AMO Data Mining Classes
Applies to:  SQL Server Analysis Services
Azure Analysis Services
SQL Server Analysis Services
Azure Analysis Services  Fabric/Power BI Premium
Fabric/Power BI Premium
Data mining classes help you create, modify, delete, and process data mining objects. Working with data mining objects includes creating data mining structures, creating data mining models, and processing the models.
For more information about how to set up the environment, and about Server, Database, DataSource, and DataSourceView objects, see AMO Fundamental Classes.
Defining objects in Analysis Management Objects (AMO) requires setting a number of properties on each object to set up the correct context. Complex objects, such as OLAP and data mining objects, require lengthy and detailed coding.
The following illustration shows the relationship of the classes that are explained in this topic.
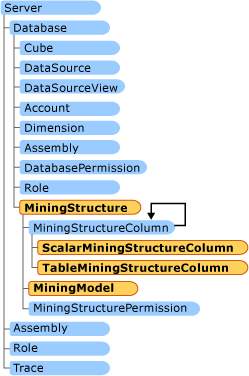
MiningStructure objects
A mining structure is the container for mining models. The structure defines all possible columns that the mining models may use. Each mining model defines its own columns from the set of defined columns in the structure.
A simple MiningStructure object is composed of: basic information, a data source view, one or more ScalarMiningStructureColumn, zero or more TableMiningStructureColumn, and a MiningModelCollection.
Basic information includes the name and ID (internal identifier) of the MiningStructure object.
The DataSourceView object holds the underlying data model for the mining structure.
ScalarMiningStructureColumn are columns or attributes that have single values.
TableMiningStructureColumn are columns or attributes that have multiple values for each case.
MiningModelCollection contains all mining models built on the same data.
A MiningStructure object is created by adding it to the MiningStructureCollection of the database and updating the MiningStructure object to the server, by using the Update method.
To remove a MiningStructure object, it must be dropped by using the Drop method of the MiningStructure object. Removing a MiningStructure object from the collection does not affect the server.
The MiningStructure can be processed using its own process method, or it can be processed when a parent object processes itself with its own process method.
Columns
Columns hold the data for the model and can be of different types depending on the usage: Key, Input, Predictable, or InputPredictable. Predictable columns are the target of building the mining model.
Single-value columns are known as ScalarMiningStructureColumn in AMO. Multiple-value columns are known as TableMiningStructureColumn.
ScalarMiningStructureColumn
A simple ScalarMiningStructureColumn object is composed of basic information, Type, Content, and data binding.
Basic information includes the name and ID (internal identifier) of the ScalarMiningStructureColumn.
Type is the data type of the value: LONG, BOOLEAN, TEXT, DOUBLE, DATE.
Content tells the engine how the column can be modeled. Values can be: Discrete, Continuous, Discretized, Ordered, Cyclical, Probability, Variance, StdDev, ProbabilityVariance, ProbabilityStdDev, Support, Key.
Data binding is linking the data mining column with the underlying data model by using a data source view element.
A ScalarMiningStructureColumn is created by adding it to the parent MiningStructureCollection, and updating the parent MiningStructure object to the server by using the Update method.
To remove a ScalarMiningStructureColumn, it must be removed from the collection of the parent MiningStructure, and the parent MiningStructure object must be updated to the server by using the Update method.
TableMiningStructureColumn
A simple TableMiningStructureColumn object is composed of basic information and scalar columns.
Basic information includes the name and ID (internal identifier) of the TableMiningStructureColumn.
Scalar columns are ScalarMiningStructureColumn.
A TableMiningStructureColumn is created by adding it to the parent MiningStructure collection, and updating the parent TableMiningStructureColumn object to the server by using the Update method.
To remove a ScalarMiningStructureColumn, it has to be removed from the collection of the parent MiningStructure, and the parent MiningStructure object must be updated to the server by using the Update method.
MiningModel Objects
A MiningModel is the object that allows you to choose which columns from the structure to use, an algorithm to use, and optionally specific parameters to tune the model. For example, you might want to define several mining models in the same mining structure that use the same algorithms, but to ignore some columns from the mining structure in one model, use them as inputs in another model, and use them as input and predict in a third model. This can be useful if in one mining model you want to treat a column as continuous, but in other model you want to treat the column as discretized.
A simple MiningModel object is composed of: basic information, algorithm definition, and columns.
Basic information includes the name and ID (internal identifier) of the mining model.
An algorithm definition refers to any one of the standard algorithms provided in Analysis Services, or any custom algorithms enabled on the server.
Columns are a collection of the columns that are used by the algorithm and their usage definition.
A MiningModel is created by adding it to the MiningModelCollection of the database and updating the MiningModel object to the server by using the Update method.
To remove a MiningModel, it has to be dropped by using the Drop method of the MiningModel. Removing a MiningModel from the collection does not affect the server.
After it is created, a MiningModel can be processed by using its own process method, or it can be processed when a parent object processes itself with its own process method.
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for