Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Retrieval Augmented Generation (RAG) is a powerful technique that combines the capabilities of large language models and information retrieval to generate text. It enables the generation of more accurate and informative responses by retrieving relevant information from a document collection. Rapid experimentation is crucial for the successful implementation of RAG systems.
Business problem
Customers implementing RAG systems need to experiment rapidly, but they lack the tooling to do so. This lack of tooling prolongs the experimentation phase and leads to wasted investment in creating custom experimentation code for each RAG system.
Solution
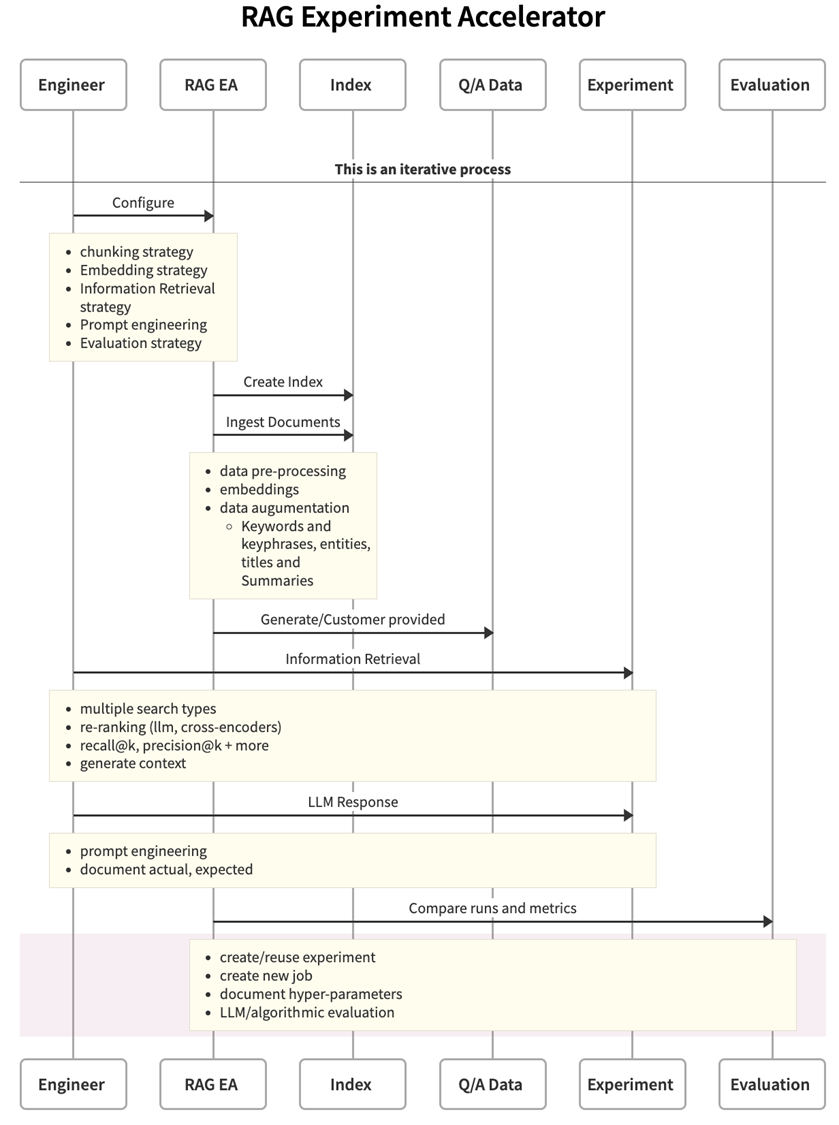
The RAG Experiment Accelerator is a tool designed to help teams quickly find the best strategies for RAG implementation by running multiple experiments and evaluating the results. It provides a standardized and consistent way to experiment with RAG. It also provides tools for configuring, indexing, querying, and evaluating using RAG.
Configuration
Configuration allows users to experiment with different strategies and options for each part of the RAG solution. The results of each strategy and option can be compared. Users can configure their experiments by specifying the chunking methods, embedding dimensions, language, and other parameters. Configuration is done by editing the config.json file and choosing the desired values for each parameter.
Index creation
Once the configuration is complete, the accelerator creates an index and ingests the documents. The accelerator can support various document formats, including PDF, HTML, Markdown, Text, JSON, and DOCX. Index creation involves chunking the documents into smaller pieces, converting them into embeddings, and storing them in a vector index. Full text indexing is also an option. The accelerator allows users to configure different parameters for chunking, embedding, and indexing, and to experiment with different strategies.
Querying
After the documents are ingested, the accelerator can perform queries on the index. Querying is the process of asking questions to the information retrieval system to get relevant chunks of data from the customer's documents. Querying can be done in diverse ways, such as full text, vector, or hybrid search. It can also involve rephrasing, subquerying, and reranking to improve the results.
Evaluation
The accelerator also provides tools for evaluating the quality of the information retrieval system and the large language model. Users can specify the metrics they want to use to evaluate the results. The information retrieval system results can be evaluated using the following metrics:
- Mean reciprocal rank
- Precision at K
- Recall at K
The following metrics can be used to evaluate the responses of large language models:
- Cosine similarity
- BLEU
- ROUGE
The accelerator using MLflow will generate reports and charts to help users compare different experiments.
Value proposition
One of the key benefits of the RAG Experiment Accelerator is its ability to quickly provide insights into customer data. By running experiments on customer data, teams can gain a better understanding of the data and find the best strategies for RAG implementation. These data insights can help teams to more effectively engage with customers and provide more informed recommendations.
Logical architecture
Implementation
The RAG Experiment Accelerator is provided as a GitHub repository that you can clone and begin using: microsoft/rag-experiment-accelerator