIS App ID
Here's where you can find this information in the LUIS preview portal:
From the LUIS preview portal, select your app then select the Publish button.
Select the Production slot, if you're using
en-USselect change settings, and toggle the Speech priming option to the On position. Then select the Publish button.Important
Speech priming is highly recommended as it will improve speech recognition accuracy.
From the LUIS preview portal, select Manage, then select Azure Resources. On this page, you'll find your LUIS key and location (sometimes referred to as region) for your LUIS prediction resource.
After you've got your key and location, you'll need the app ID. Select Settings. your app ID is available on this page.
Open your project in Visual Studio
Next, open your project in Visual Studio.
- Launch Visual Studio 2019.
- Load your project and open
helloworld.cpp.
Start with some boilerplate code
Let's add some code that works as a skeleton for our project. Make note that you've created an async method called recognizeIntent().
#include "stdafx.h"
#include <iostream>
#include <speechapi_cxx.h>
using namespace std;
using namespace Microsoft::CognitiveServices::Speech;
using namespace Microsoft::CognitiveServices::Speech::Intent;
void recognizeIntent()
{
}
int wmain()
{
try
{
recognizeIntent();
}
catch (exception e)
{
cout << e.what();
}
cout << "Please press a key to continue.\n";
cin.get();
return 0;
}
Create a Speech configuration
Before you can initialize an IntentRecognizer object, you need to create a configuration that uses the key and location for your LUIS prediction resource.
Important
Your starter key and authoring keys will not work. You must use your prediction key and location that you created earlier. For more information, see Create a LUIS app for intent recognition.
Insert this code in the recognizeIntent() method. Make sure you update these values:
- Replace
"YourLanguageUnderstandingSubscriptionKey"with your LUIS prediction key. - Replace
"YourLanguageUnderstandingServiceRegion"with your LUIS location. Use Region identifier from region.
Tip
If you need help finding these values, see Create a LUIS app for intent recognition.
Important
Remember to remove the key from your code when you're done, and never post it publicly. For production, use a secure way of storing and accessing your credentials like Azure Key Vault. See the Azure AI services security article for more information.
auto config = SpeechConfig::FromSubscription(
"YourLanguageUnderstandingSubscriptionKey",
"YourLanguageUnderstandingServiceRegion");
This sample uses the FromSubscription() method to build the SpeechConfig. For a full list of available methods, see SpeechConfig Class.
The Speech SDK will default to recognizing using en-us for the language, see How to recognize speech for information on choosing the source language.
Initialize an IntentRecognizer
Now, let's create an IntentRecognizer. Insert this code in the recognizeIntent() method, right below your Speech configuration.
// Creates an intent recognizer using microphone as audio input.
auto recognizer = IntentRecognizer::FromConfig(config);
Add a LanguageUnderstandingModel and Intents
You need to associate a LanguageUnderstandingModel with the intent recognizer, and add the intents you want recognized. We're going to use intents from the prebuilt domain for home automation.
Insert this code below your IntentRecognizer. Make sure that you replace "YourLanguageUnderstandingAppId" with your LUIS app ID.
Tip
If you need help finding this value, see Create a LUIS app for intent recognition.
// Creates a Language Understanding model using the app id, and adds specific intents from your model
auto model = LanguageUnderstandingModel::FromAppId("YourLanguageUnderstandingAppId");
recognizer->AddIntent(model, "YourLanguageUnderstandingIntentName1", "id1");
recognizer->AddIntent(model, "YourLanguageUnderstandingIntentName2", "id2");
recognizer->AddIntent(model, "YourLanguageUnderstandingIntentName3", "any-IntentId-here");
This example uses the AddIntent() function to individually add intents. If you want to add all intents from a model, use AddAllIntents(model) and pass the model.
Recognize an intent
From the IntentRecognizer object, you're going to call the RecognizeOnceAsync() method. This method lets the Speech service know that you're sending a single phrase for recognition, and that once the phrase is identified to stop recognizing speech. For simplicity we'll wait on the future returned to complete.
Insert this code below your model:
cout << "Say something...\n";
// Starts intent recognition, and returns after a single utterance is recognized. The end of a
// single utterance is determined by listening for silence at the end or until a maximum of about 30
// seconds of audio is processed. The task returns the recognition text as result.
// Note: Since RecognizeOnceAsync() returns only a single utterance, it is suitable only for single
// shot recognition like command or query.
// For long-running multi-utterance recognition, use StartContinuousRecognitionAsync() instead.
auto result = recognizer->RecognizeOnceAsync().get();
Display the recognition results (or errors)
When the recognition result is returned by the Speech service, you'll want to do something with it. We're going to keep it simple and print the result to console.
Insert this code below auto result = recognizer->RecognizeOnceAsync().get();:
// Checks result.
if (result->Reason == ResultReason::RecognizedIntent)
{
cout << "RECOGNIZED: Text=" << result->Text << std::endl;
cout << " Intent Id: " << result->IntentId << std::endl;
cout << " Intent Service JSON: " << result->Properties.GetProperty(PropertyId::LanguageUnderstandingServiceResponse_JsonResult) << std::endl;
}
else if (result->Reason == ResultReason::RecognizedSpeech)
{
cout << "RECOGNIZED: Text=" << result->Text << " (intent could not be recognized)" << std::endl;
}
else if (result->Reason == ResultReason::NoMatch)
{
cout << "NOMATCH: Speech could not be recognized." << std::endl;
}
else if (result->Reason == ResultReason::Canceled)
{
auto cancellation = CancellationDetails::FromResult(result);
cout << "CANCELED: Reason=" << (int)cancellation->Reason << std::endl;
if (cancellation->Reason == CancellationReason::Error)
{
cout << "CANCELED: ErrorCode=" << (int)cancellation->ErrorCode << std::endl;
cout << "CANCELED: ErrorDetails=" << cancellation->ErrorDetails << std::endl;
cout << "CANCELED: Did you update the subscription info?" << std::endl;
}
}
Check your code
At this point, your code should look like this:
Note
We've added some comments to this version.
//
// Copyright (c) Microsoft. All rights reserved.
// Licensed under the MIT license. See LICENSE.md file in the project root for full license information.
//
// <skeleton_1>
#include "stdafx.h"
#include <iostream>
#include <speechapi_cxx.h>
using namespace std;
using namespace Microsoft::CognitiveServices::Speech;
using namespace Microsoft::CognitiveServices::Speech::Intent;
void recognizeIntent()
{
// </skeleton_1>
// Creates an instance of a speech config with specified subscription key
// and service region. Note that in contrast to other services supported by
// the Cognitive Services Speech SDK, the Language Understanding service
// requires a specific subscription key from https://www.luis.ai/.
// The Language Understanding service calls the required key 'endpoint key'.
// Once you've obtained it, replace with below with your own Language Understanding subscription key
// and service region (e.g., "westus").
// The default recognition language is "en-us".
// <create_speech_configuration>
auto config = SpeechConfig::FromSubscription(
"YourLanguageUnderstandingSubscriptionKey",
"YourLanguageUnderstandingServiceRegion");
// </create_speech_configuration>
// <create_intent_recognizer>
// Creates an intent recognizer using microphone as audio input.
auto recognizer = IntentRecognizer::FromConfig(config);
// </create_intent_recognizer>
// <add_intents>
// Creates a Language Understanding model using the app id, and adds specific intents from your model
auto model = LanguageUnderstandingModel::FromAppId("YourLanguageUnderstandingAppId");
recognizer->AddIntent(model, "YourLanguageUnderstandingIntentName1", "id1");
recognizer->AddIntent(model, "YourLanguageUnderstandingIntentName2", "id2");
recognizer->AddIntent(model, "YourLanguageUnderstandingIntentName3", "any-IntentId-here");
// </add_intents>
// To add all of the possible intents from a LUIS model to the recognizer, uncomment the line below:
// recognizer->AddAllIntents(model);
// <recognize_intent>
cout << "Say something...\n";
// Starts intent recognition, and returns after a single utterance is recognized. The end of a
// single utterance is determined by listening for silence at the end or until a maximum of about 30
// seconds of audio is processed. The task returns the recognition text as result.
// Note: Since RecognizeOnceAsync() returns only a single utterance, it is suitable only for single
// shot recognition like command or query.
// For long-running multi-utterance recognition, use StartContinuousRecognitionAsync() instead.
auto result = recognizer->RecognizeOnceAsync().get();
// </recognize_intent>
// <print_results>
// Checks result.
if (result->Reason == ResultReason::RecognizedIntent)
{
cout << "RECOGNIZED: Text=" << result->Text << std::endl;
cout << " Intent Id: " << result->IntentId << std::endl;
cout << " Intent Service JSON: " << result->Properties.GetProperty(PropertyId::LanguageUnderstandingServiceResponse_JsonResult) << std::endl;
}
else if (result->Reason == ResultReason::RecognizedSpeech)
{
cout << "RECOGNIZED: Text=" << result->Text << " (intent could not be recognized)" << std::endl;
}
else if (result->Reason == ResultReason::NoMatch)
{
cout << "NOMATCH: Speech could not be recognized." << std::endl;
}
else if (result->Reason == ResultReason::Canceled)
{
auto cancellation = CancellationDetails::FromResult(result);
cout << "CANCELED: Reason=" << (int)cancellation->Reason << std::endl;
if (cancellation->Reason == CancellationReason::Error)
{
cout << "CANCELED: ErrorCode=" << (int)cancellation->ErrorCode << std::endl;
cout << "CANCELED: ErrorDetails=" << cancellation->ErrorDetails << std::endl;
cout << "CANCELED: Did you update the subscription info?" << std::endl;
}
}
// </print_results>
// <skeleton_2>
}
int wmain()
{
try
{
recognizeIntent();
}
catch (exception e)
{
cout << e.what();
}
cout << "Please press a key to continue.\n";
cin.get();
return 0;
}
// </skeleton_2>
Build and run your app
Now you're ready to build your app and test our speech recognition using the Speech service.
- Compile the code - From the menu bar of Visual Studio, choose Build > Build Solution.
- Start your app - From the menu bar, choose Debug > Start Debugging or press F5.
- Start recognition - It'll prompt you to speak a phrase in English. Your speech is sent to the Speech service, transcribed as text, and rendered in the console.
Reference documentation | Additional samples on GitHub
In this quickstart, you'll use the Speech SDK and the Language Understanding (LUIS) service to recognize intents from audio data captured from a microphone. Specifically, you'll use the Speech SDK to capture speech, and a prebuilt domain from LUIS to identify intents for home automation, like turning on and off a light.
Prerequisites
- Azure subscription - Create one for free
- Create a Language resource in the Azure portal. You can use the free pricing tier (
F0) to try the service, and upgrade later to a paid tier for production. You won't need a Speech resource this time. - Get the Language resource key and region. After your Language resource is deployed, select Go to resource to view and manage keys.
You also need to install the Speech SDK for your development environment and create an empty sample project.
Create a LUIS app for intent recognition
To complete the intent recognition quickstart, you'll need to create a LUIS account and a project using the LUIS preview portal. This quickstart requires a LUIS subscription in a region where intent recognition is available. A Speech service subscription isn't required.
The first thing you'll need to do is create a LUIS account and app using the LUIS preview portal. The LUIS app that you create will use a prebuilt domain for home automation, which provides intents, entities, and example utterances. When you're finished, you'll have a LUIS endpoint running in the cloud that you can call using the Speech SDK.
Follow these instructions to create your LUIS app:
When you're done, you'll need four things:
- Re-publish with Speech priming toggled on
- Your LUIS Primary key
- Your LUIS Location
- Your LUIS App ID
Here's where you can find this information in the LUIS preview portal:
From the LUIS preview portal, select your app then select the Publish button.
Select the Production slot, if you're using
en-USselect change settings, and toggle the Speech priming option to the On position. Then select the Publish button.Important
Speech priming is highly recommended as it will improve speech recognition accuracy.
From the LUIS preview portal, select Manage, then select Azure Resources. On this page, you'll find your LUIS key and location (sometimes referred to as region) for your LUIS prediction resource.
After you've got your key and location, you'll need the app ID. Select Settings. your app ID is available on this page.
Open your project
- Open your preferred IDE.
- Load your project and open
Main.java.
Start with some boilerplate code
Let's add some code that works as a skeleton for our project.
package speechsdk.quickstart;
import com.microsoft.cognitiveservices.speech.*;
import com.microsoft.cognitiveservices.speech.intent.*;
/**
* Quickstart: recognize speech using the Speech SDK for Java.
*/
public class Main {
/**
* @param args Arguments are ignored in this sample.
*/
public static void main(String[] args) {
} catch (Exception ex) {
System.out.println("Unexpected exception: " + ex.getMessage());
assert(false);
System.exit(1);
}
}
}
Create a Speech configuration
Before you can initialize an IntentRecognizer object, you need to create a configuration that uses the key and location for your LUIS prediction resource.
Insert this code in the try / catch block in main(). Make sure you update these values:
- Replace
"YourLanguageUnderstandingSubscriptionKey"with your LUIS prediction key. - Replace
"YourLanguageUnderstandingServiceRegion"with your LUIS location. Use Region identifier from region
Tip
If you need help finding these values, see Create a LUIS app for intent recognition.
Important
Remember to remove the key from your code when you're done, and never post it publicly. For production, use a secure way of storing and accessing your credentials like Azure Key Vault. See the Azure AI services security article for more information.
// Replace below with with specified subscription key (called 'endpoint key' by the Language Understanding service)
String languageUnderstandingSubscriptionKey = "YourLanguageUnderstandingSubscriptionKey";
// Replace below with your own service region (e.g., "westus").
String languageUnderstandingServiceRegion = "YourLanguageUnderstandingServiceRegion";
// Creates an instance of intent recognizer with a given speech configuration.
// Recognizer is created with the default microphone audio input and default language "en-us".
try (SpeechConfig config = SpeechConfig.fromSubscription(languageUnderstandingSubscriptionKey, languageUnderstandingServiceRegion);
This sample uses the FromSubscription() method to build the SpeechConfig. For a full list of available methods, see SpeechConfig Class.
The Speech SDK will default to recognizing using en-us for the language, see How to recognize speech for information on choosing the source language.
Initialize an IntentRecognizer
Now, let's create an IntentRecognizer. Insert this code right below your Speech configuration.
IntentRecognizer recognizer = new IntentRecognizer(config)) {
Add a LanguageUnderstandingModel and Intents
You need to associate a LanguageUnderstandingModel with the intent recognizer, and add the intents you want recognized. We're going to use intents from the prebuilt domain for home automation.
Insert this code below your IntentRecognizer. Make sure that you replace "YourLanguageUnderstandingAppId" with your LUIS app ID.
Tip
If you need help finding this value, see Create a LUIS app for intent recognition.
// Creates a language understanding model using the app id, and adds specific intents from your model
LanguageUnderstandingModel model = LanguageUnderstandingModel.fromAppId("YourLanguageUnderstandingAppId");
recognizer.addIntent(model, "YourLanguageUnderstandingIntentName1", "id1");
recognizer.addIntent(model, "YourLanguageUnderstandingIntentName2", "id2");
recognizer.addIntent(model, "YourLanguageUnderstandingIntentName3", "any-IntentId-here");
This example uses the addIntent() function to individually add intents. If you want to add all intents from a model, use addAllIntents(model) and pass the model.
Recognize an intent
From the IntentRecognizer object, you're going to call the recognizeOnceAsync() method. This method lets the Speech service know that you're sending a single phrase for recognition, and that once the phrase is identified to stop recognizing speech.
Insert this code below your model:
System.out.println("Say something...");
// Starts recognition. It returns when the first utterance has been recognized.
IntentRecognitionResult result = recognizer.recognizeOnceAsync().get();
Display the recognition results (or errors)
When the recognition result is returned by the Speech service, you'll want to do something with it. We're going to keep it simple and print the result to console.
Insert this code below your call to recognizeOnceAsync().
// Checks result.
if (result.getReason() == ResultReason.RecognizedIntent) {
System.out.println("RECOGNIZED: Text=" + result.getText());
System.out.println(" Intent Id: " + result.getIntentId());
System.out.println(" Intent Service JSON: " + result.getProperties().getProperty(PropertyId.LanguageUnderstandingServiceResponse_JsonResult));
}
else if (result.getReason() == ResultReason.RecognizedSpeech) {
System.out.println("RECOGNIZED: Text=" + result.getText());
System.out.println(" Intent not recognized.");
}
else if (result.getReason() == ResultReason.NoMatch) {
System.out.println("NOMATCH: Speech could not be recognized.");
}
else if (result.getReason() == ResultReason.Canceled) {
CancellationDetails cancellation = CancellationDetails.fromResult(result);
System.out.println("CANCELED: Reason=" + cancellation.getReason());
if (cancellation.getReason() == CancellationReason.Error) {
System.out.println("CANCELED: ErrorCode=" + cancellation.getErrorCode());
System.out.println("CANCELED: ErrorDetails=" + cancellation.getErrorDetails());
System.out.println("CANCELED: Did you update the subscription info?");
}
}
Check your code
At this point, your code should look like this:
Note
We've added some comments to this version.
//
// Copyright (c) Microsoft. All rights reserved.
// Licensed under the MIT license. See LICENSE.md file in the project root for full license information.
//
// <skeleton_1>
package speechsdk.quickstart;
import com.microsoft.cognitiveservices.speech.*;
import com.microsoft.cognitiveservices.speech.intent.*;
/**
* Quickstart: recognize speech using the Speech SDK for Java.
*/
public class Main {
/**
* @param args Arguments are ignored in this sample.
*/
public static void main(String[] args) {
// </skeleton_1>
// <create_speech_configuration>
// Replace below with with specified subscription key (called 'endpoint key' by the Language Understanding service)
String languageUnderstandingSubscriptionKey = "YourLanguageUnderstandingSubscriptionKey";
// Replace below with your own service region (e.g., "westus").
String languageUnderstandingServiceRegion = "YourLanguageUnderstandingServiceRegion";
// Creates an instance of intent recognizer with a given speech configuration.
// Recognizer is created with the default microphone audio input and default language "en-us".
try (SpeechConfig config = SpeechConfig.fromSubscription(languageUnderstandingSubscriptionKey, languageUnderstandingServiceRegion);
// </create_speech_configuration>
// <create_intent_recognizer>
IntentRecognizer recognizer = new IntentRecognizer(config)) {
// </create_intent_recognizer>
// <add_intents>
// Creates a language understanding model using the app id, and adds specific intents from your model
LanguageUnderstandingModel model = LanguageUnderstandingModel.fromAppId("YourLanguageUnderstandingAppId");
recognizer.addIntent(model, "YourLanguageUnderstandingIntentName1", "id1");
recognizer.addIntent(model, "YourLanguageUnderstandingIntentName2", "id2");
recognizer.addIntent(model, "YourLanguageUnderstandingIntentName3", "any-IntentId-here");
// </add_intents>
// To add all of the possible intents from a LUIS model to the recognizer, uncomment the line below:
// recognizer.addAllIntents(model);
// <recognize_intent>
System.out.println("Say something...");
// Starts recognition. It returns when the first utterance has been recognized.
IntentRecognitionResult result = recognizer.recognizeOnceAsync().get();
// </recognize_intent>
// <print_result>
// Checks result.
if (result.getReason() == ResultReason.RecognizedIntent) {
System.out.println("RECOGNIZED: Text=" + result.getText());
System.out.println(" Intent Id: " + result.getIntentId());
System.out.println(" Intent Service JSON: " + result.getProperties().getProperty(PropertyId.LanguageUnderstandingServiceResponse_JsonResult));
}
else if (result.getReason() == ResultReason.RecognizedSpeech) {
System.out.println("RECOGNIZED: Text=" + result.getText());
System.out.println(" Intent not recognized.");
}
else if (result.getReason() == ResultReason.NoMatch) {
System.out.println("NOMATCH: Speech could not be recognized.");
}
else if (result.getReason() == ResultReason.Canceled) {
CancellationDetails cancellation = CancellationDetails.fromResult(result);
System.out.println("CANCELED: Reason=" + cancellation.getReason());
if (cancellation.getReason() == CancellationReason.Error) {
System.out.println("CANCELED: ErrorCode=" + cancellation.getErrorCode());
System.out.println("CANCELED: ErrorDetails=" + cancellation.getErrorDetails());
System.out.println("CANCELED: Did you update the subscription info?");
}
}
// </print_result>
// <skeleton_2>
} catch (Exception ex) {
System.out.println("Unexpected exception: " + ex.getMessage());
assert(false);
System.exit(1);
}
}
}
// </skeleton_2>
Build and run your app
Press F11, or select Run > Debug. The next 15 seconds of speech input from your microphone will be recognized and logged in the console window.
Reference documentation | Package (npm) | Additional samples on GitHub | Library source code
In this quickstart, you'll use the Speech SDK and the Language Understanding (LUIS) service to recognize intents from audio data captured from a microphone. Specifically, you'll use the Speech SDK to capture speech, and a prebuilt domain from LUIS to identify intents for home automation, like turning on and off a light.
Prerequisites
- Azure subscription - Create one for free
- Create a Language resource in the Azure portal. You can use the free pricing tier (
F0) to try the service, and upgrade later to a paid tier for production. You won't need a Speech resource this time. - Get the Language resource key and region. After your Language resource is deployed, select Go to resource to view and manage keys.
You also need to install the Speech SDK for your development environment and create an empty sample project.
Create a LUIS app for intent recognition
To complete the intent recognition quickstart, you'll need to create a LUIS account and a project using the LUIS preview portal. This quickstart requires a LUIS subscription in a region where intent recognition is available. A Speech service subscription isn't required.
The first thing you'll need to do is create a LUIS account and app using the LUIS preview portal. The LUIS app that you create will use a prebuilt domain for home automation, which provides intents, entities, and example utterances. When you're finished, you'll have a LUIS endpoint running in the cloud that you can call using the Speech SDK.
Follow these instructions to create your LUIS app:
When you're done, you'll need four things:
- Re-publish with Speech priming toggled on
- Your LUIS Primary key
- Your LUIS Location
- Your LUIS App ID
Here's where you can find this information in the LUIS preview portal:
From the LUIS preview portal, select your app then select the Publish button.
Select the Production slot, if you're using
en-USselect change settings, and toggle the Speech priming option to the On position. Then select the Publish button.Important
Speech priming is highly recommended as it will improve speech recognition accuracy.
From the LUIS preview portal, select Manage, then select Azure Resources. On this page, you'll find your LUIS key and location (sometimes referred to as region) for your LUIS prediction resource.
After you've got your key and location, you'll need the app ID. Select Settings. your app ID is available on this page.
Start with some boilerplate code
Let's add some code that works as a skeleton for our project.
<!DOCTYPE html>
<html>
<head>
<title>Microsoft Azure AI Speech SDK JavaScript Quickstart</title>
<meta charset="utf-8" />
</head>
<body style="font-family:'Helvetica Neue',Helvetica,Arial,sans-serif; font-size:13px;">
</body>
</html>
Add UI Elements
Now we'll add some basic UI for input boxes, reference the Speech SDK's JavaScript, and grab an authorization token if available.
Important
Remember to remove the key from your code when you're done, and never post it publicly. For production, use a secure way of storing and accessing your credentials like Azure Key Vault. See the Azure AI services security article for more information.
<body style="font-family:'Helvetica Neue',Helvetica,Arial,sans-serif; font-size:13px;">
<div id="content" style="display:none">
<table width="100%">
<tr>
<td></td>
<td><h1 style="font-weight:500;">Microsoft Azure AI Speech SDK JavaScript Quickstart</h1></td>
</tr>
<tr>
<td align="right"><a href="https://learn.microsoft.com/azure/ai-services/speech-service/overview" target="_blank">Subscription</a>:</td>
<td><input id="subscriptionKey" type="text" size="40" value="subscription"></td>
</tr>
<tr>
<td align="right">Region</td>
<td><input id="serviceRegion" type="text" size="40" value="YourServiceRegion"></td>
</tr>
<tr>
<td align="right">Application ID:</td>
<td><input id="appId" type="text" size="60" value="YOUR_LANGUAGE_UNDERSTANDING_APP_ID"></td>
</tr>
<tr>
<td></td>
<td><button id="startIntentRecognizeAsyncButton">Start Intent Recognition</button></td>
</tr>
<tr>
<td align="right" valign="top">Input Text</td>
<td><textarea id="phraseDiv" style="display: inline-block;width:500px;height:200px"></textarea></td>
</tr>
<tr>
<td align="right" valign="top">Result</td>
<td><textarea id="statusDiv" style="display: inline-block;width:500px;height:100px"></textarea></td>
</tr>
</table>
</div>
<script src="microsoft.cognitiveservices.speech.sdk.bundle.js"></script>
<script>
// Note: Replace the URL with a valid endpoint to retrieve
// authorization tokens for your subscription.
var authorizationEndpoint = "token.php";
function RequestAuthorizationToken() {
if (authorizationEndpoint) {
var a = new XMLHttpRequest();
a.open("GET", authorizationEndpoint);
a.setRequestHeader("Content-Type", "application/x-www-form-urlencoded");
a.send("");
a.onload = function() {
var token = JSON.parse(atob(this.responseText.split(".")[1]));
serviceRegion.value = token.region;
authorizationToken = this.responseText;
subscriptionKey.disabled = true;
subscriptionKey.value = "using authorization token (hit F5 to refresh)";
console.log("Got an authorization token: " + token);
}
}
}
</script>
<script>
// status fields and start button in UI
var phraseDiv;
var statusDiv;
var startIntentRecognizeAsyncButton;
// subscription key, region, and appId for LUIS services.
var subscriptionKey, serviceRegion, appId;
var authorizationToken;
var SpeechSDK;
var recognizer;
document.addEventListener("DOMContentLoaded", function () {
startIntentRecognizeAsyncButton = document.getElementById("startIntentRecognizeAsyncButton");
subscriptionKey = document.getElementById("subscriptionKey");
serviceRegion = document.getElementById("serviceRegion");
appId = document.getElementById("appId");
phraseDiv = document.getElementById("phraseDiv");
statusDiv = document.getElementById("statusDiv");
startIntentRecognizeAsyncButton.addEventListener("click", function () {
startIntentRecognizeAsyncButton.disabled = true;
phraseDiv.innerHTML = "";
statusDiv.innerHTML = "";
});
if (!!window.SpeechSDK) {
SpeechSDK = window.SpeechSDK;
startIntentRecognizeAsyncButton.disabled = false;
document.getElementById('content').style.display = 'block';
document.getElementById('warning').style.display = 'none';
// in case we have a function for getting an authorization token, call it.
if (typeof RequestAuthorizationToken === "function") {
RequestAuthorizationToken();
}
}
});
</script>
Create a Speech configuration
Before you can initialize a SpeechRecognizer object, you need to create a configuration that uses your subscription key and subscription region. Insert this code in the startRecognizeOnceAsyncButton.addEventListener() method.
Note
The Speech SDK will default to recognizing using en-us for the language, see How to recognize speech for information on choosing the source language.
// if we got an authorization token, use the token. Otherwise use the provided subscription key
var speechConfig;
if (authorizationToken) {
speechConfig = SpeechSDK.SpeechConfig.fromAuthorizationToken(authorizationToken, serviceRegion.value);
} else {
if (subscriptionKey.value === "" || subscriptionKey.value === "subscription") {
alert("Please enter your Microsoft Azure AI Speech subscription key!");
return;
}
startIntentRecognizeAsyncButton.disabled = false;
speechConfig = SpeechSDK.SpeechConfig.fromSubscription(subscriptionKey.value, serviceRegion.value);
}
speechConfig.speechRecognitionLanguage = "en-US";
Create an Audio configuration
Now, you need to create an AudioConfig object that points to your input device. Insert this code in the startIntentRecognizeAsyncButton.addEventListener() method, right below your Speech configuration.
var audioConfig = SpeechSDK.AudioConfig.fromDefaultMicrophoneInput();
Initialize an IntentRecognizer
Now, let's create the IntentRecognizer object using the SpeechConfig and AudioConfig objects created earlier. Insert this code in the startIntentRecognizeAsyncButton.addEventListener() method.
recognizer = new SpeechSDK.IntentRecognizer(speechConfig, audioConfig);
Add a LanguageUnderstandingModel and Intents
You need to associate a LanguageUnderstandingModel with the intent recognizer and add the intents you want recognized. We're going to use intents from the prebuilt domain for home automation.
Insert this code below your IntentRecognizer. Make sure that you replace "YourLanguageUnderstandingAppId" with your LUIS app ID.
if (appId.value !== "" && appId.value !== "YOUR_LANGUAGE_UNDERSTANDING_APP_ID") {
var lm = SpeechSDK.LanguageUnderstandingModel.fromAppId(appId.value);
recognizer.addAllIntents(lm);
}
Note
Speech SDK only supports LUIS v2.0 endpoints. You must manually modify the v3.0 endpoint URL found in the example query field to use a v2.0 URL pattern. LUIS v2.0 endpoints always follow one of these two patterns:
https://{AzureResourceName}.cognitiveservices.azure.com/luis/v2.0/apps/{app-id}?subscription-key={subkey}&verbose=true&q=https://{Region}.api.cognitive.microsoft.com/luis/v2.0/apps/{app-id}?subscription-key={subkey}&verbose=true&q=
Recognize an intent
From the IntentRecognizer object, you're going to call the recognizeOnceAsync() method. This method lets the Speech service know that you're sending a single phrase for recognition, and that once the phrase is identified to stop recognizing speech.
Insert this code below the model addition:
recognizer.recognizeOnceAsync(
function (result) {
window.console.log(result);
phraseDiv.innerHTML = result.text + "\r\n";
statusDiv.innerHTML += "(continuation) Reason: " + SpeechSDK.ResultReason[result.reason];
switch (result.reason) {
case SpeechSDK.ResultReason.RecognizedSpeech:
statusDiv.innerHTML += " Text: " + result.text;
break;
case SpeechSDK.ResultReason.RecognizedIntent:
statusDiv.innerHTML += " Text: " + result.text + " IntentId: " + result.intentId;
// The actual JSON returned from Language Understanding is a bit more complex to get to, but it is available for things like
// the entity name and type if part of the intent.
statusDiv.innerHTML += " Intent JSON: " + result.properties.getProperty(SpeechSDK.PropertyId.LanguageUnderstandingServiceResponse_JsonResult);
phraseDiv.innerHTML += result.properties.getProperty(SpeechSDK.PropertyId.LanguageUnderstandingServiceResponse_JsonResult) + "\r\n";
break;
case SpeechSDK.ResultReason.NoMatch:
var noMatchDetail = SpeechSDK.NoMatchDetails.fromResult(result);
statusDiv.innerHTML += " NoMatchReason: " + SpeechSDK.NoMatchReason[noMatchDetail.reason];
break;
case SpeechSDK.ResultReason.Canceled:
var cancelDetails = SpeechSDK.CancellationDetails.fromResult(result);
statusDiv.innerHTML += " CancellationReason: " + SpeechSDK.CancellationReason[cancelDetails.reason];
if (cancelDetails.reason === SpeechSDK.CancellationReason.Error) {
statusDiv.innerHTML += ": " + cancelDetails.errorDetails;
}
break;
}
statusDiv.innerHTML += "\r\n";
startIntentRecognizeAsyncButton.disabled = false;
},
function (err) {
window.console.log(err);
phraseDiv.innerHTML += "ERROR: " + err;
startIntentRecognizeAsyncButton.disabled = false;
});
Check your code
<!DOCTYPE html>
<html>
<head>
<title>Microsoft Cognitive Services Speech SDK JavaScript Quickstart</title>
<meta charset="utf-8" />
</head>
<body style="font-family:'Helvetica Neue',Helvetica,Arial,sans-serif; font-size:13px;">
<div id="warning">
<h1 style="font-weight:500;">Speech Recognition Speech SDK not found (microsoft.cognitiveservices.speech.sdk.bundle.js missing).</h1>
</div>
<div id="content" style="display:none">
<table width="100%">
<tr>
<td></td>
<td><h1 style="font-weight:500;">Microsoft Cognitive Services Speech SDK JavaScript Quickstart</h1></td>
</tr>
<tr>
<td align="right"><a href="https://docs.microsoft.com/azure/cognitive-services/speech-service/quickstarts/intent-recognition?pivots=programming-language-csharp#create-a-luis-app-for-intent-recognition" target="_blank">LUIS Primary Key</a>:</td>
<td><input id="subscriptionKey" type="text" size="40" value="subscription"></td>
</tr>
<tr>
<td align="right">LUIS Location</td>
<td><input id="serviceRegion" type="text" size="40" value="YourServiceRegion"></td>
</tr>
<tr>
<td align="right">LUIS App ID:</td>
<td><input id="appId" type="text" size="60" value="YOUR_LANGUAGE_UNDERSTANDING_APP_ID"></td>
</tr>
<tr>
<td></td>
<td><button id="startIntentRecognizeAsyncButton">Start Intent Recognition</button></td>
</tr>
<tr>
<td align="right" valign="top">Input Text</td>
<td><textarea id="phraseDiv" style="display: inline-block;width:500px;height:200px"></textarea></td>
</tr>
<tr>
<td align="right" valign="top">Result</td>
<td><textarea id="statusDiv" style="display: inline-block;width:500px;height:100px"></textarea></td>
</tr>
</table>
</div>
<!-- Speech SDK reference sdk. -->
<script src="https://aka.ms/csspeech/jsbrowserpackageraw"></script>
<!-- Speech SDK USAGE -->
<script>
// status fields and start button in UI
var phraseDiv;
var statusDiv;
var startIntentRecognizeAsyncButton;
// subscription key and region for speech services.
var subscriptionKey, serviceRegion, appId;
var SpeechSDK;
var recognizer;
document.addEventListener("DOMContentLoaded", function () {
startIntentRecognizeAsyncButton = document.getElementById("startIntentRecognizeAsyncButton");
subscriptionKey = document.getElementById("subscriptionKey");
serviceRegion = document.getElementById("serviceRegion");
appId = document.getElementById("appId");
phraseDiv = document.getElementById("phraseDiv");
statusDiv = document.getElementById("statusDiv");
startIntentRecognizeAsyncButton.addEventListener("click", function () {
startIntentRecognizeAsyncButton.disabled = true;
phraseDiv.innerHTML = "";
statusDiv.innerHTML = "";
let audioConfig = SpeechSDK.AudioConfig.fromDefaultMicrophoneInput();
if (subscriptionKey.value === "" || subscriptionKey.value === "subscription") {
alert("Please enter your Microsoft Cognitive Services Speech subscription key!");
startIntentRecognizeAsyncButton.disabled = false;
return;
}
var speechConfig = SpeechSDK.SpeechConfig.fromSubscription(subscriptionKey.value, serviceRegion.value);
speechConfig.speechRecognitionLanguage = "en-US";
recognizer = new SpeechSDK.IntentRecognizer(speechConfig, audioConfig);
// Set up a Language Understanding Model from Language Understanding Intelligent Service (LUIS).
// See https://www.luis.ai/home for more information on LUIS.
if (appId.value !== "" && appId.value !== "YOUR_LANGUAGE_UNDERSTANDING_APP_ID") {
var lm = SpeechSDK.LanguageUnderstandingModel.fromAppId(appId.value);
recognizer.addAllIntents(lm);
}
recognizer.recognizeOnceAsync(
function (result) {
window.console.log(result);
phraseDiv.innerHTML = result.text + "\r\n";
statusDiv.innerHTML += "(continuation) Reason: " + SpeechSDK.ResultReason[result.reason];
switch (result.reason) {
case SpeechSDK.ResultReason.RecognizedSpeech:
statusDiv.innerHTML += " Text: " + result.text;
break;
case SpeechSDK.ResultReason.RecognizedIntent:
statusDiv.innerHTML += " Text: " + result.text + " IntentId: " + result.intentId;
// The actual JSON returned from Language Understanding is a bit more complex to get to, but it is available for things like
// the entity name and type if part of the intent.
statusDiv.innerHTML += " Intent JSON: " + result.properties.getProperty(SpeechSDK.PropertyId.LanguageUnderstandingServiceResponse_JsonResult);
phraseDiv.innerHTML += result.properties.getProperty(SpeechSDK.PropertyId.LanguageUnderstandingServiceResponse_JsonResult) + "\r\n";
break;
case SpeechSDK.ResultReason.NoMatch:
var noMatchDetail = SpeechSDK.NoMatchDetails.fromResult(result);
statusDiv.innerHTML += " NoMatchReason: " + SpeechSDK.NoMatchReason[noMatchDetail.reason];
break;
case SpeechSDK.ResultReason.Canceled:
var cancelDetails = SpeechSDK.CancellationDetails.fromResult(result);
statusDiv.innerHTML += " CancellationReason: " + SpeechSDK.CancellationReason[cancelDetails.reason];
if (cancelDetails.reason === SpeechSDK.CancellationReason.Error) {
statusDiv.innerHTML += ": " + cancelDetails.errorDetails;
}
break;
}
statusDiv.innerHTML += "\r\n";
startIntentRecognizeAsyncButton.disabled = false;
},
function (err) {
window.console.log(err);
phraseDiv.innerHTML += "ERROR: " + err;
startIntentRecognizeAsyncButton.disabled = false;
});
});
if (!!window.SpeechSDK) {
SpeechSDK = window.SpeechSDK;
startIntentRecognizeAsyncButton.disabled = false;
document.getElementById('content').style.display = 'block';
document.getElementById('warning').style.display = 'none';
}
});
</script>
</body>
</html>
Create the token source (optional)
In case you want to host the web page on a web server, you can optionally provide a token source for your demo application. That way, your subscription key will never leave your server while allowing users to use speech capabilities without entering any authorization code themselves.
Create a new file named token.php. In this example we assume your web server supports the PHP scripting language with curl enabled. Enter the following code:
<?php
header('Access-Control-Allow-Origin: ' . $_SERVER['SERVER_NAME']);
// Replace with your own subscription key and service region (e.g., "westus").
$subscriptionKey = 'YourSubscriptionKey';
$region = 'YourServiceRegion';
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'https://' . $region . '.api.cognitive.microsoft.com/sts/v1.0/issueToken');
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, '{}');
curl_setopt($ch, CURLOPT_HTTPHEADER, array('Content-Type: application/json', 'Ocp-Apim-Subscription-Key: ' . $subscriptionKey));
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
echo curl_exec($ch);
?>
Note
Authorization tokens only have a limited lifetime. This simplified example does not show how to refresh authorization tokens automatically. As a user, you can manually reload the page or hit F5 to refresh.
Build and run the sample locally
To launch the app, double-click on the index.html file or open index.html with your favorite web browser. It will present a simple GUI allowing you to enter your LUIS key, LUIS region, and LUIS Application ID. Once those fields have been entered, you can click the appropriate button to trigger a recognition using the microphone.
Note
This method doesn't work on the Safari browser. On Safari, the sample web page needs to be hosted on a web server; Safari doesn't allow websites loaded from a local file to use the microphone.
Build and run the sample via a web server
To launch your app, open your favorite web browser and point it to the public URL that you host the folder on, enter your LUIS region as well as your LUIS Application ID, and trigger a recognition using the microphone. If configured, it will acquire a token from your token source and begin recognizing spoken commands.
Reference documentation | Package (PyPi) | Additional samples on GitHub
In this quickstart, you'll use the Speech SDK and the Language Understanding (LUIS) service to recognize intents from audio data captured from a microphone. Specifically, you'll use the Speech SDK to capture speech, and a prebuilt domain from LUIS to identify intents for home automation, like turning on and off a light.
Prerequisites
- Azure subscription - Create one for free
- Create a Language resource in the Azure portal. You can use the free pricing tier (
F0) to try the service, and upgrade later to a paid tier for production. You won't need a Speech resource this time. - Get the Language resource key and region. After your Language resource is deployed, select Go to resource to view and manage keys.
You also need to install the Speech SDK for your development environment and create an empty sample project.
Create a LUIS app for intent recognition
To complete the intent recognition quickstart, you'll need to create a LUIS account and a project using the LUIS preview portal. This quickstart requires a LUIS subscription in a region where intent recognition is available. A Speech service subscription isn't required.
The first thing you'll need to do is create a LUIS account and app using the LUIS preview portal. The LUIS app that you create will use a prebuilt domain for home automation, which provides intents, entities, and example utterances. When you're finished, you'll have a LUIS endpoint running in the cloud that you can call using the Speech SDK.
Follow these instructions to create your LUIS app:
When you're done, you'll need four things:
- Re-publish with Speech priming toggled on
- Your LUIS Primary key
- Your LUIS Location
- Your LUIS App ID
Here's where you can find this information in the LUIS preview portal:
From the LUIS preview portal, select your app then select the Publish button.
Select the Production slot, if you're using
en-USselect change settings, and toggle the Speech priming option to the On position. Then select the Publish button.Important
Speech priming is highly recommended as it will improve speech recognition accuracy.
From the LUIS preview portal, select Manage, then select Azure Resources. On this page, you'll find your LUIS key and location (sometimes referred to as region) for your LUIS prediction resource.
After you've got your key and location, you'll need the app ID. Select Settings. your app ID is available on this page.
Open your project
- Open your preferred IDE.
- Create a new project and create file called
quickstart.py, then open it.
Start with some boilerplate code
Let's add some code that works as a skeleton for our project.
import azure.cognitiveservices.speech as speechsdk
print("Say something...")
Create a Speech configuration
Before you can initialize an IntentRecognizer object, you need to create a configuration that uses the key and location for your LUIS prediction resource.
Insert this code in quickstart.py. Make sure you update these values:
- Replace
"YourLanguageUnderstandingSubscriptionKey"with your LUIS prediction key. - Replace
"YourLanguageUnderstandingServiceRegion"with your LUIS location. Use Region identifier from region
Tip
If you need help finding these values, see Create a LUIS app for intent recognition.
Important
Remember to remove the key from your code when you're done, and never post it publicly. For production, use a secure way of storing and accessing your credentials like Azure Key Vault. See the Azure AI services security article for more information.
# Set up the config for the intent recognizer (remember that this uses the Language Understanding key, not the Speech Services key)!
intent_config = speechsdk.SpeechConfig(
subscription="YourLanguageUnderstandingSubscriptionKey",
region="YourLanguageUnderstandingServiceRegion")
This sample constructs the SpeechConfig object using LUIS key and region. For a full list of available methods, see SpeechConfig Class.
The Speech SDK will default to recognizing using en-us for the language, see How to recognize speech for information on choosing the source language.
Initialize an IntentRecognizer
Now, let's create an IntentRecognizer. Insert this code right below your Speech configuration.
# Set up the intent recognizer
intent_recognizer = speechsdk.intent.IntentRecognizer(speech_config=intent_config)
Add a LanguageUnderstandingModel and Intents
You need to associate a LanguageUnderstandingModel with the intent recognizer and add the intents you want recognized. We're going to use intents from the prebuilt domain for home automation.
Insert this code below your IntentRecognizer. Make sure that you replace "YourLanguageUnderstandingAppId" with your LUIS app ID.
Tip
If you need help finding this value, see Create a LUIS app for intent recognition.
# set up the intents that are to be recognized. These can be a mix of simple phrases and
# intents specified through a LanguageUnderstanding Model.
model = speechsdk.intent.LanguageUnderstandingModel(app_id="YourLanguageUnderstandingAppId")
intents = [
(model, "HomeAutomation.TurnOn"),
(model, "HomeAutomation.TurnOff"),
("This is a test.", "test"),
("Switch to channel 34.", "34"),
("what's the weather like", "weather"),
]
intent_recognizer.add_intents(intents)
This example uses the add_intents() function to add a list of explicitly-defined intents. If you want to add all intents from a model, use add_all_intents(model) and pass the model.
Recognize an intent
From the IntentRecognizer object, you're going to call the recognize_once() method. This method lets the Speech service know that you're sending a single phrase for recognition, and that once the phrase is identified to stop recognizing speech.
Insert this code below your model.
intent_result = intent_recognizer.recognize_once()
Display the recognition results (or errors)
When the recognition result is returned by the Speech service, you'll want to do something with it. We're going to keep it simple and print the result to console.
Below your call to recognize_once(), add this code.
# Check the results
if intent_result.reason == speechsdk.ResultReason.RecognizedIntent:
print("Recognized: \"{}\" with intent id `{}`".format(intent_result.text, intent_result.intent_id))
elif intent_result.reason == speechsdk.ResultReason.RecognizedSpeech:
print("Recognized: {}".format(intent_result.text))
elif intent_result.reason == speechsdk.ResultReason.NoMatch:
print("No speech could be recognized: {}".format(intent_result.no_match_details))
elif intent_result.reason == speechsdk.ResultReason.Canceled:
print("Intent recognition canceled: {}".format(intent_result.cancellation_details.reason))
if intent_result.cancellation_details.reason == speechsdk.CancellationReason.Error:
print("Error details: {}".format(intent_result.cancellation_details.error_details))
Check your code
At this point, your code should look like this.
Note
We've added some comments to this version.
# Copyright (c) Microsoft. All rights reserved.
# Licensed under the MIT license. See LICENSE.md file in the project root for full license information.
# <skeleton>
import azure.cognitiveservices.speech as speechsdk
print("Say something...")
# </skeleton>
"""performs one-shot intent recognition from input from the default microphone"""
# <create_speech_configuration>
# Set up the config for the intent recognizer (remember that this uses the Language Understanding key, not the Speech Services key)!
intent_config = speechsdk.SpeechConfig(
subscription="YourLanguageUnderstandingSubscriptionKey",
region="YourLanguageUnderstandingServiceRegion")
# </create_speech_configuration>
# <create_intent_recognizer>
# Set up the intent recognizer
intent_recognizer = speechsdk.intent.IntentRecognizer(speech_config=intent_config)
# </create_intent_recognizer>
# <add_intents>
# set up the intents that are to be recognized. These can be a mix of simple phrases and
# intents specified through a LanguageUnderstanding Model.
model = speechsdk.intent.LanguageUnderstandingModel(app_id="YourLanguageUnderstandingAppId")
intents = [
(model, "HomeAutomation.TurnOn"),
(model, "HomeAutomation.TurnOff"),
("This is a test.", "test"),
("Switch to channel 34.", "34"),
("what's the weather like", "weather"),
]
intent_recognizer.add_intents(intents)
# </add_intents>
# To add all of the possible intents from a LUIS model to the recognizer, uncomment the line below:
# intent_recognizer.add_all_intents(model)
# Starts intent recognition, and returns after a single utterance is recognized. The end of a
# single utterance is determined by listening for silence at the end or until a maximum of about 30
# seconds of audio is processed. It returns the recognition text as result.
# Note: Since recognize_once() returns only a single utterance, it is suitable only for single
# shot recognition like command or query.
# For long-running multi-utterance recognition, use start_continuous_recognition() instead.
# <recognize_intent>
intent_result = intent_recognizer.recognize_once()
# </recognize_intent>
# <print_results>
# Check the results
if intent_result.reason == speechsdk.ResultReason.RecognizedIntent:
print("Recognized: \"{}\" with intent id `{}`".format(intent_result.text, intent_result.intent_id))
elif intent_result.reason == speechsdk.ResultReason.RecognizedSpeech:
print("Recognized: {}".format(intent_result.text))
elif intent_result.reason == speechsdk.ResultReason.NoMatch:
print("No speech could be recognized: {}".format(intent_result.no_match_details))
elif intent_result.reason == speechsdk.ResultReason.Canceled:
print("Intent recognition canceled: {}".format(intent_result.cancellation_details.reason))
if intent_result.cancellation_details.reason == speechsdk.CancellationReason.Error:
print("Error details: {}".format(intent_result.cancellation_details.error_details))
# </print_results>
Build and run your app
Run the sample from the console or in your IDE:
python quickstart.py
The next 15 seconds of speech input from your microphone will be recognized and logged in the console window.
Reference documentation | Package (Go) | Additional samples on GitHub
The Speech SDK for Go doesn't support intent recognition. Please select another programming language or the Go reference and samples linked from the beginning of this article.
Reference documentation | Package (download) | Additional samples on GitHub
The Speech SDK for Objective-C does support intent recognition, but we haven't yet included a guide here. Please select another programming language to get started and learn about the concepts, or see the Objective-C reference and samples linked from the beginning of this article.
Reference documentation | Package (download) | Additional samples on GitHub
The Speech SDK for Swift does support intent recognition, but we haven't yet included a guide here. Please select another programming language to get started and learn about the concepts, or see the Swift reference and samples linked from the beginning of this article.
Speech to text REST API reference | Speech to text REST API for short audio reference | Additional samples on GitHub
You can use the REST API for intent recognition, but we haven't yet included a guide here. Please select another programming language to get started and learn about the concepts.
The Speech command line interface (CLI) does support intent recognition, but we haven't yet included a guide here. Please select another programming language to get started and learn about the concepts, or see Speech CLI overview for more about the CLI.