Not Monitored
Tag not monitored by Microsoft.
37,795 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EAA%3C/text%3E%3C/svg%3E)
I am in the process of creating a pipeline for Continuous training of several ML models using Azure DevOps.
Within the Pipeline, I use Azure CLI with help of azure ml extension to submit training jobs for each of the ML models. I have attached an image below to give you an idea of how the pipeline looks.
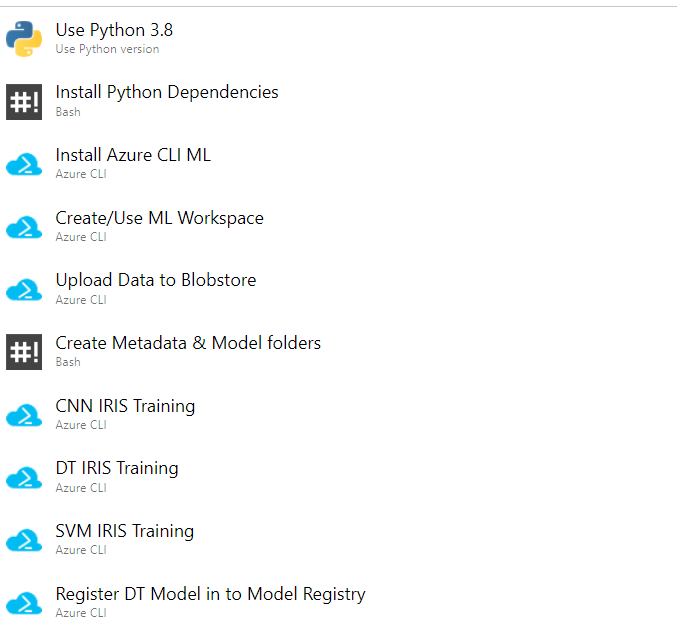
The main problem I faced was that when I wanted to use TensorFlow, several dependency issues came up. So I decided to use the base image which came with TensorFlow 2.7.0 pre-installed, and then add the rest of the needed libraries. The base image is mcr.microsoft.com/azureml/curated/tensorflow-2.7-ubuntu20.04-py38-cuda11-gpu:23.
But now when I run the pipeline I get an error saying that the disk is full.

To mitigate the issue, I tried using a better compute instance, I was initially using 2 cores which I then upgraded to 4, and still, the error persists. FYI, The data that I am using is not big since I am trying to build the architecture of the pipeline.
I created an azure virtual machine and attached it as a compute for training the model, and yet I get another error.
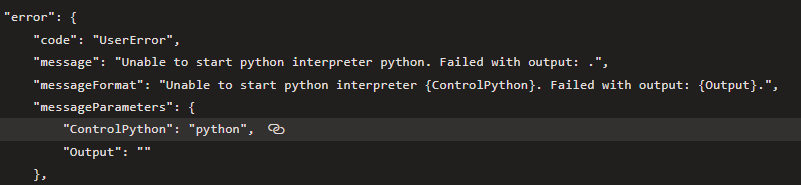
What should I do now? How can get past this issue? Is there a better to train the models than this? My aim is to train the models in the CI pipeline and deploy the best one in a release pipeline.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ERM%3C/text%3E%3C/svg%3E)
@Azure Account 25 Thanks for the question. Did you change the account access keys?. Can you please share the Document/sample that you are trying.
If yes, Updated storage account key with below command, Change storage account access keys - Azure Machine Learning | Microsoft Learn
az ml workspace sync-keys -w myworkspace -g myresourcegroup