Azure Data Factory
An Azure service for ingesting, preparing, and transforming data at scale.
11,643 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EPV%3C/text%3E%3C/svg%3E)
Hi
I am curious to know if anyone out there build in 'plausibilty checks' in ADF.
On a daily base we load Parquet files from various producers in our SQLDB. Let me give two examples.
Example 1: Daily we get a snapshot of the payment agreements. Mostly that file contains around 8 million rows.
Example 2: Also daily we get the transactions done on those agreements. One day these might be 4 million transactions, another day 4.3 million transactions etcetera.
But around Christmas or other special events it can be more than 12 million rows.
Suppose on a normal day we only get 1 million transactions or 16 million agreements. Then almost for sure something went wrong on the producer side. And taking in that data might make a mess of our data warehouse.
So how do you, in a generic way, check that the number of records you receive are plausible?
And fail the pipeline if it is not?
How do you take care that it will take into consideration that on certain days/events like Christmas the number might be much higher?
Looking forward to your solutions
Regards
Ron

Hello @Poel van der, RE (Ron) ,
Thanks for posting queries in Microsoft Q&A Platform.
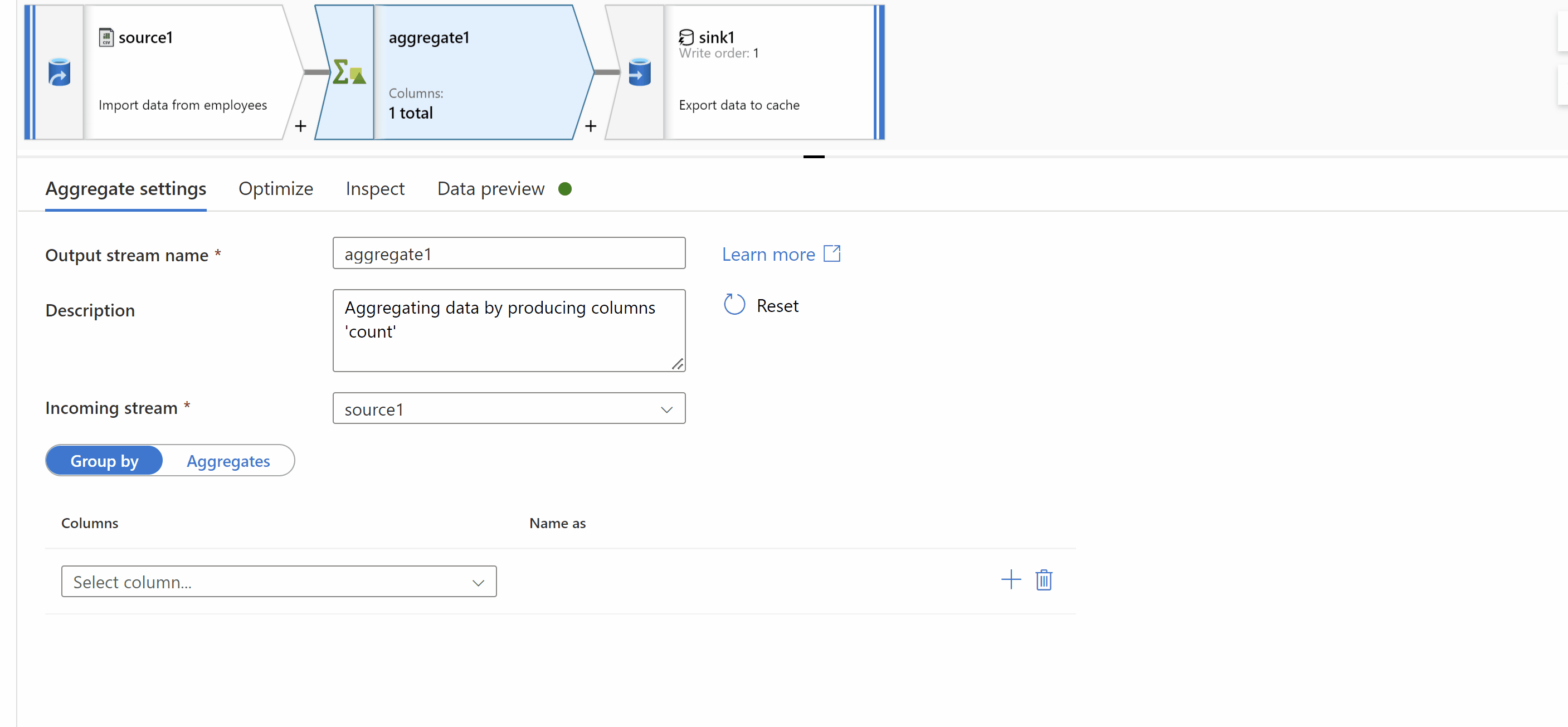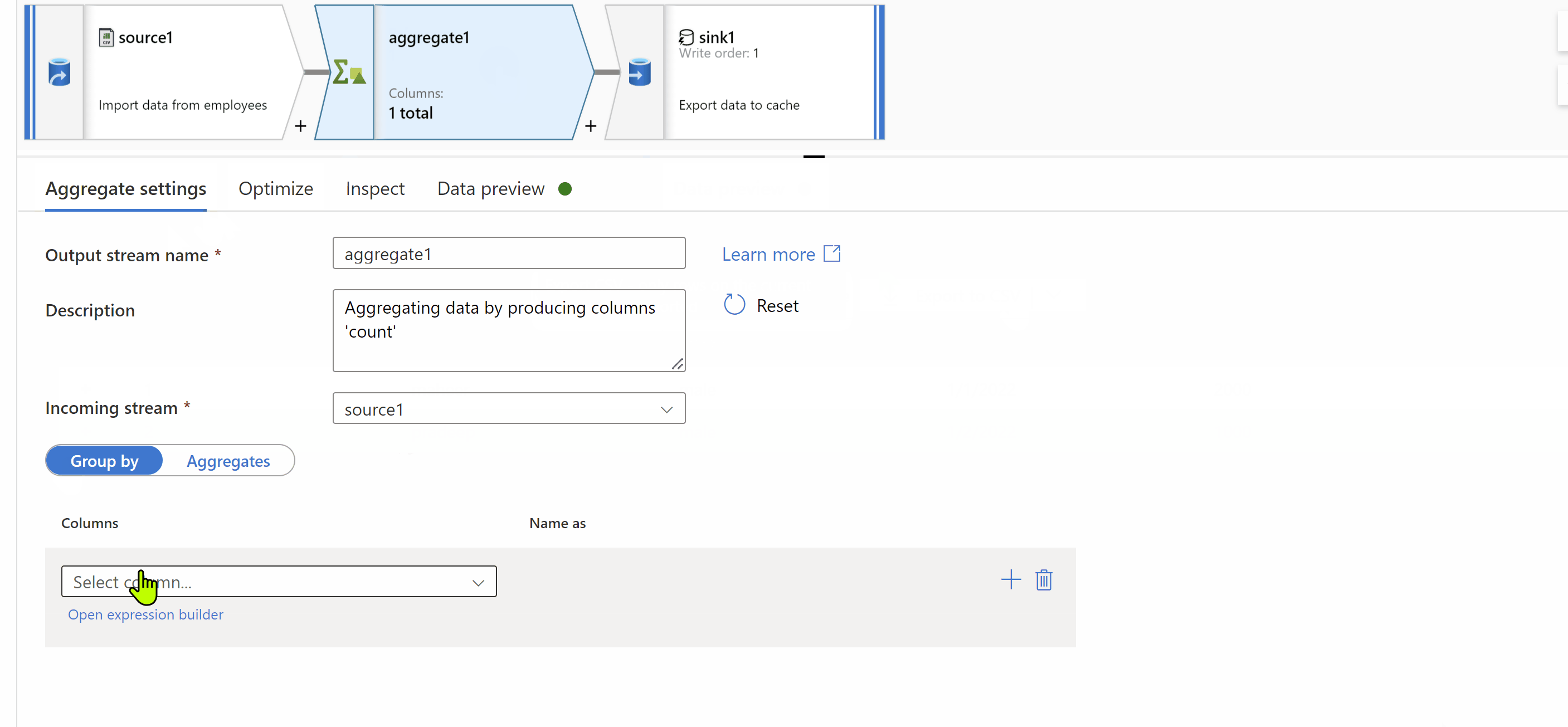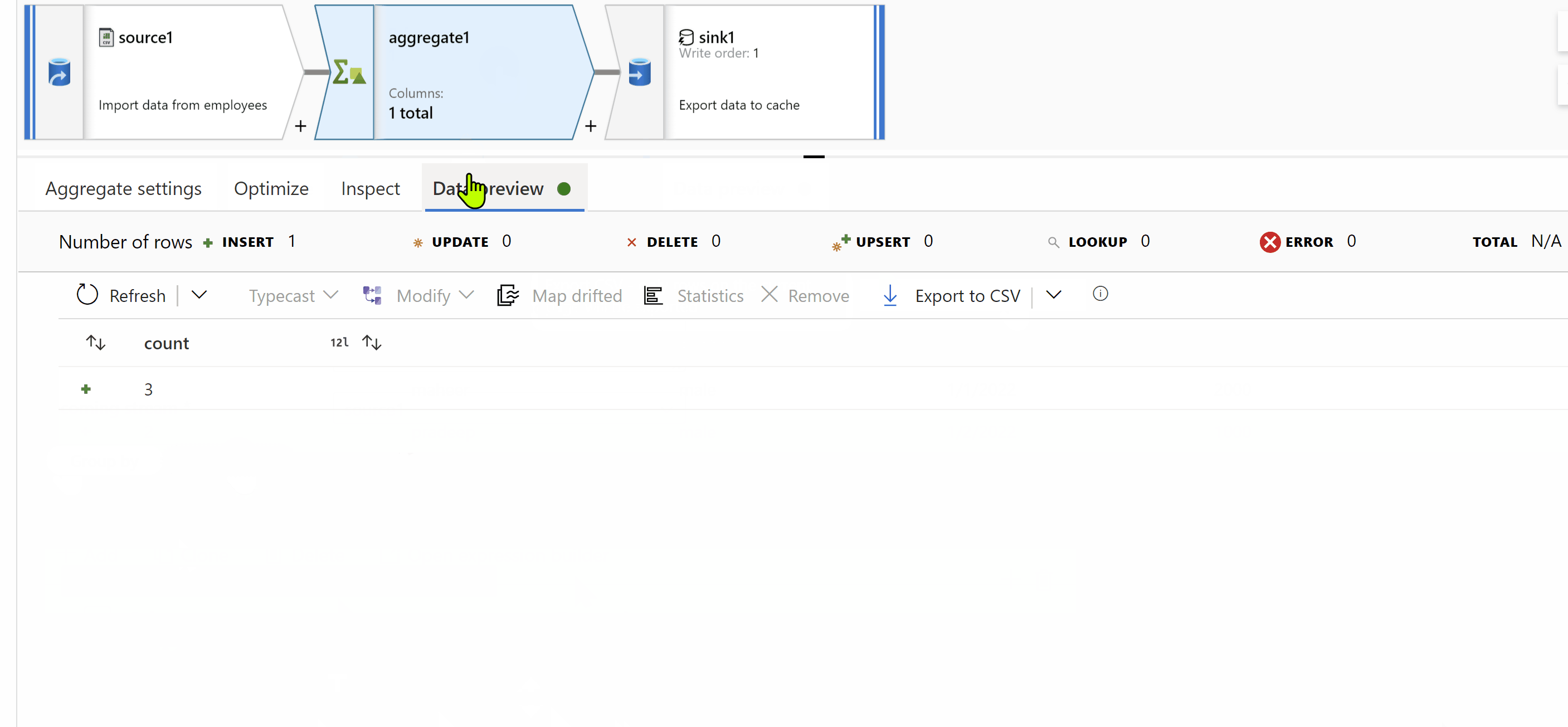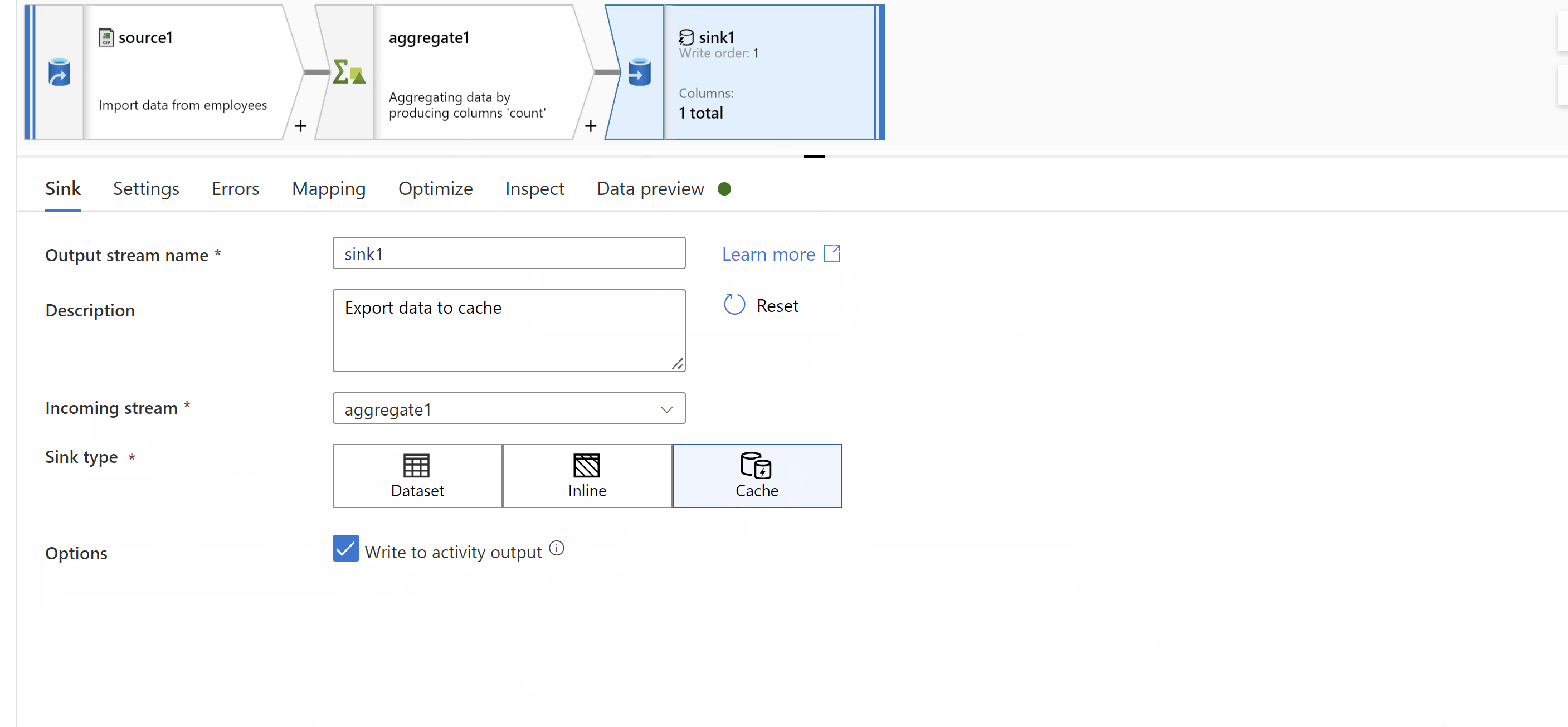
You can consider using dataflows and add your source file as source transformation and then you can get count of rows using aggregate transformation and then finally use cache sink and write output to activity. There by in pipeline you will get count and make a decision to perform copy or not.
Kindly check below gif where it shows how to output count to activity.
Kindly check below video too where its explained in detail about writing output from dataflows to activities.
Write Cache Sink to Activity Output in Azure Data factory
Hope this helps. Please let me know if any further queries.
----------------
 or upvote
or upvote  button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how 
Hello @Poel van der, RE (Ron)
If you have a list of events when you expect the record count to be higher then you can have a metadata or a date table where you can mark those events with a flag and then lookup those values
In a switch activity you can have cases like if activity count (considering you are using a copy activity which can give us the record count) is between so and so range and if it satisfies the flag value then execute that case, else go to next one
To fail the pipeline you can add a fail activity inside your case
Does this sound feasible to you?