Azure Databricks
An Apache Spark-based analytics platform optimized for Azure.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ENK%3C/text%3E%3C/svg%3E)
Have a table which has below sample data as
Table A:
Id, start date, end date
1, 2022-10-10, 2022-10-12
I want a new column with individual date of the series as below in the output as below:
Id, start date, end date, NewDerivedCol
1, 2022-10-10, 2022-10-12, 2022-10-10
1,2022-10-10,2022-10-12, 2022-10-11
1,2022-10-10,2022-10-12, 2022-10-12
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ESM%3C/text%3E%3C/svg%3E)
Hi @NIKHIL KUMAR ,
Thanks for posting this question in Microsoft Q&A platform and for using Azure Services.
Regarding the above Input dataset and required Output Dataset with New Column as Date Series, we can use below code in Databricks using Pyspark SQL functions:
from pyspark.sql import functions as F
df = df \
.withColumn('StartDate', F.col('StartDate').cast('date')) \
.withColumn('EndDate', F.col('EndDate').cast('date'))
display(df)
df.withColumn('NewDerivedCol', F.explode(F.expr('sequence(StartDate, EndDate, interval 1 day)')))\
.show()
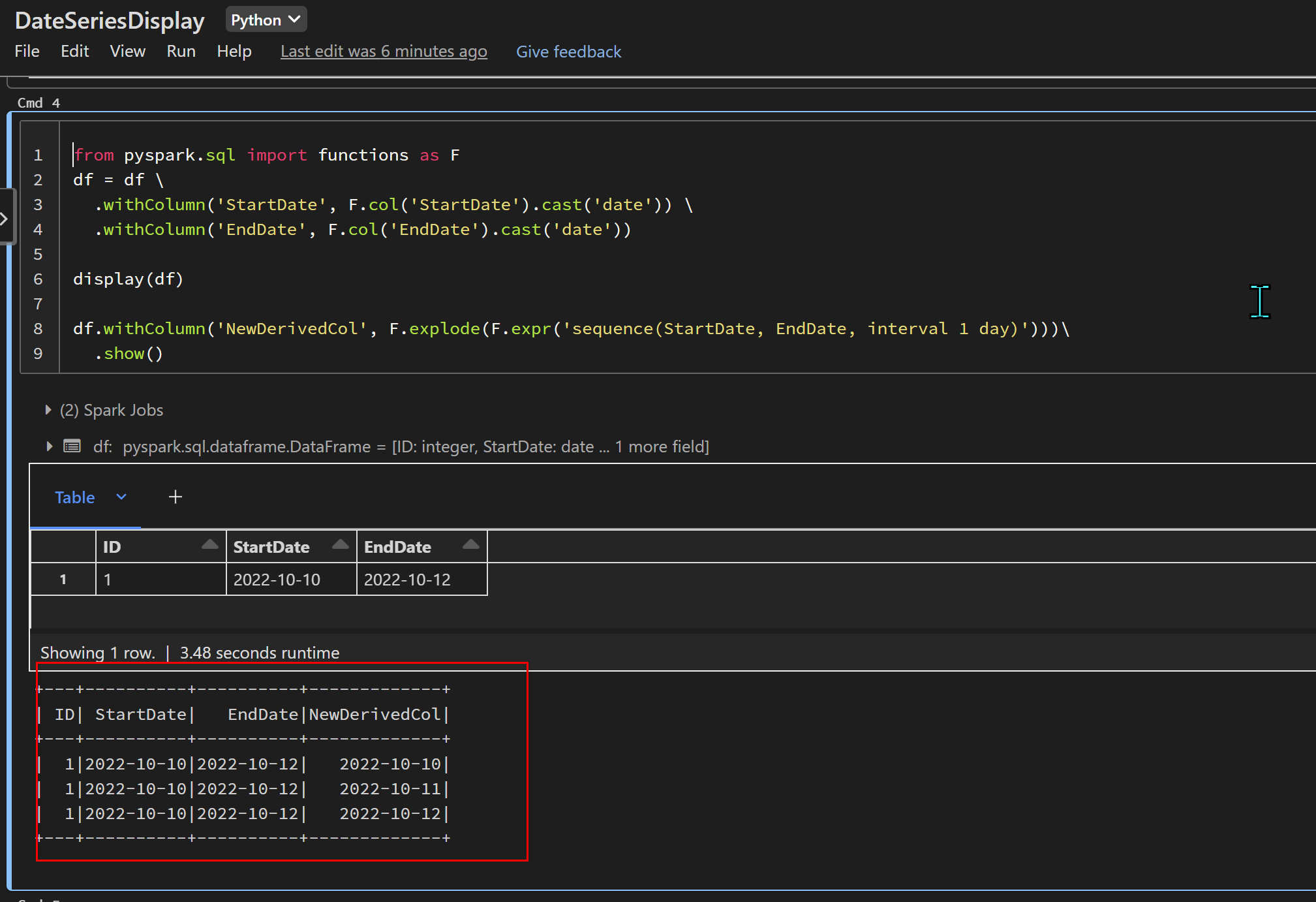
Here we have used Sequence function which generates an array of elements from start to stop (inclusive), incrementing by step. The type of the returned elements is the same as the type of argument expressions.
Supported types are byte, short, integer, long, date, timestamp.
It is used to create an array containing all dates between StartDate and EndDate.
This array can then be exploded using explode function which returns a new row for each element in the given array.
Reference Links: pyspark.sql.functions.explode.html
pyspark.sql.functions.sequence.html
Hope this will help. Please let us know if any further queries.
------------------------------
 or upvote
or upvote  button whenever the information provided helps you.
button whenever the information provided helps you.
Thank you @SSingh-MSFT , this perfectly works for the dataset I have in real time.