Azure Synapse Analytics
An Azure analytics service that brings together data integration, enterprise data warehousing, and big data analytics. Previously known as Azure SQL Data Warehouse.
5,384 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EA%3C/text%3E%3C/svg%3E)
Hi All.
I tried to use vacuum on Synapse Analytics and it is not working for me. The files are not deleted. I am using Spark pool (Spark 3.0). I had tried this:
from delta.tables import *
spark.sql("SET spark.databricks.delta.retentionDurationCheck.enabled = false")
deltaTable = DeltaTable.forPath(spark, "abfss://bronze@xxxxxxxxxxxxx .dfs.core.windows.net/delta/atxx.db/peoplexxxx/")
deltaTable.vacuum(retentionHours = 10)
I also tried this:
deltaTable.vacuum()
I have files from 6th of July.
Thanks for your help.
Kind regards,
Anaid
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMM%3C/text%3E%3C/svg%3E)
Hello @Anonymous and welcome to Microsoft Q&A.
You said you are using Synapse Analytics Spark 3.0, yet the commands you used reference databricks. I am a little fuzzy on the relation here. While both Synapse and Databricks use Spark, they are not the same product.
Could you try something like
spark.sql("VACUUM delta.{0}".format(delta_table_path)).show()
T
Thanks Matin!
I tried that, but it didn't work.
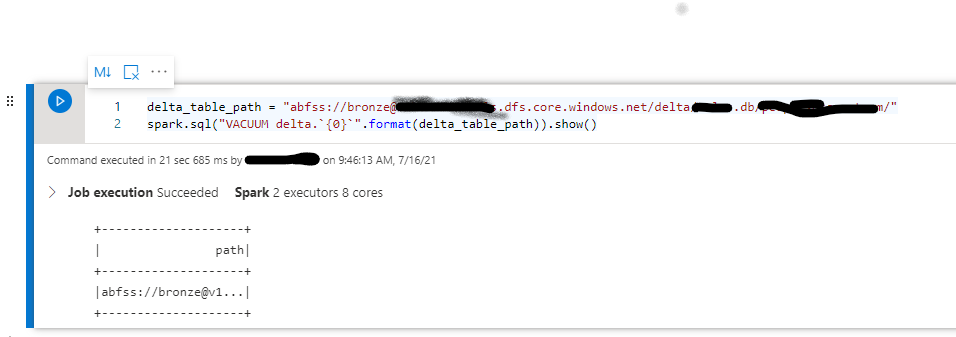 ]1
]1
I have files from the 6th of July and they're still there.
Kind regards,
Anaid
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EC%3C/text%3E%3C/svg%3E)
I am seeing the same behaviour as @Anonymous
I have a delta table that I have added some rows (23), deleted the rows, added the rows back in again three times so the underlying parquet files have 92 rows.
If I query the raw parquet files using sql serverless I can see the the 92 rows
If I query the raw parquet files using delta I only see the 23 rows.
If I use a spark notebook to read the data via:
var deltaTable = DeltaTable.ForPath(pathToDeltaTable);
deltaTable.ToDF().Show();
I see 23 rows.
If I run:
deltaTable.History().Show();
I see the expected set of write and delete operations.
I've ran
deltaTable.Vacuum();
(no results show for the above command and unsure what way you see the output if any)
I've ran
spark.Sql($"VACUUM delta.{pathToDeltaTable}").Show();
I see the result:
+--------------------+
| path|
+--------------------+
|abfss://container@sto...|
+--------------------+
But it appears as if the underlying data does not get VACUUMED and so I am left with stale data. I still see the 92 rows in my SQL Serverless query indicating that the raw data still exists in the lake folder.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ERA%3C/text%3E%3C/svg%3E)
You said you are using Synapse Analytics Spark 3.0, yet the commands you used reference databricks. I am a little fuzzy on the relation here. While both Synapse and Databricks use Spark, they are not the same product.
That is what leaves Synapse so confusing, the delta documentation actually references the "databricks" environment variables for delta

So if the "databricks" variable is wrong, what is it for Delta?
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EAS%3C/text%3E%3C/svg%3E)
Delta Lake has a safety check to prevent you from running a dangerous VACUUM command. If you are certain that there are no operations being performed on this table that take longer than the retention interval you plan to specify, you can turn off this safety check by setting the Spark configuration property spark.databricks.delta.retentionDurationCheck.enabled to false. The default retention threshold for vacuum is 7 days (168 hours).
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EHH%3C/text%3E%3C/svg%3E)
I got the compressing and vacuuming to work in a Synapse pyspark notebook with this code. Hope this helps!
from pyspark.sql.functions import *
from pyspark.sql.types import *
numOfFiles = 1
deltaPath = "abfss://******@yourstorageaccountname.dfs.core.windows.net/publish/data_table_name"
(spark.read
.format("delta")
.load(deltaPath)
.repartition(numOfFiles)
.write
.option("dataChange", "false")
.format("delta")
.mode("overwrite")
.save(deltaPath))
spark.sql("SET spark.databricks.delta.retentionDurationCheck.enabled = false")
spark.sql("VACUUM `publish`.`data_table_name` RETAIN 0 HOURS").show()
Thanks @Heimo Hiidenkari that worked for me, I have ran the VACUUM after setting the
SET spark.databricks.delta.retentionDurationCheck.enabled = false
And I now see the data being deleted.