Azure Data Factory
An Azure service for ingesting, preparing, and transforming data at scale.
11,665 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMB%3C/text%3E%3C/svg%3E)
My company has a parallelized ADF pipeline to read 56 csv and insert them to the database using a data flow. Most files have less than 1000 rows, about 40K in total, very light stuff. But besides this taking about 10 minutes which is quite slow, the costs are unreasoably high.
After further inspection it looks like actual runtime is about 5 seconds, apparently we are paying for the cluster allocation time meaning quite literally more than 99% of the costs are spent on starting clusters. Furthermore it looks like it's starting a cluster per parallel activity instead queuing them and scaling the cluster based on workload which is what I would have expected.
Is there a way to achieve that so at least we only pay one startup instead of 56? What options do I have to optimize the costs? Is there a way to monitor the number of clusters/cores? If it wasn't for the costs I wouldn't have known.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ESM%3C/text%3E%3C/svg%3E)
Just checking in to see if the below answer helped. If this answers your query, do click Accept Answer and Up-Vote for the same. And, if you have any further query do let us know.
Just checking in to see if the below suggestion helped. If this answers your query, do click Accept Answer and Up-Vote for the same. And, if you have any further query do let us know.
Thanks for your reply.
For Parallel Data Flows, it is recommended at concepts-data-flow-performance-pipelines :
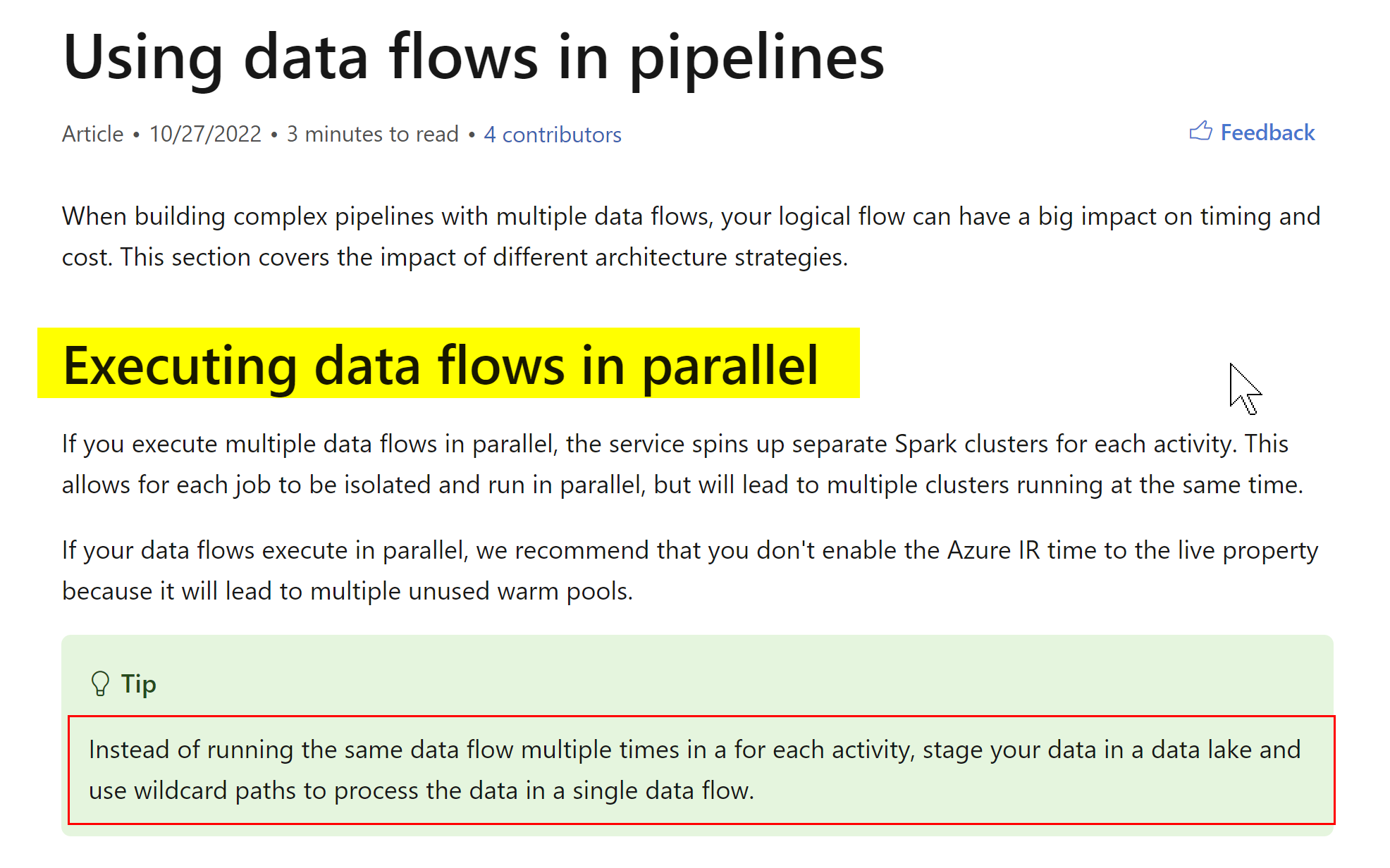
Additionally, as suggested by Expert @MarkKromer-MSFT here:
1: If you execute data flows in a pipeline in parallel, ADF will spin-up separate Spark clusters for each based on the settings in your Azure Integration Runtime attached to each activity.
2: If you put all of your logic inside a single data flow, then it will all execute in that same job execution context on a single Spark cluster instance.
3: Another option is to execute the activities in serial in the pipeline. If you have set a TTL on the Azure IR configuration, then ADF will reuse the compute resources (VMs) but you will still a brand-new Spark context for each execution.
All are valid practices and which one you choose should be driven by your requirements for your ETL process.
No. 3 will likely take the longest time to execute end-to-end. But it does provide a clean separation of operations in each data flow step.
No. 2 could be more difficult to follow logically and doesn't give you much re-usability.
No. 1 is really similar to #3, but you run them all in parallel. Of course, not every end-to-end process can run in parallel. You may require a data flow to finish before starting the next, in which case you're back in #3 serial mode.
Another useful Stackoverflow thread adf-best-practice-for-dataflow-in-parallel
Depending upon the other factors, you may go through Granular Billing for Azure Data Factory to analyze costs involved.
Video link demonstrating Granular Billling
Let me know if this helps. Please let us know in case of further queries.
------------------------------
 or upvote
or upvote  button whenever the information provided helps you.
button whenever the information provided helps you.
Welcome to Microsoft Q&A platform and thanks for using Azure Services.
As I understand your ask, you want to avoid the cost spent on spinning up of Clusters for the Data Flows. Please refer below reply and ask if you need more information.
Databricks "warm pool" concept could be utilized in this case. This will retain the cluster infrastructure by setting a TTL on the Azure Integration Runtime. It will reduce the startup time.
Create a new Azure IR, open the Data Flow properties and set a TTL value of 10 mins. Then, in the pipeline, change the Azure IR to the new IR you just created in the Execute Data Flow activities. Each activity must use that same Azure IR in order to take advantage of this warm pool capability.
Reference Link: azure-data-factory-data-flow-startup-time.html
Another useful Q&A link with details about TTL: azure-data-flow-activity-time.html
Hope this will help. Please let us know if you have further queries or issue.
------------------------------
or upvote button whenever the information provided helps you.
Hello, ShaktiSingh-MSFT, thanks for answering. This seems to have no effect on parallelized data flows, they'll still spin a cluster each. It works if I make them sequential but then the process is significantly slowed so it's not a good solution.