Azure Data Factory
An Azure service for ingesting, preparing, and transforming data at scale.
10,196 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ERR%3C/text%3E%3C/svg%3E)
Hi Team,
I have a .csv file with two rows: a column header in the second row, and data in rows 1 and 2 for that column header as shown in the figure below. I want to map this column header to a SQL table. Is there a method to use data flow to consider the second row to be the column header?
Could you kindly help me out with this.
Thanks in advance!
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ESA%3C/text%3E%3C/svg%3E)
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ESM%3C/text%3E%3C/svg%3E)
Hi @Anonymous ,
Just checking in to see if the below answer helped. If this answers your query, do click Accept Answer and Up-Vote for the same. And, if you have any further query do let us know.
Hi @Anonymous ,
Thanks for posting question in Microsoft Q&A platform and for using Azure services.
In order to achieve result mentioned in the dataset, making second row as Header, we could use "Skip Line Count" setting of Source Dataset of the input csv.
One way to achieve result could like below as overall mapping:
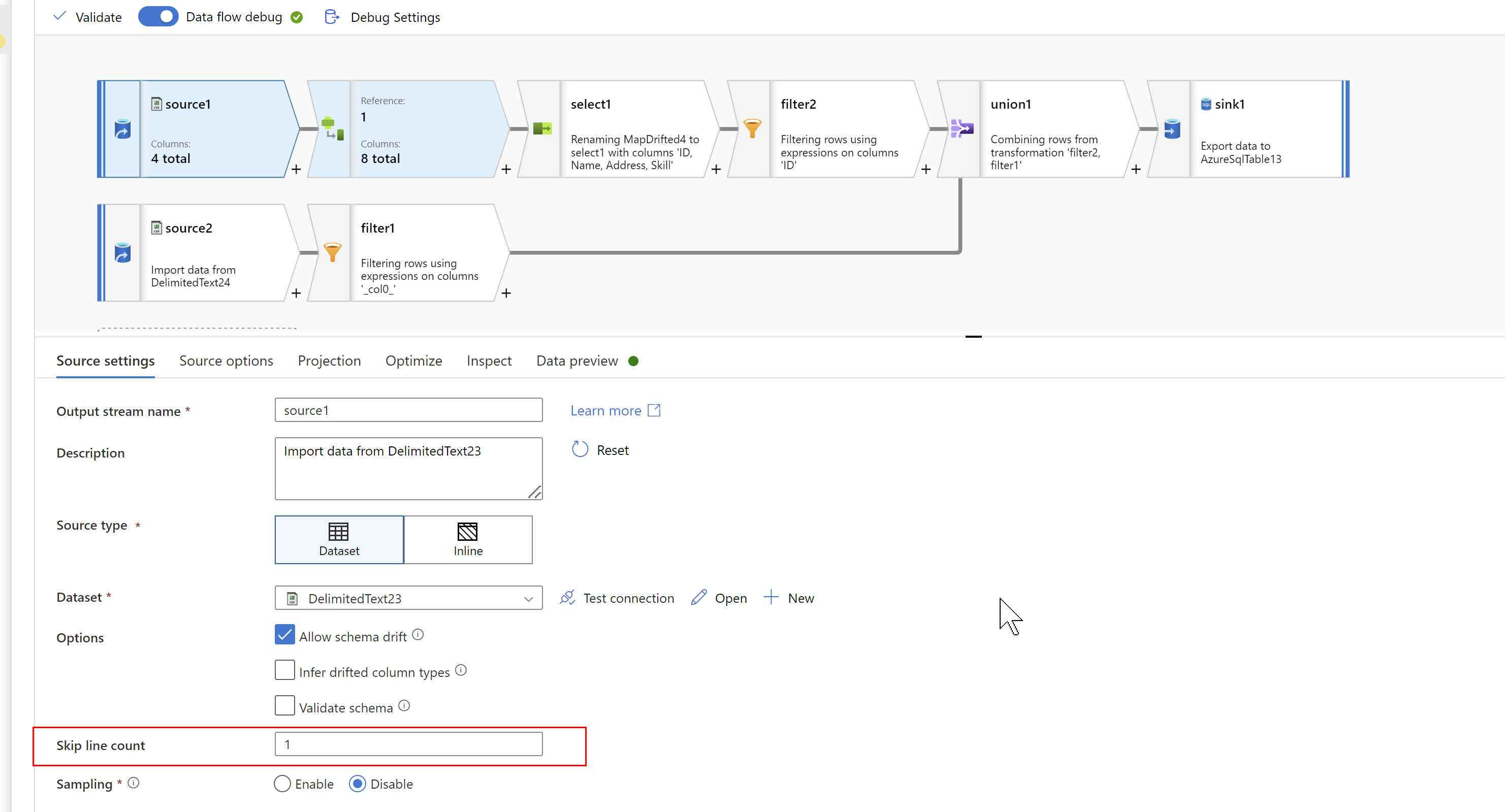
Take source dataset, skip line count=1, then Map Drifted columns in the next step, remove extra columns using Select transformation, result of Select should look like below:
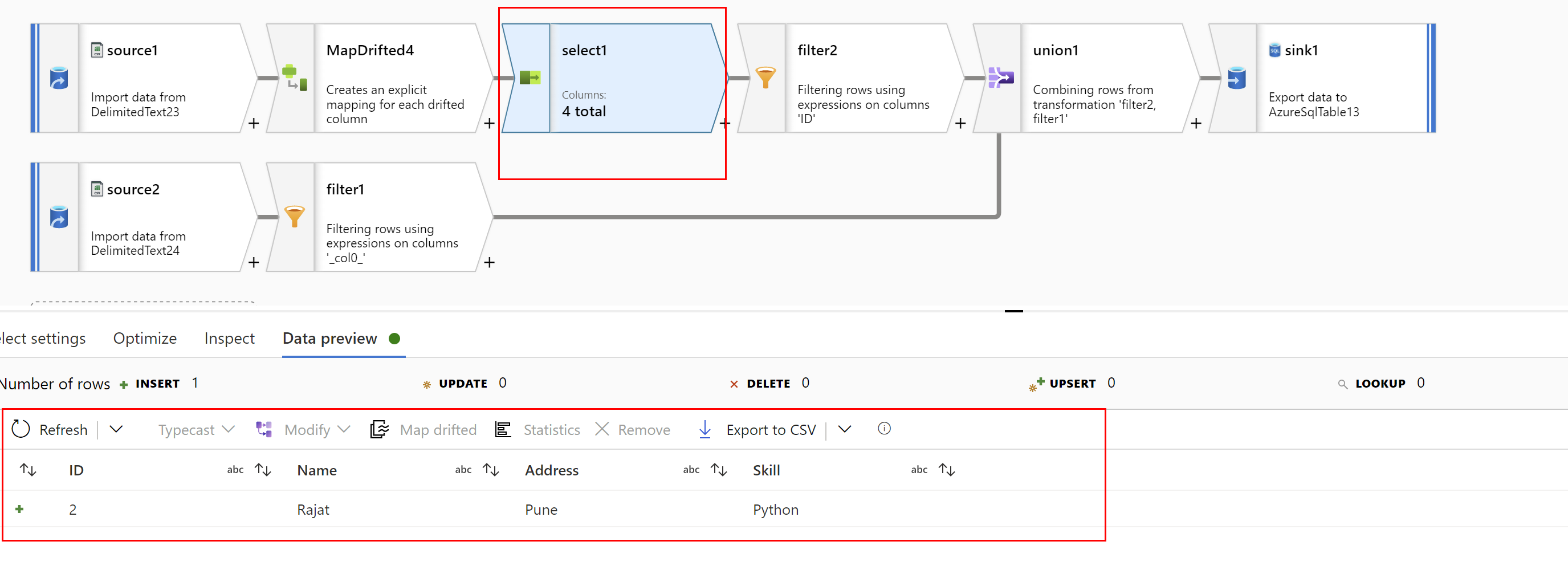
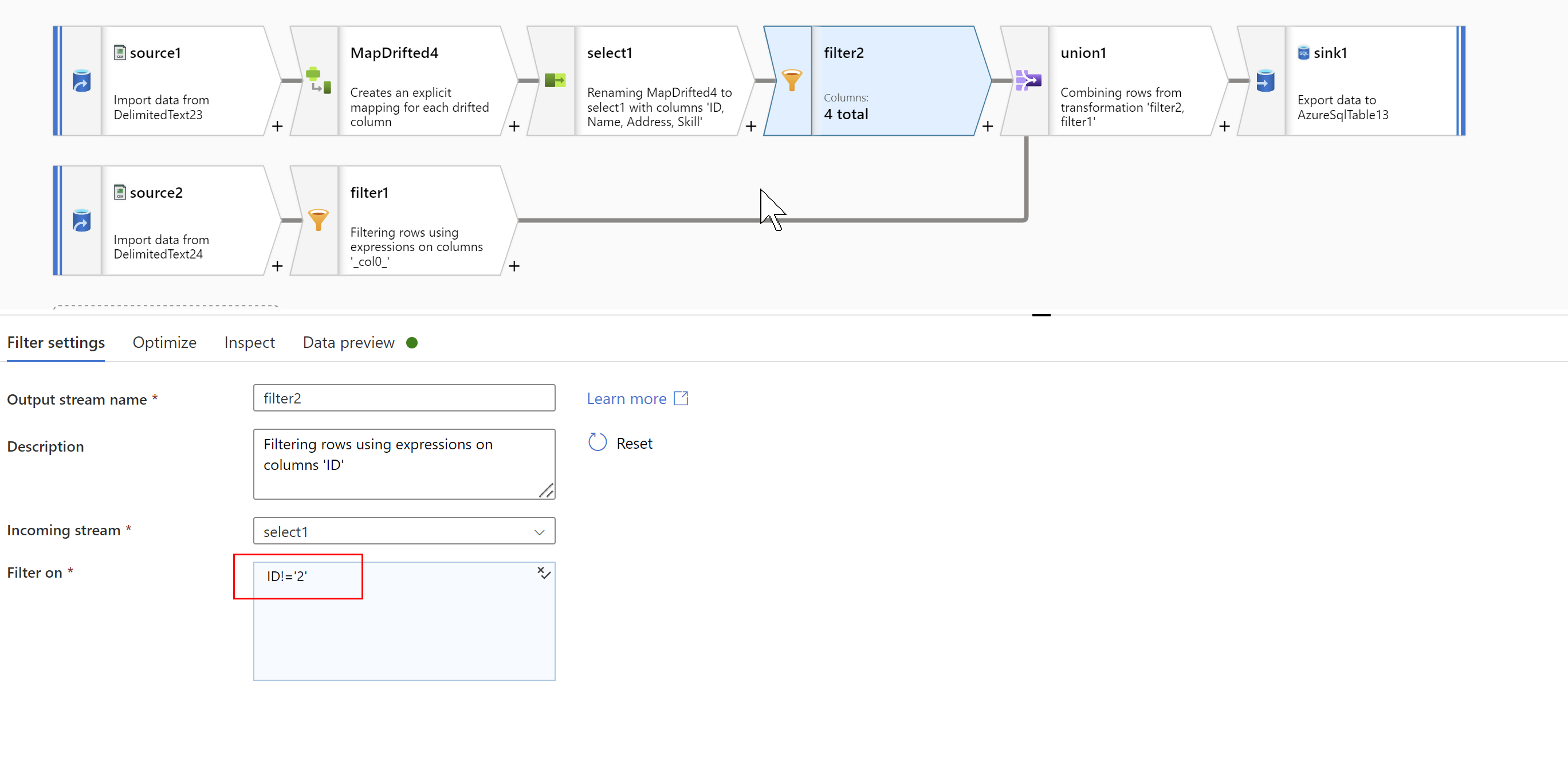
Filter out ID=2 that is ID!='2' which comes in the above flow so that only Header(second row) is left:
Take Source Dataset again with no Skip Line count and First Row as Header unchecked:
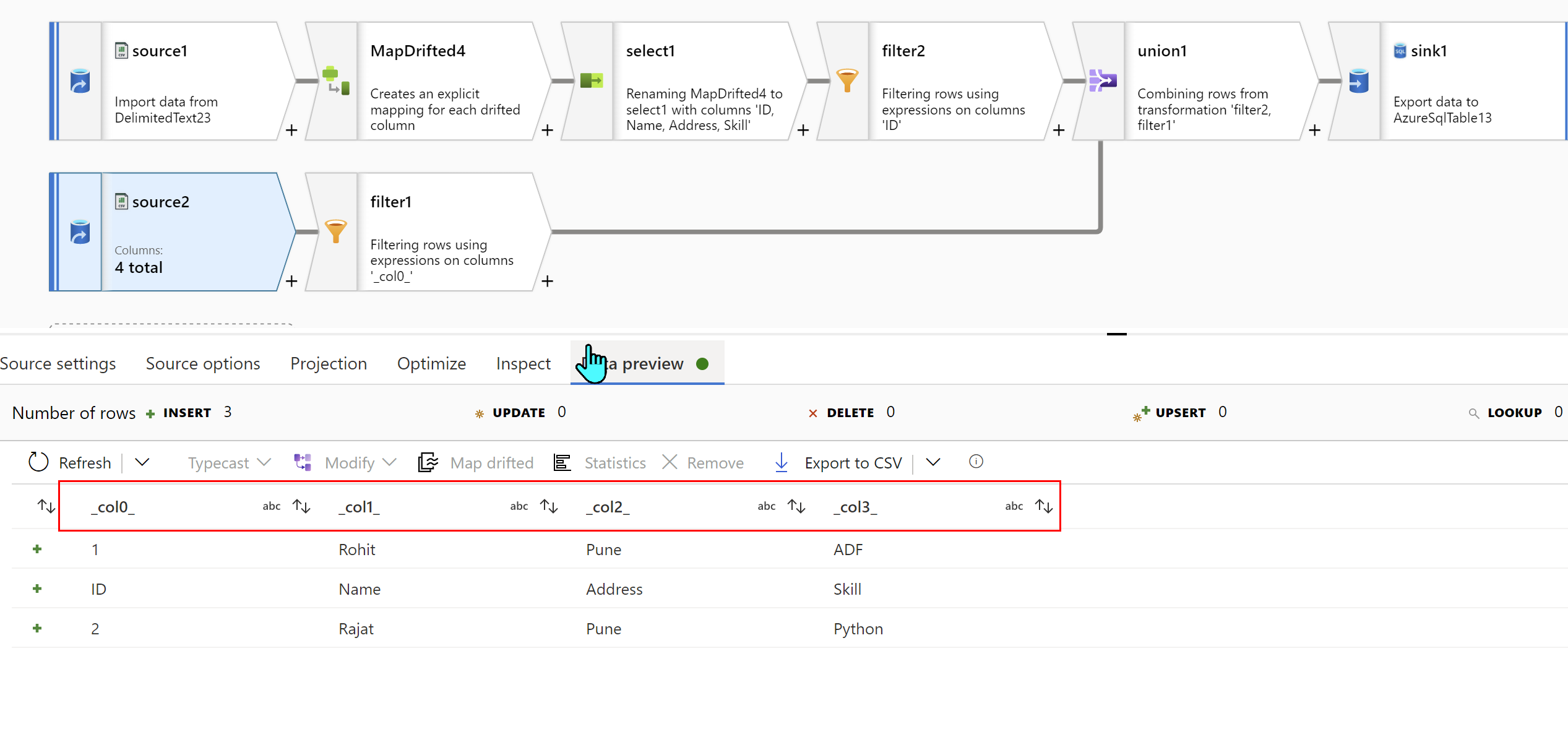
Next, Filter out ID so that Header column (second row of original data) is removed:
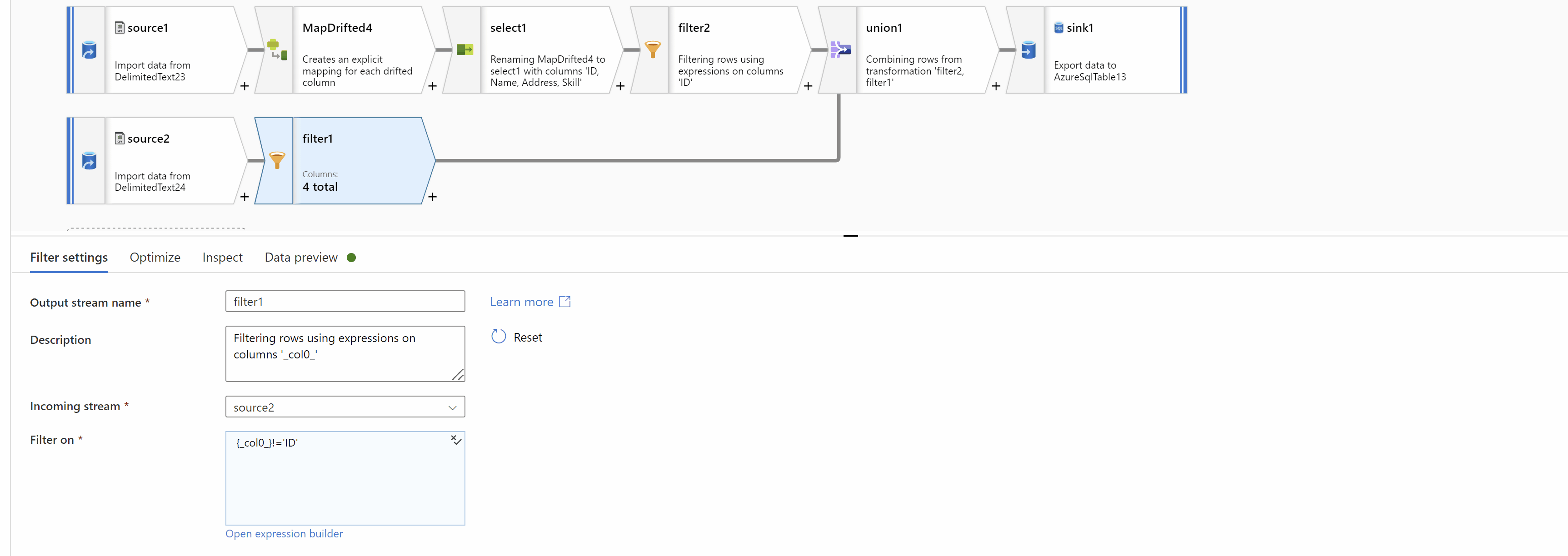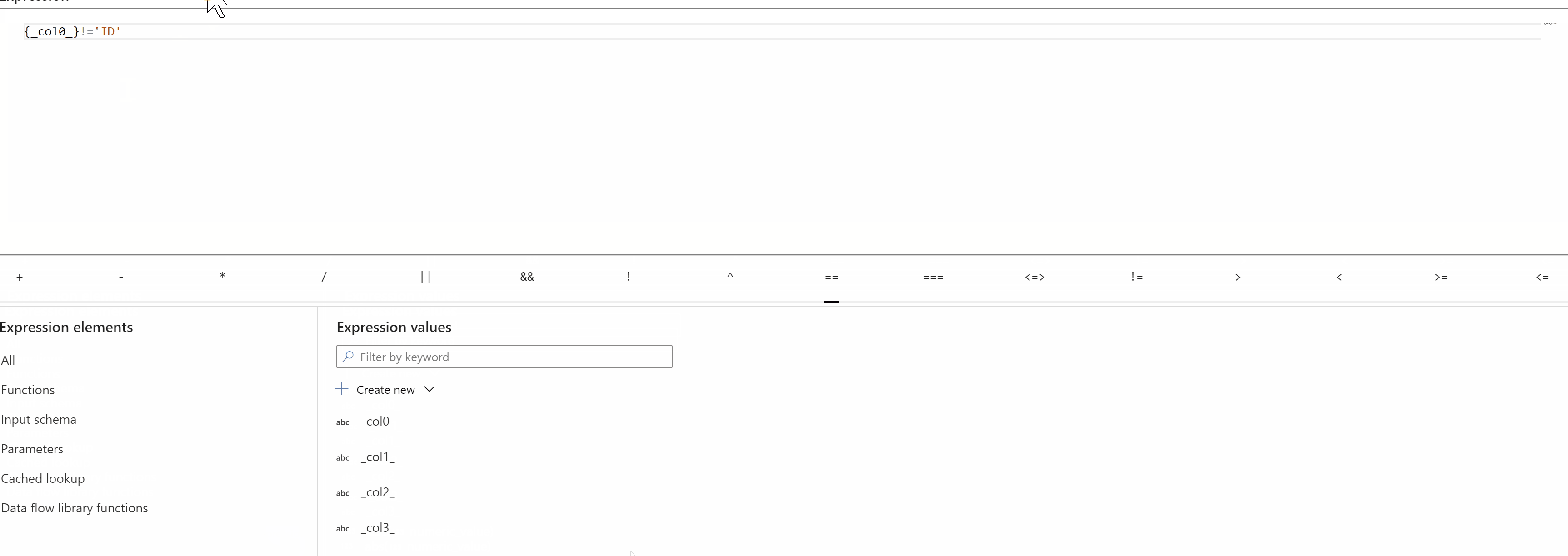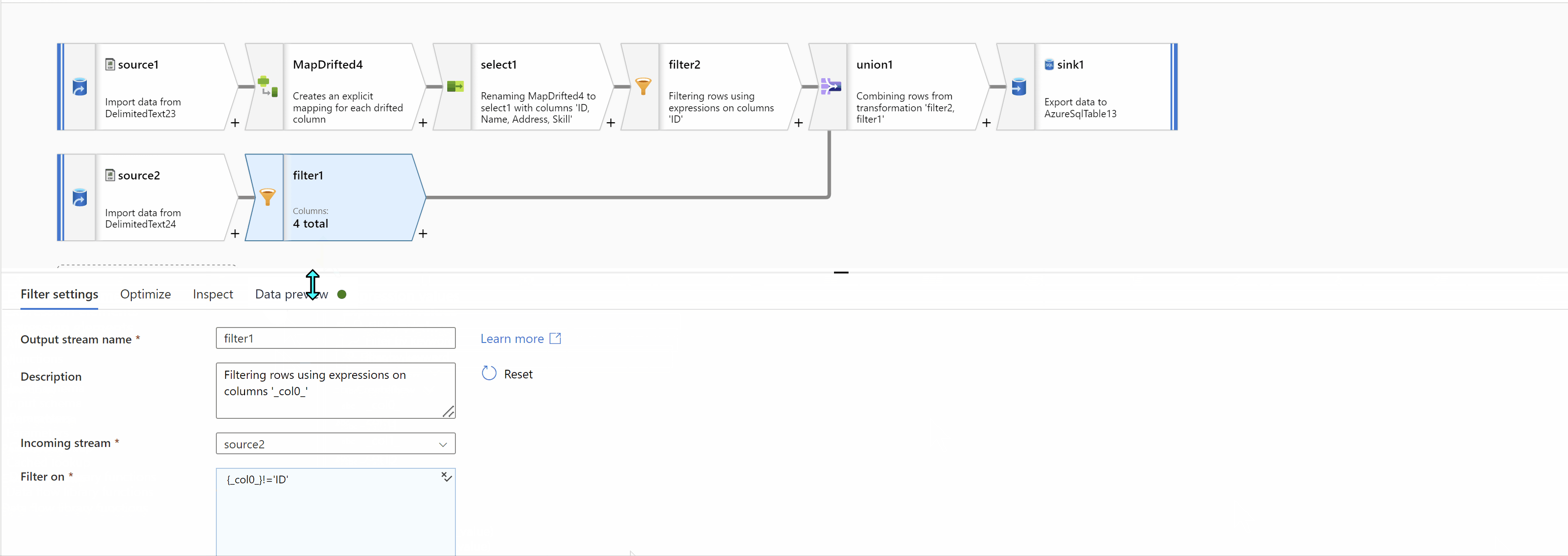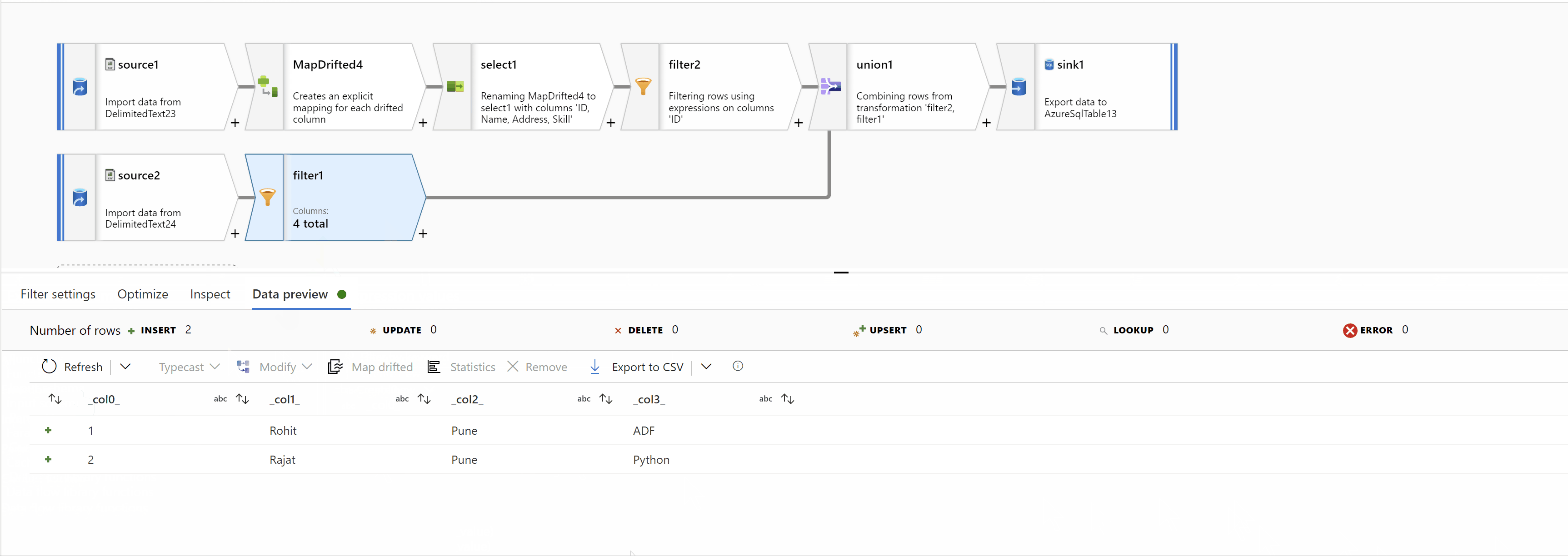
Finally, Union data from both streams using "Union by Position" to get the desired result:
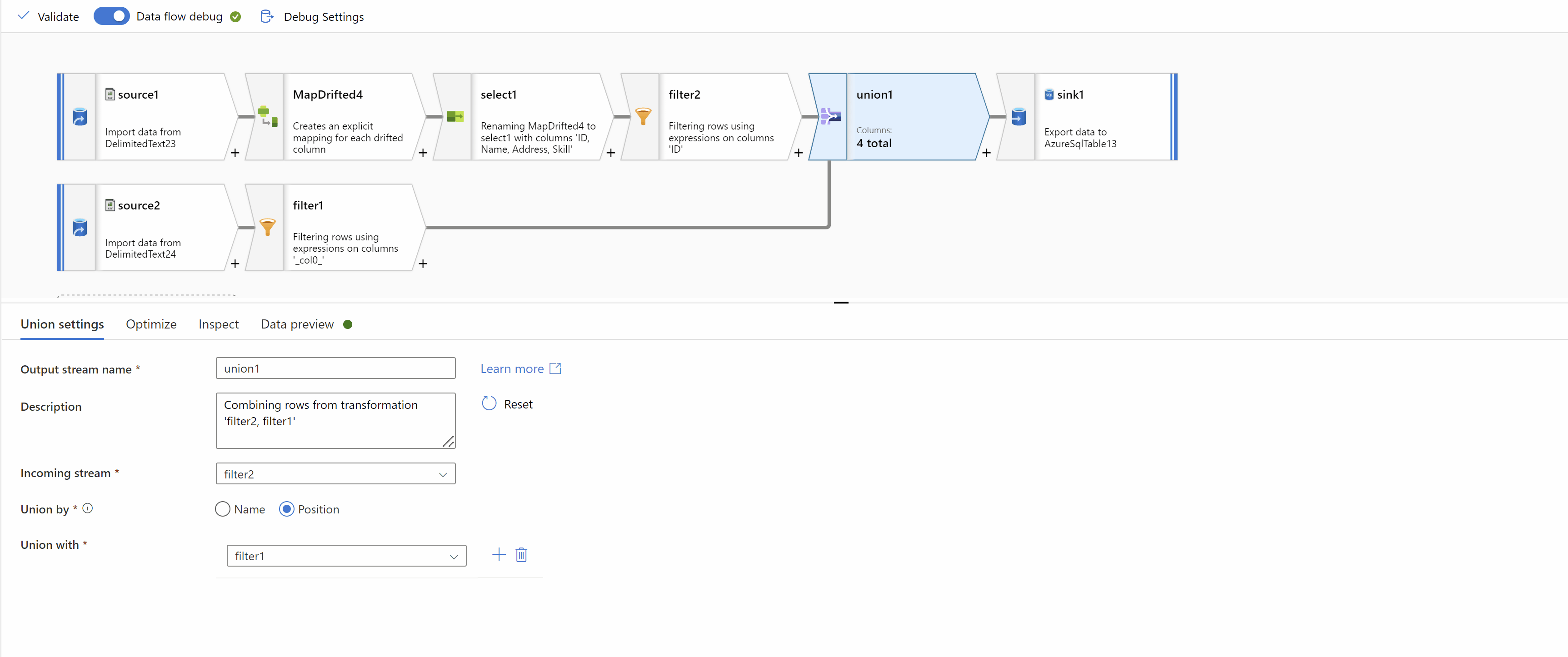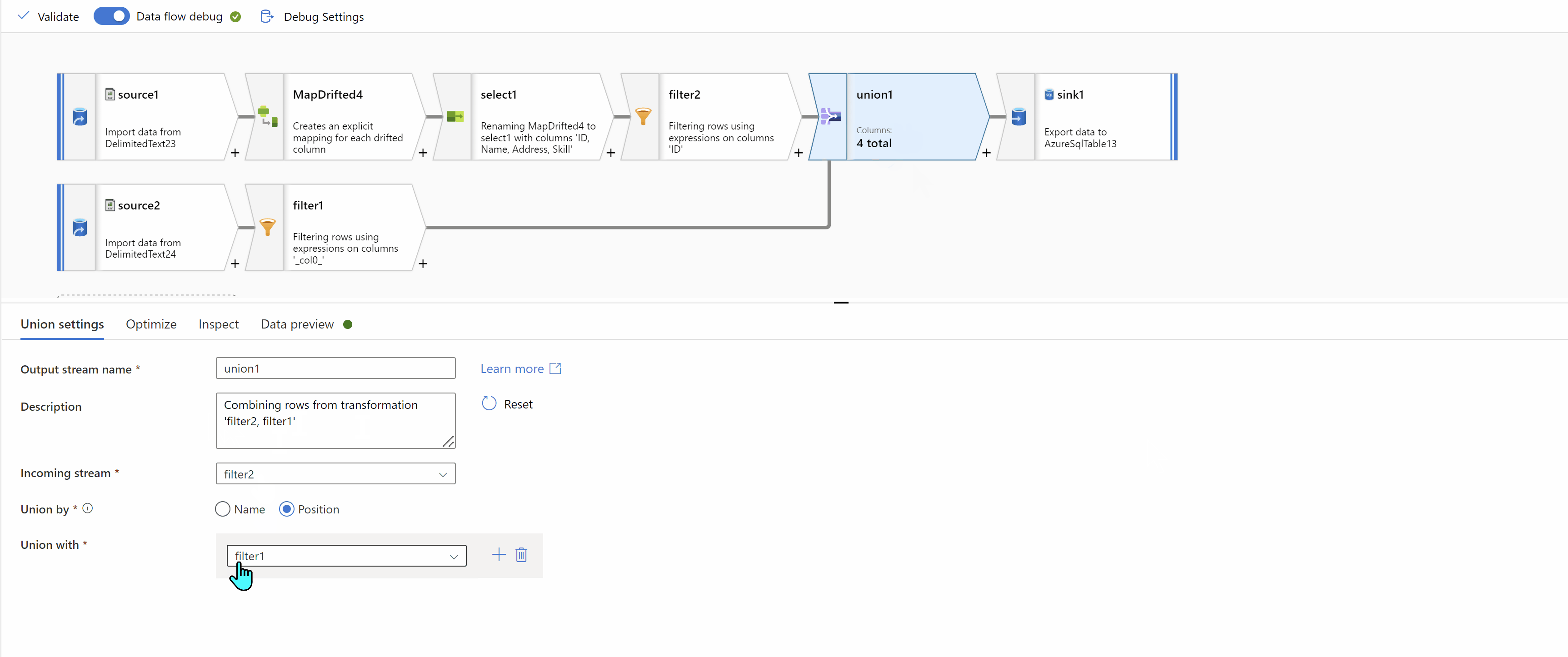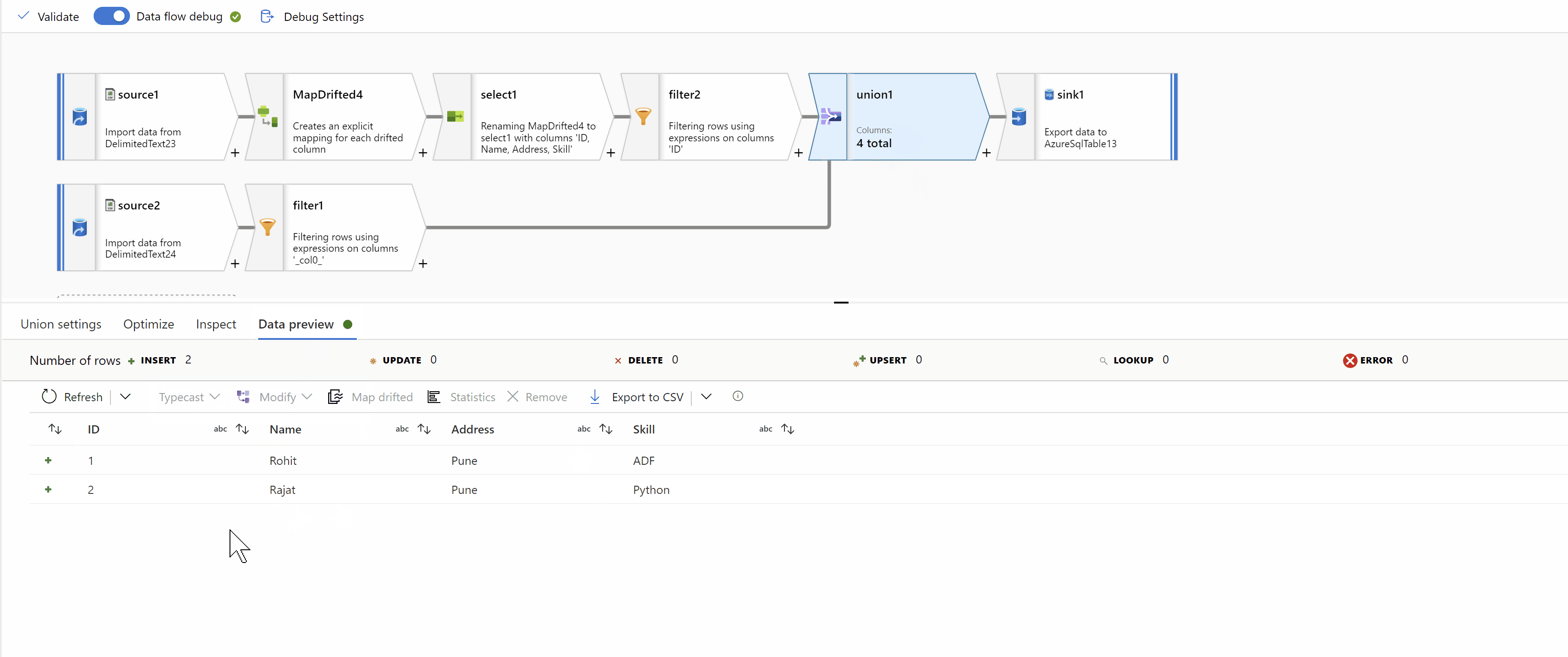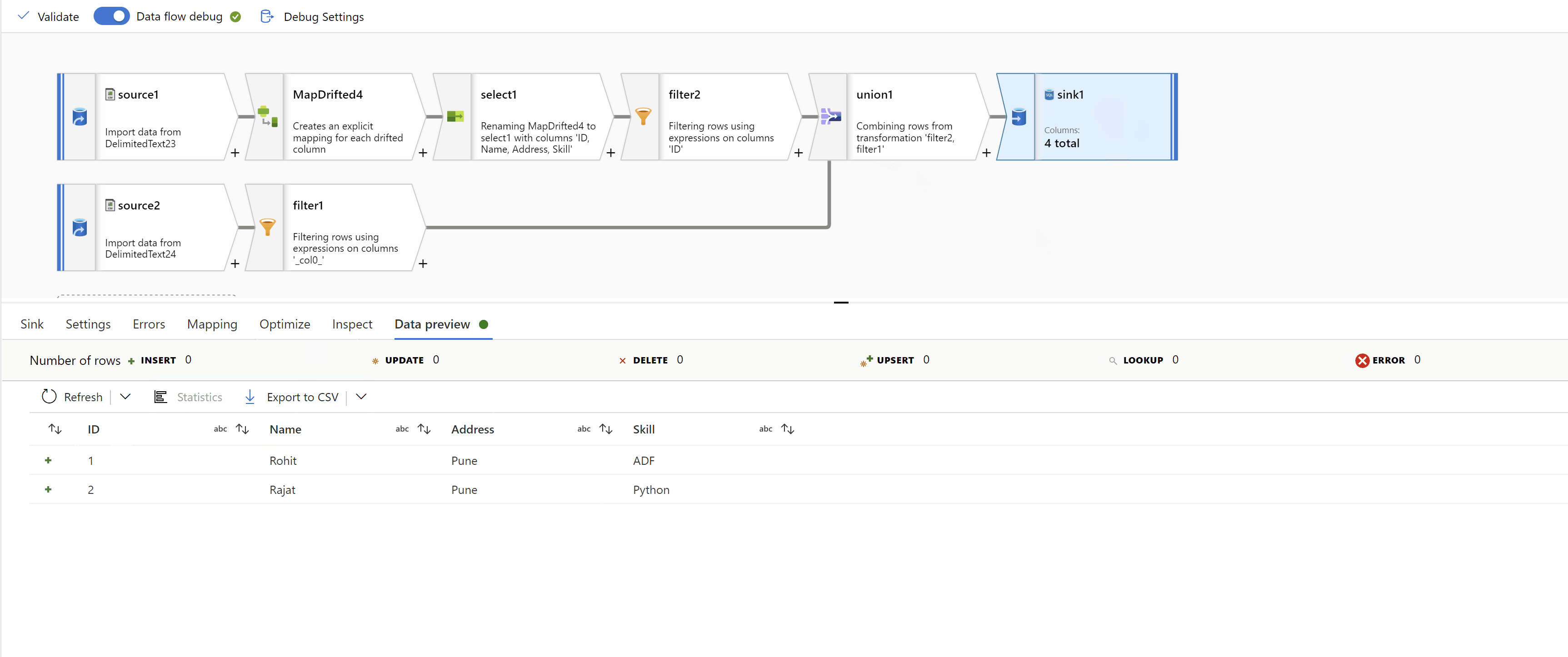
Hope this will help. Please let us know if any further queries.
------------------------------
 or upvote
or upvote  button whenever the information provided helps you.
button whenever the information provided helps you.
Thank you for your answer. I am grateful for your support and explanation in very simple words. I have accepted the answer. Thanks a lot.
Regards,
Rohit