Azure AI Document Intelligence
An Azure service that turns documents into usable data. Previously known as Azure Form Recognizer.
2,100 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EPP%3C/text%3E%3C/svg%3E)
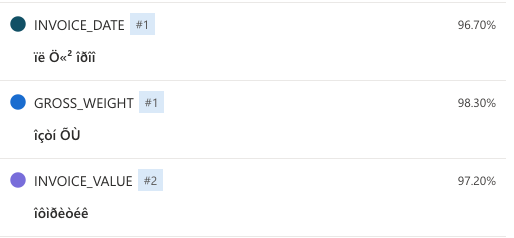
Hi, I have one PDF document, where my custom neural model returns the text in some weird encoded way. The entity bounding boxes seem correct, just the text content is bad in the JSON response and also visualized in Form Recognizer Studio. Sending the PDF document converted to a JPEG gives me the correct text entities!
Is there any requirement for the PDF document? Unfortunately I can't share the original document here, because it contains customer info.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EYM%3C/text%3E%3C/svg%3E)
Hello @PaulPawletta
I have seen some limitations of Custom Neural model as below, is your document English?
Could you please check on below document to see if you name your field properly to help it read?
Regards,
Yutong
@YutongTie-MSFT yes the document is in English.
In my case for this particular 1-page PDF document, all the text is in a wrong encoding. Sending the same page converted to a JPEG gives me the correct text. So it looks to me like there is a problem with the OCR on the document.