Azure Data Factory
An Azure service for ingesting, preparing, and transforming data at scale.
11,625 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ELK%3C/text%3E%3C/svg%3E)
Source: CosmosDB
Sink: Azure Storage Blob
Number of documents in Source: 5,000
Size of each document in Source: 1 MB
I'm looking for details on how to create an Until loop for a copy activity which can read from the source with a page size of 50 and create multiple blobs in the sink instead of just one giant blob. So in my example, I'm looking to have 5000/50 =100 blobs in the sink instead of just one single blob.
If I had chosen 'File' as my sink, I think I do have an option for 'Max row per file' which I could have set to 50. But with blob as the sink, I'm unable to get this working. Is there any documentation I can refer to get this working?
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMM%3C/text%3E%3C/svg%3E)
Hello and welcome to Microsoft Q&A @Lakshman Kumar Veerarajan
So I understand you want finer control over how your output is written, in specific breaking into smaller files.
If I had chosen 'File' as my sink, I think I do have an option for 'Max row per file' which I could have set to 50. But with blob as the sink, I'm unable to get this working.
Does your sink dataset look kind of like this legacy type?:
{
"name": "AzureBlob1",
"properties": {
"linkedServiceName": {
"referenceName": "AzureBlobStorage1",
"type": "LinkedServiceReference"
},
"annotations": [],
"type": "AzureBlob",
"typeProperties": {
"fileName": "",
"folderPath": "adftutorial/iter"
}
},
"type": "Microsoft.DataFactory/factories/datasets"
}
The above is an older form of dataset, dealing with blobs in general. There are newer versions which DO allow the "Max row per file".
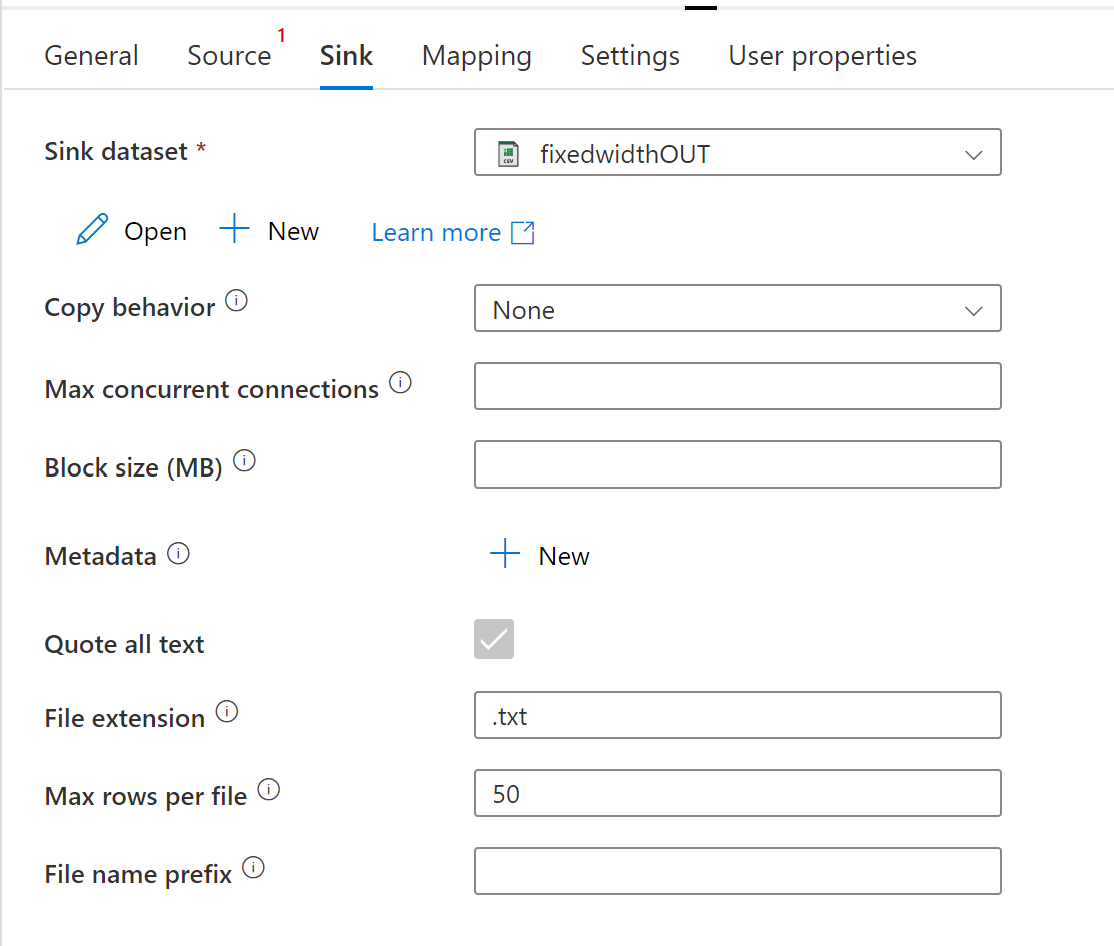
While Delimited text does allow rows for file, JSON format does not because it is not tabular -- it isn't in a form of rows. JSON is heirarchical.
If you want 1 file per page, that is easy enough to do. I just got confused whether you wanted to split into even smaller chunks.
@MartinJaffer-MSFT thanks for your reply.
> So I understand you want finer control over how your output is written, in specific breaking into smaller files.
Yes, your understanding is correct.
My source is CosmosDB, so yes, the data is stored as JSONs rather than rows. I'm happy to try out 1 file per page, if you have pointers on how we can get that accomplished as well. Note that in this case, I'll have to rely on CosmosDB's continutationToken and nextLinks to iterate over all the records that exists in the CosmosDB collection.
My sink is indeed AzureBlob. Can you please elaborate on what's the newer versions which DO allow the "Max row per file"?

TLDR, go to the bottom @Lakshman Kumar Veerarajan . There are 2 solutions, bottom one is proven.
Okay, I have managed to get 1 cosmosdb document per file. In this I used a Batch size of 1 in CosmosDbMongoDb source dataset (it had trivial small data), and for sink I used a delimited text type dataset, pointing to a blob folder rather than a single file, and did 1 Max rows per file. I emptied the schema and mappings, so it did write data, but is not longer in JSON form. It also skips the $oid. If your documents are uniform in schema, we could then reconstitute them in a second copy, but 1MB is a lot of mapping to do... Hmmm.
I looked at the cosmos connector document for a refresher and saw:
You can use the Azure Cosmos DB for MongoDB connector to:
Copy data from and to the Azure Cosmos DB for MongoDB.
Write to Azure Cosmos DB as insert or upsert.
Import and export JSON documents as-is, or copy data from or to a tabular dataset. Examples include a SQL database and a CSV file. To copy documents as-is to or from JSON files or to or from another Azure Cosmos DB collection, see Import or export JSON documents.
This last one suggests your ask should be easy and I'm just having a blind moment. Or there is a missing link. Found it
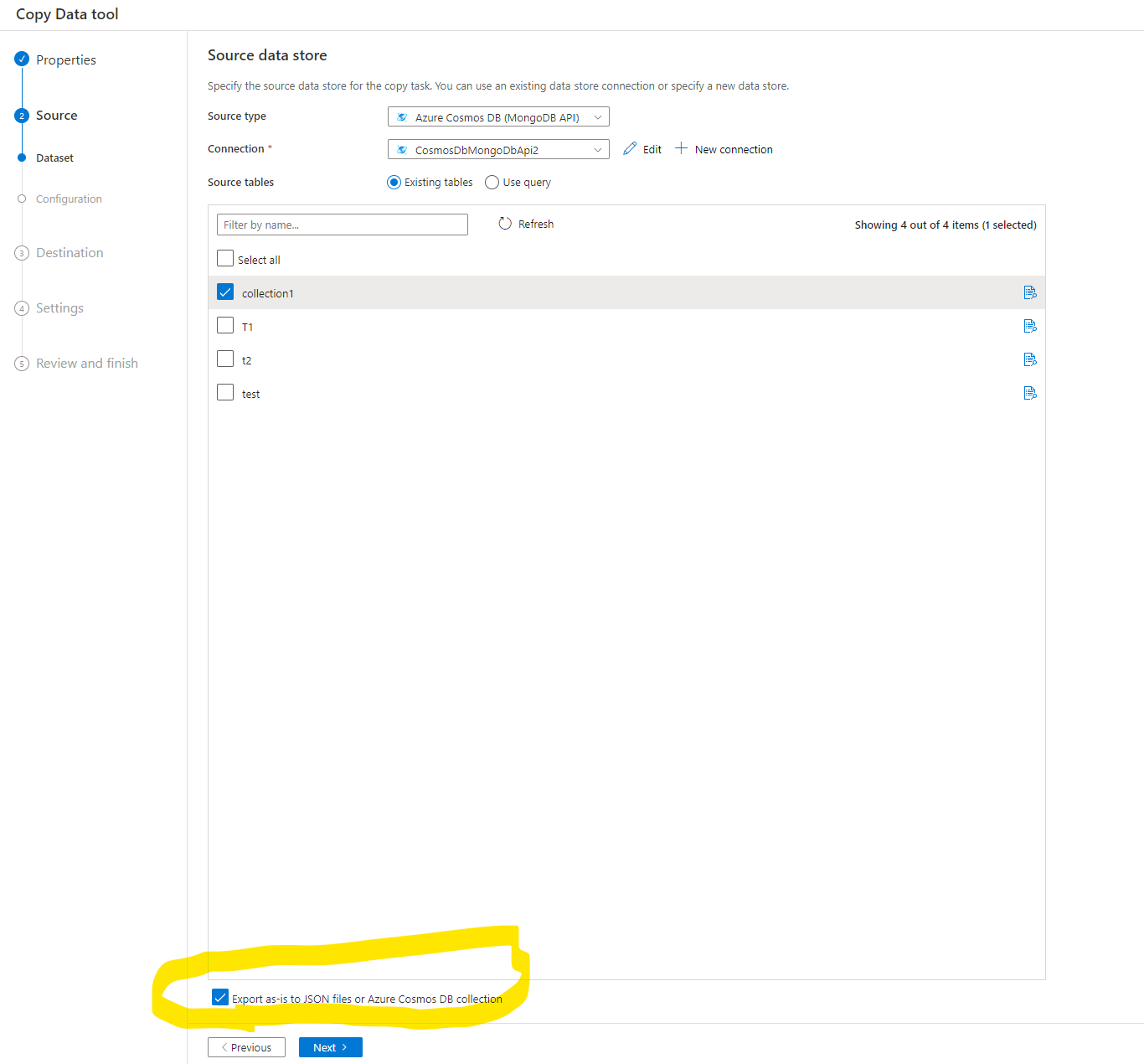
.... aaand nope that just made one file. Okay. We are gonna do this the hard way.
Earlier, I somehow thought you were using REST api on it... Probably because "continuationToken" and "nextLinks" are usualy seen in context of REST apis. If it is outside this context, then I must not know enough about CosmosDB
The CosmosDB cursorMethods include sort, limit, and skip. Taken together, these can specify a single record. I can use these in a loop. Given you have 5000 documents, an until loop would take a while. 5000 instances of CopyActivity are likely to be expensive either way. I can make it faster by making parallel in a forEach. As to what ForEach iterates over, I can generate the cursorMethods beforehand because we know how many records there are.
Okay. I got it working. For this, I recommend parameterize the sink dataset. So we can control the filenames and make them unique to each record.
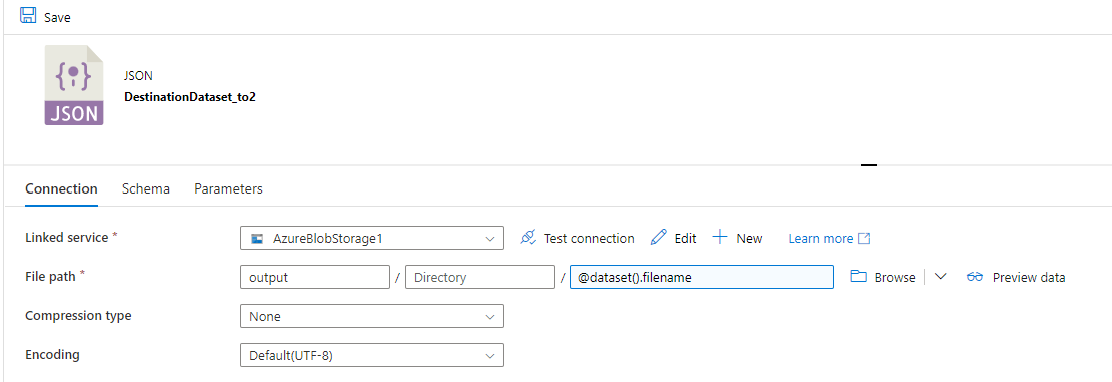
I'm going to paste my pipeline JSON below. It is mostly straightforward. I use a Set Variable activity to assign a series of numbers to an array type variable named "pages". @range(0 , 500) This will be used in items in ForEach, and each number will be how many records to skip in the Copy Activity cursor stuff.
The weird bit, is somehow the range put an array inside an array. I this is not behavior I expected. So in the ForEach items I did @variables('pages')[0] to peel away a layer.

My test data had only 2 records, which is trivial, but yours has many. I don't know if Mongo results are deterministic, so add a sort order and do not let an insert/delete job happen while this job runs. We want to keep order consistent so the skip always skips the same records in order. Otherwise it might skip the wrong ones.
Given the limit is 1, the batch size might be redundant.
{
"name": "cosmosToManyJson",
"properties": {
"activities": [
{
"name": "Set variable1",
"type": "SetVariable",
"dependsOn": [],
"userProperties": [],
"typeProperties": {
"variableName": "pages",
"value": [
"@range(0,2)"
]
}
},
{
"name": "ForEach1",
"type": "ForEach",
"dependsOn": [
{
"activity": "Set variable1",
"dependencyConditions": [
"Succeeded"
]
}
],
"userProperties": [],
"typeProperties": {
"items": {
"value": "@variables('pages')[0]",
"type": "Expression"
},
"activities": [
{
"name": "Copy_to2_copy1",
"type": "Copy",
"dependsOn": [],
"policy": {
"timeout": "0.12:00:00",
"retry": 0,
"retryIntervalInSeconds": 30,
"secureOutput": false,
"secureInput": false
},
"userProperties": [
{
"name": "Source",
"value": "collection1"
},
{
"name": "Destination",
"value": "output//"
}
],
"typeProperties": {
"source": {
"type": "CosmosDbMongoDbApiSource",
"batchSize": 1,
"cursorMethods": {
"limit": 1,
"skip": {
"value": "@int(item())",
"type": "Expression"
}
}
},
"sink": {
"type": "JsonSink",
"storeSettings": {
"type": "AzureBlobStorageWriteSettings"
},
"formatSettings": {
"type": "JsonWriteSettings",
"filePattern": "setOfObjects"
}
},
"enableStaging": false,
"validateDataConsistency": false
},
"inputs": [
{
"referenceName": "SourceDataset_to2",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "DestinationDataset_to2",
"type": "DatasetReference",
"parameters": {
"filename": {
"value": "@concat('cosmos',string(item()))",
"type": "Expression"
}
}
}
]
}
]
}
}
],
"variables": {
"pages": {
"type": "Array"
}
},
"annotations": []
}
}