C#
An object-oriented and type-safe programming language that has its roots in the C family of languages and includes support for component-oriented programming.
10,648 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ETZ%3C/text%3E%3C/svg%3E)
My scenario is that first web page has 1000 url from where i have to visit each url programmatically and each url has again many which which i need to visit and read some data.
i am looking for best way to traverse these 2 different set of url asynchronously or by thread to complete the task very quickly
say check this url https://info.creditriskmonitor.com/Directory/
Alabama has 278 active companies. i need to click on that link https://info.creditriskmonitor.com/Directory/StateAAL.htm then more data will load where another links will be there like 1ST JACKSON BANCSHARES, INC. (United States) i need to visit all Business Name links
again from this https://info.creditriskmonitor.com/Report/ReportPreview.aspx?BusinessId=17322454
from Business Name links i need to go to each url and read this table content which i need to store in db.
here is the screen shot whose data i need to store in db
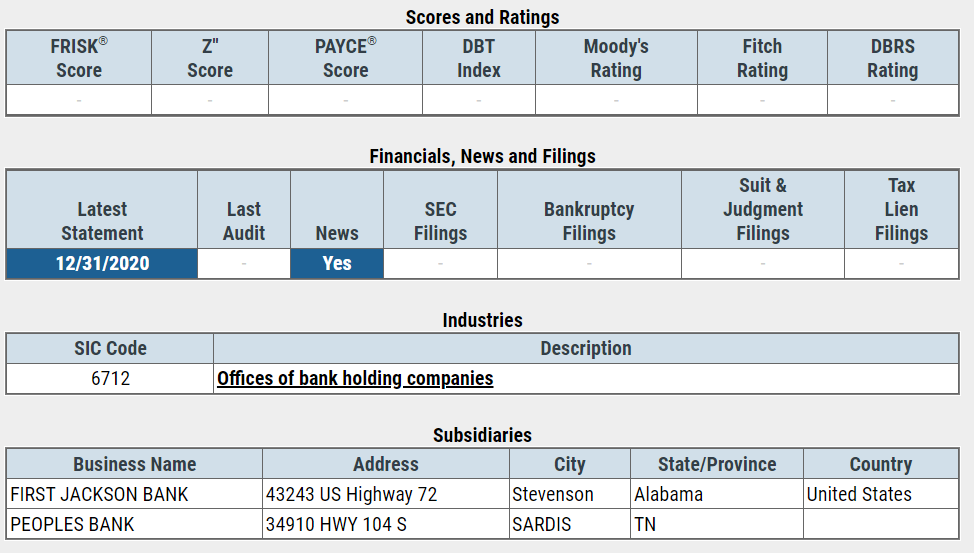
So now it is clear that i need to visit lots of links to grab a particular data which will be stored in db.
if i traverse each link one by one then it is tasking lots of time. so i am looking for Elegant way to traverse links with a multiple thread.
please share few best idea with sample code if possible.
For a long time i was searching google to find out best way to handle me scenario. i got few. here i am sharing few code sample. please tell me which one should be best for my scenario but my case is bit different that first page has many url and when i visit those url then more url will appear in second page which i need to traverse again.
below sample code just traverse only one set of url but mine has two set of url.
please suggest best way to refactor below code.
code taken from https://markheath.net/post/constraining-concurrent-threads-csharp
var urls = new [] {
"https://github.com/naudio/NAudio",
"https://twitter.com/mark_heath",
"https://github.com/markheath/azure-functions-links",
"https://pluralsight.com/authors/mark-heath",
"https://github.com/markheath/advent-of-code-js",
"http://stackoverflow.com/users/7532/mark-heath",
"https://mvp.microsoft.com/en-us/mvp/Mark%20%20Heath-5002551",
"https://github.com/markheath/func-todo-backend",
"https://github.com/markheath/typescript-tetris",
};
1st Approach
-------------
var client = new HttpClient();
foreach(var url in urls)
{
var html = await client.GetStringAsync(url);
Console.WriteLine($"retrieved {html.Length} characters from {url}");
}
2nd Approach
-------------
var maxThreads = 4;
var q = new ConcurrentQueue<string>(urls);
var tasks = new List<Task>();
for(int n = 0; n < maxThreads; n++)
{
tasks.Add(Task.Run(async () => {
while(q.TryDequeue(out string url))
{
var html = await client.GetStringAsync(url);
Console.WriteLine($"retrieved {html.Length} characters from {url}");
}
}));
}
await Task.WhenAll(tasks);
3rd Approach
-------------
var allTasks = new List<Task>();
var throttler = new SemaphoreSlim(initialCount: maxThreads);
foreach (var url in urls)
{
await throttler.WaitAsync();
allTasks.Add(
Task.Run(async () =>
{
try
{
var html = await client.GetStringAsync(url);
Console.WriteLine($"retrieved {html.Length} characters from {url}");
}
finally
{
throttler.Release();
}
}));
}
await Task.WhenAll(allTasks);
4th Approach
-------------
// let's say there is a list of 1000+ URLs
string[] urls = { "http://google.com", "http://yahoo.com", /*...*/ };
var client = new HttpClient();
var options = new ParallelOptions() { MaxDegreeOfParallelism = 20 };
// now let's send HTTP requests to each of these URLs in parallel
await Parallel.ForEachAsync(urls, options, async (url, cancellationToken) =>
{
var html = await client.GetStringAsync(url, cancellationToken);
});
Looking for best guide line. Thanks
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EBS%3C/text%3E%3C/svg%3E)
1 is the slowest (fetching urls, one after another)
4 is the cleanest multithread
2 is the best if new urls are discovered during the fetch as they can be feed to the queue.
you might break 2 into two parts. a url discovery pass (feed the queue), and url process pass (drain the queue). you would need to support empty queue (sleep retry and exit command)
Thanks for your reply.
Can you please post a sample code which help me to construct the code. things are not clear what you said you might break 2 into two parts. a url discovery pass (feed the queue), and url process pass (drain the queue). you would need to support empty queue (sleep retry and exit command)
i have to 2 set of urls. first url is https://info.creditriskmonitor.com/Directory/ where active company number is showing which is another url. so i need to iterate in all url of active company and store in list. later i need to iterate in list to visit each url and from that url i need to read some data.
how can i write a code which store active company url in concurrent queue. another method will be there which will monitor queue and read url from that queue.
things are not getting very clear that how do i compose my code which does the job very quickly with multi threading but no two thread will not access same url.
Can you please post a sample code which help me lots to compose the code to handle my scenario with multi threading.
Thanks