Azure Synapse Analytics
An Azure analytics service that brings together data integration, enterprise data warehousing, and big data analytics. Previously known as Azure SQL Data Warehouse.
5,377 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EPC%3C/text%3E%3C/svg%3E)
Hi, recently I have faced this issue while working with Synapse. Basically, I'm getting distinct values from a column from different FACT tables that I had. Then, I union them and apply another distinct just to have the unique values from all of the FACT tables. After that, I write them as a delta file in a specific path.
Now, sometimes this takes 6-8 minutes as expected since the volume of data. But sometimes, as you can see in the photo, there is some kind of problem with job assign process. After a job got executed, it takes a while for next one to start. You can notice that comparing the total run time vs total job execution time.
I'm using full pyspark code to achieve this, and applying this custom confs
spark.conf.set("spark.sql.sources.partitionOverwriteMode", "DYNAMIC")
spark.conf.set("spark.databricks.io.cache.enabled", True)
spark.conf.set("spark.databricks.adaptive.autoOptimizeShuffle.enabled", True)
spark.conf.set("spark.sql.adaptive.coalescePartitions.enabled", True)
spark.conf.set("spark.sql.adaptive.enabled", True)
spark.conf.set("spark.sql.adaptive.localShuffleReader.enabled", True)
spark.conf.set("spark.sql.adaptive.skewJoin.enabled", True)
spark.conf.set("spark.sql.hive.manageFilesourcePartitions", True)
spark.conf.set("spark.sql.hive.metastorePartitionPruning", True)
spark.conf.set("spark.sql.optimizer.dynamicPartitionPruning.enabled", True)
spark.conf.set("spark.sql.parquet.filterPushdown", True)
spark.conf.set("spark.sql.join.preferSortMergeJoin", True)
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", -1)
spark.conf.set("spark.sql.broadcastTimeout", "3600000ms")
spark.conf.set("spark.sql.debug.maxToStringFields", 1000)
spark.conf.set("spark.sql.shuffle.partitions", 10000)
spark.conf.set("spark.sql.hive.filesourcePartitionFileCacheSize", 786432000)
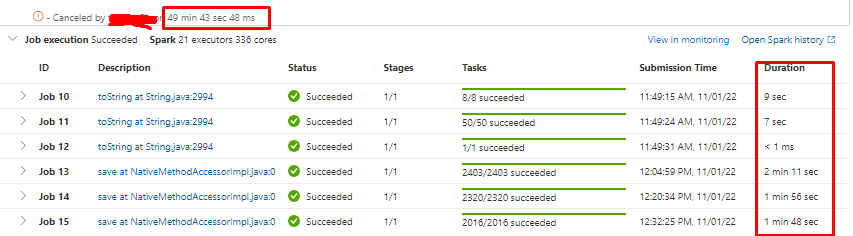
I already made a research about this issue, but didn't find anything helpful. So, if anyone can help me understand further what it's happening, it will great full!

The configuration spark.sql.optimizer.dynamicPartitionPruning.enabled enables dynamic partition pruning, which can significantly improve query performance. However, ensure that your tables are partitioned correctly and the partition columns are used in the query predicates for effective pruning.