MLOps implementation in Databricks using MLflow Projects
Introduction
In the Model Release document, we show an example of the MLOps process. The process included stages from creating a feature branch to a release into the production environment:
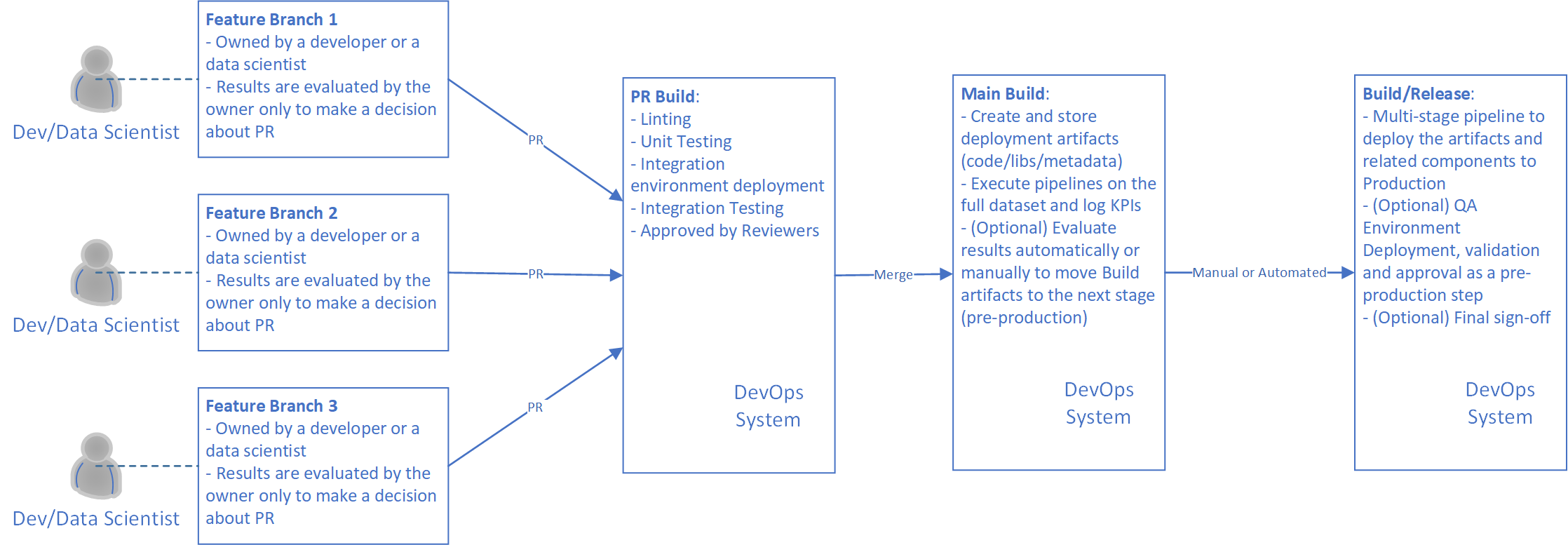
This process looks the same in Databricks as in Azure ML, Kubeflow or any other ML framework/compute. The only difference for Databricks is the requirement to deploy wheel files alongside with execution of the MLflow projects. MLflow tools allow the execution of projects from the command-line interface (CLI). It does this by uploading all the required code to DBFS automatically, but all related python wheels should be uploaded to DBFS in advance. When implementing MLOps for Databricks it's important to build a set of scripts that will wrap around MLflow tools, adding wheel deployment capabilities. The script(s) should implement the following set of actions in sequence:
- Pick a unique experiment name to execute and a folder name in DBFS to deploy wheels.
- Create the folder in DBFS and upload wheels.
- Modify the MLflow project configuration file using new references to the wheel files in DBFS.
- Use MLflow tools to start the experiment with generated experiment name.
Let's discuss these actions in details.
Picking a Unique Experiment and Folder Names
Running experiments from different branches we need to make sure that each branch has its own unique experiment name. That way, we can create the experiment name dynamically using the branch name as a part of it. It will help us to have several runs on the same branch under the same experiment name. So, we will be able to compare results between them.
If we execute an MLflow project from a DevOps system, there should be a variable that allows us to get access to the branch name. For example, in Azure Pipelines $(Build.SourceBranchName) can be utilized.
When executing an MLflow project from a local computer, it's possible to use a command like this:
git_branch=$(git rev-parse --abbrev-ref HEAD)
Deploying Wheel Files into DBFS
The Databricks command-line interface (CLI) provides an easy-to-use interface to the Azure Databricks platform and it can be used to deploy the wheel files into desired location in DBFS. Here is an example of the command from Azure Pipelines:
dbfs cp -r --overwrite $(Build.ArtifactStagingDirectory)/wheel dbfs:/wheels/$(Build.SourceBranchName)/$(wheel_folder_name)/
MLflow Projects Configuration and Execution
Databricks has been integrated with MLflow that allows us to implement all MLOps related tasks with less effort. MLflow refers to "projects" rather than "pipelines", where a "project" is a folder that contains all pipeline related attributes:
- MLProject file: defines all entry points to execute
- {your_name}.yaml file: defines all dependencies that should be installed on the compute cluster
- {your_name}.json file: a cluster definition
- scripts (Python/Bash): implementation of the steps
Configuring MLflow projects to use generated and uploaded wheel files requires two files: the dependencies file and the cluster definition file.
The dependencies file contains all the libraries to install and references to all the custom wheel files that should be installed on the main node of a cluster. For example, the file can look like this:
name: training
channels:
- defaults
- anaconda
- conda-forge
dependencies:
- python=3.8
- scikit-learn
- pip
- gcc
- prophet
- pmdarima
- pip:
- mlflow
- /dbfs/wheels/builds/WHEELPATH
- pyarrow
The /dbfs/wheels/builds/WHEELPATH is just a placeholder for the wheel that we should copy into DBFS in advance. We can modify this placeholder on fly.
The wheel file from the YAML file will be installed to the main node only. In some cases, it's not enough and you need to install the wheel to the workers. It's possible to do using the cluster definition file. Here is an example for your reference:
{
"new_cluster": {
"spark_version": "10.3.x-scala2.12",
"num_workers": 4,
"node_type_id": "Standard_DS3_v2"
},
"libraries": [
{
"pypi":{
"package": "convertdate"
}
},
{
"pypi": {
"package": "/dbfs/wheels/builds/WHEELPATH"
}
}
]
}
MLflow SDK allows us to execute an MLflow project on a local computer or in a git repository using just a couple lines of code:
# optional if experiment_id is provided
mlflow.set_experiment(experiment_folder)
mlflow.run(
"{project_folder}",
backend="databricks",
backend_config="cluster.json",
# optional if set_experiment() is called
experiment_id ="{experiment_id}",
parameters=...)
In the first line, we are setting an experiment name that should include a real path in Databricks (like /User/me/my_exp_1). In the second line, put all project things altogether and execute the project on a new automated cluster. Alternatively, the experiment_id can be passed into mlflow.run() instead of setting the experiment by name. There are several benefits that we can get from the code above:
- Experiments can be generated dynamically based on your branch name as we discussed above.
- New automated cluster on each run allows us to make sure that we always have up-to-date dependencies.
- Because the code above can be executed using a local project folder, it's easy to start the project from a local computer or from DevOps host.
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for