Azure Data Factory
An Azure service for ingesting, preparing, and transforming data at scale.
11,641 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.

Hi,
I am calling JIRA api and it is returning this result
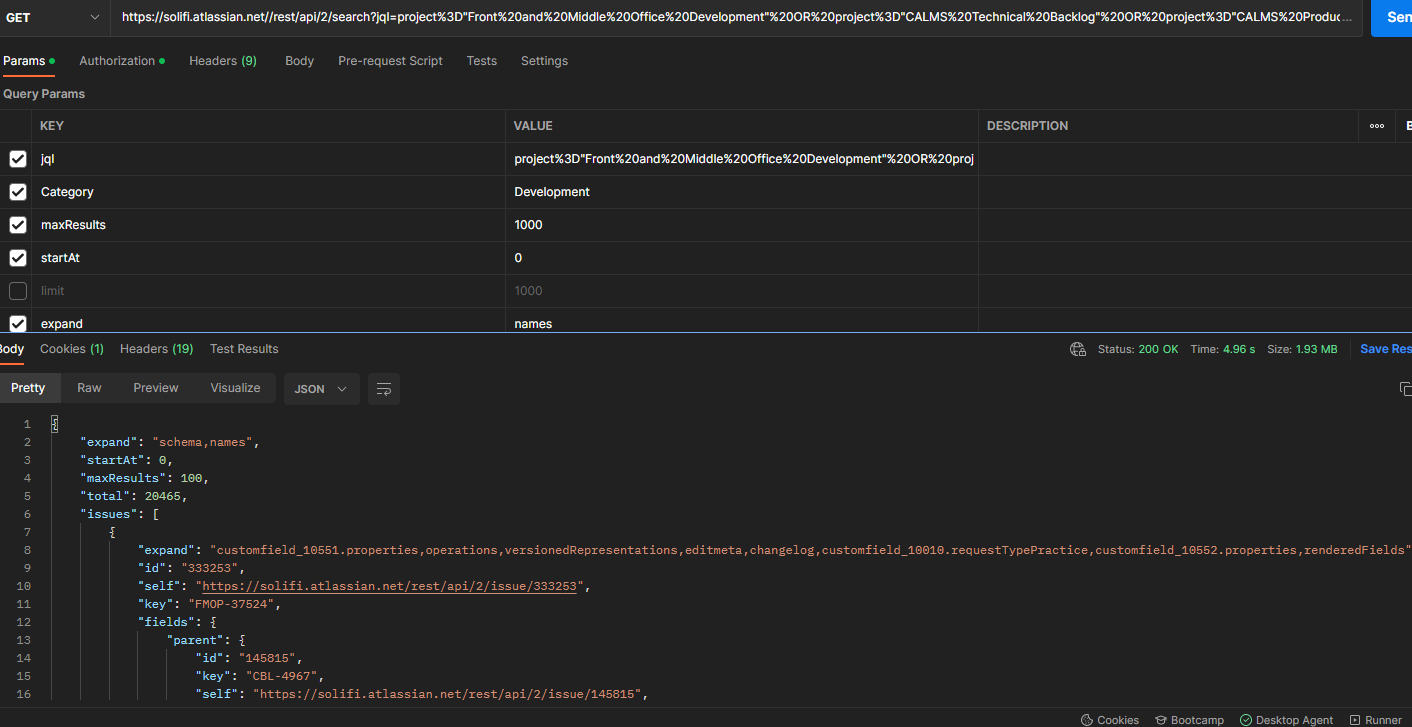
We can see that the total results are 20000 but it is returning only 100 results in a single page . I searched a lot and came to know that this is the restriction of JIRA RESt api and the max records in one call will be 100 only.
I thought of using startAT parameter and then break it into multiple queries as
Query 1
https://[yoursitename].atlassian.net/rest/api/2/search?jql=ORDER%20BY%20Created&maxResults=100&startAt=0
Query 2
https://[yoursitename].atlassian.net/rest/api/2/search?jql=ORDER%20BY%20Created&maxResults=100&startAt=100
Query 3
https://[yoursitename].atlassian.net/rest/api/2/search?jql=ORDER%20BY%20Created&maxResults=100&startAt=200
and so on.
I want to implement the above logic in adf to get all the result set by different iterations based on startAT value and then combining all the result sets into a single json file but i am confused about the work flow . Can anybody suggest how can we implement the above logic inside adf ? Which activities do we really need and how to pass the value to startAT dynamically.
Thanks
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMM%3C/text%3E%3C/svg%3E)
Hello @Amar Agnihotri and welcome back to Microsoft Q&A.
While you could get the data using the Copy activity REST pagination feature, it looks like you want to split into multiple copy activities to do things faster because of small page size and large result set. Is this correct?
Do note that splitting up into multiple copy activities also means making many small output files because ADF doesn't do append type writes to files. To end up with a single file, have another copy activity afterwards to merge the files.

So there are a few parts to doing this. I'm assuming you want to put the copy activity inside a for each loop and do it very parallel.
The first step is to generate a set of items to iterate over. This would be a value for each page/call. For this we need to know how many results total there are. Use a web activity to get the total results like in your screenshot.

Create a list/array type variable. Use Set Variable to create all the elements at once, using the range function.
total / maxResults = number of pages
if ( 0 < (total % maxResults) ) then we need to add another page for remainder
Put together, this takes the form of:
@range(0,
if(less(0,mod(int(variables('total')),pipeline().parameters.maxResults)),
add(1,div(int(variables('total')),pipeline().parameters.maxResults)),
div(int(variables('total')),pipeline().parameters.maxResults))
)
This would output an array of integers [0,1,2,3 ... 202, 203, 204]
This is the startAt value divided by maxResults (100). We pass this array to the ForEach. In the copy activity we will need to multiply by maxresults (100).
@mul(item(), pipeline().parameters.maxResults)
This value is not only used in the api call, but also in the parameterized sink dataset filename, so we don't overwrite the results of every other call.
Hi @MartinJaffer-MSFT ,
Thanks for the reply and the idea. I have understand the logic but still one confusion is there . In the ForEach the copy activity will get the data for each iteration based on different startAt values but what would be the sink dataset . It seems that it will store the file in the sink dataset with different names and then once when i will be having 200 or 300 output json files (If i save the files as json) then after the ForEach another copy activity will merge those files. Correct me if i am wrong . I don't want to save the output of each iteration in a data lake . I want to save only the single output json file after merge activity. Please clear my confusion
Hi @Amar Agnihotri , sorry for the delay, I was sick for a bit.
You are correct that the first copy will create a file for each iteration. The second will take all those and merge them. I did forget about deleting the iteration-files. So here is an example pipeline where I merge and then clean up.
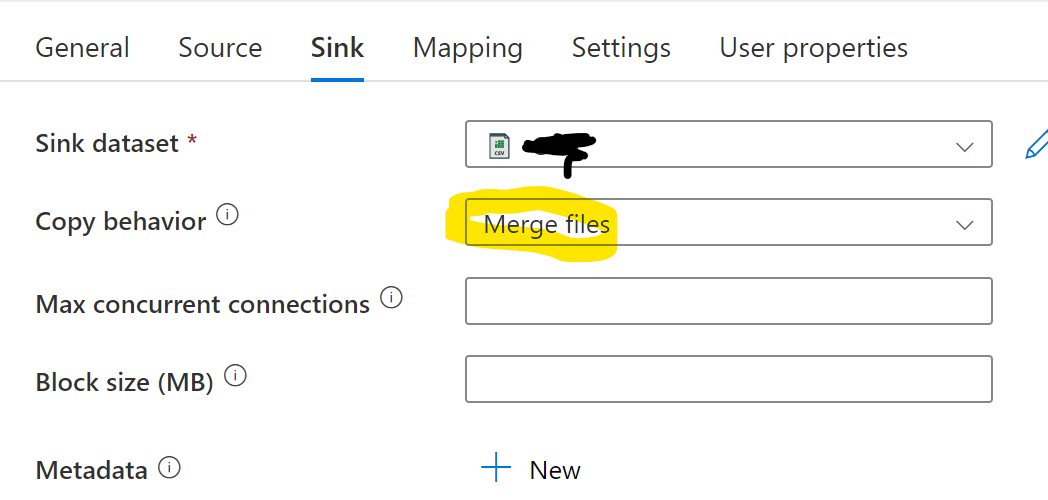
I set up 3 simple json files in my ADLS gen2 container "data", under paths
input/tomerge/short1.json
input/tomerge/short2.json
input/tomerge/short3.json
I made a json type dataset pointing to the folder, so input/tomerge/ , with the filename left blank.
The copy activity source set up using wildcard path input/tomerge and short*.json .
For the sink dataset, I also chose json type. In it I chose to give an output file name. If I do not give a file name, then it defaults to data_{pipeline run id}.json .
I do not import any schemas, nor do mapping.
The sink copy behavior is "merge files".
On success of the copy activity, I do a delete activity. I choose the dataset used in copy activity's source. Since it is pointed at the folder itself, rather than file or wildcard, the entire folder and contents are deleted.
Hope you are feeling good and recharged now . Thanks for the clearing the steps and want to tell you that i have successfully implemented all these steps. My pipeline is merging all the json files into single json and then delete activity is deleting the iterative json files from the container.
I have one question, though. Rather saving different json files from the iterations and combining them all, I was thinking of doing all this on the fly. I want to use the append activity which which append all the output to the array variable and then i want to use copy activity to copy that entire output. But I am having these doubts about this approach -
Please tell me what do you think of these above questions .
I am accepting your answer as a solution since it helped me implementing the process.
Thanks
Hmm, well, that is a murky area.
if you used Web activity and append, it would be like
[
"{ \"id\":1, \"val\":\"a\"}",
"{ \"id\":2, \"val\":\"b\"}",
"{ \"id\":3, \"val\":\"c\"}",
]
Or it might be without the \ and enclosing " .
The difficulty next is writing. I know 2 ways:
{ "myAdditionalColumnName":[data1,data2,data3]} In both cases, the json() function would help remove the escaping.
Hmmm... The append activity itself theoretically should be faster than the copy, However, there is a delay between one activity finishing and the next one starting -- not something either of us has control over, it is due to the achitecture -- this approach might actually be slower because there are now 2 activities inside the forEach. It might be cheaper, though, because there are fewere copy activities, meaning less writes to storage plus less copy activity cost. The append activity has a flat cost.
I'd be wary of hitting any limits in web activity body size. While there is a limit to how big a variable can get, it is not something I would worry about yet.
Thanks @MartinJaffer-MSFT i understood it now . I have already faced this kind of scenario where i pulled the user activity data using REST api and the final json was very deformated and that's whyi had to use the azure function to format the json and i believe using azure function incur much cost to the pipeline.

@MartinJaffer-MSFT : Will it be possible to share some more snapshots of the variables and how you have setup the variables within the web connector.
The Web activity "Get total results" is not something I implemented, as it is specific to the api in question. So your case may be different than Amar's . @Diptesh Bose