' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ERP%3C/text%3E%3C/svg%3E)
4,707 questions


' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ENM%3C/text%3E%3C/svg%3E)

Hi,
Here is the solution for the new request:
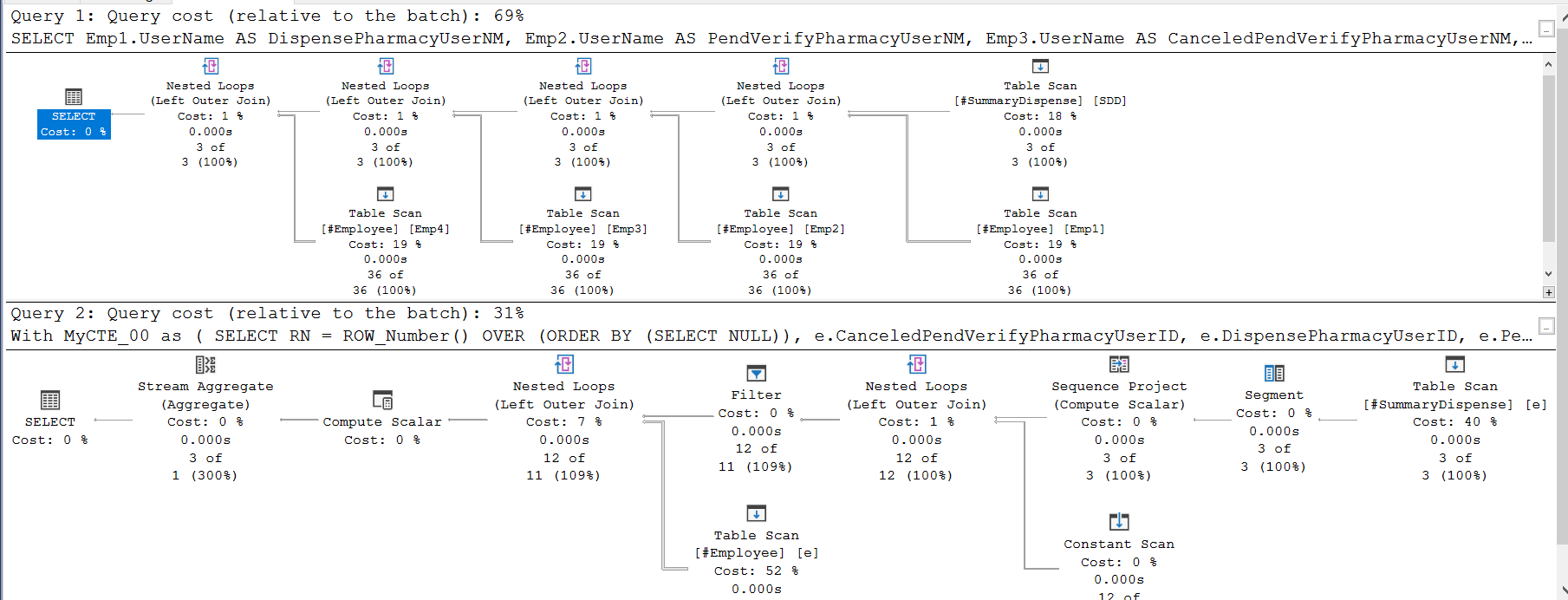
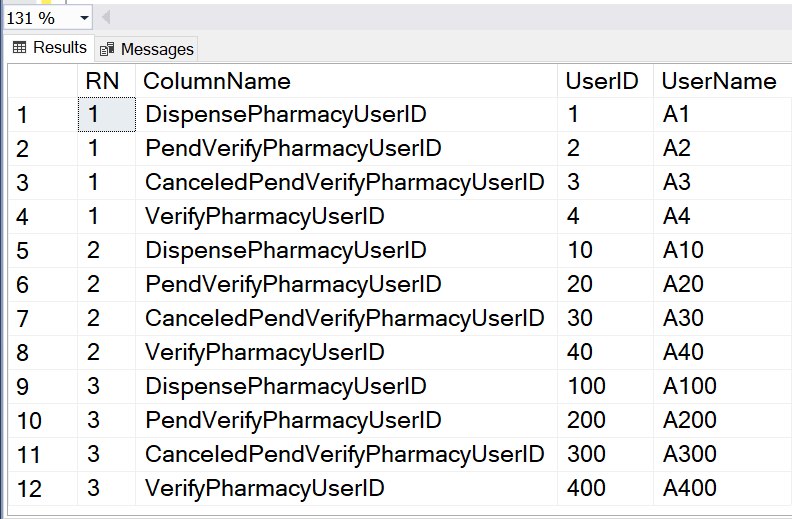
Note! This will work only if the values do not include dot . since I use dot as the separator between the ID and the name. If there can be a dot in the values then we simply need to use different separator in the query but the solution is the same.
;With MyCTE_00 as (
SELECT
RN = ROW_Number() OVER (ORDER BY (SELECT NULL)),
e.CanceledPendVerifyPharmacyUserID,
e.DispensePharmacyUserID,
e.PendVerifyPharmacyUserID,
e.VerifyPharmacyUserID
FROM #SummaryDispense e
)
,MyCTE_01 as (
select p.RN, p.ColumnName, p.UserID, e.UserName
from MyCTE_00
unpivot(UserID for ColumnName in (
[DispensePharmacyUserID],[PendVerifyPharmacyUserID], [CanceledPendVerifyPharmacyUserID],[VerifyPharmacyUserID]
)) as P
LEFT JOIN #Employee e ON p.UserID = e.UserID
)
, MyCTE02 as (
SELECT [DispensePharmacyUserID],[PendVerifyPharmacyUserID], [CanceledPendVerifyPharmacyUserID],[VerifyPharmacyUserID]
FROM
(
SELECT RN, ColumnName, UserName = UserName + '.' + CONVERT(VARCHAR(10), UserID)
FROM MyCTE_01
) AS TableToPivot
PIVOT
(
MIN(UserName)
FOR ColumnName IN ([DispensePharmacyUserID],[PendVerifyPharmacyUserID], [CanceledPendVerifyPharmacyUserID],[VerifyPharmacyUserID])
) AS PivotTable
)
SELECT
PARSENAME([DispensePharmacyUserID] ,1) as [DispensePharmacyUserID] , PARSENAME([DispensePharmacyUserID] ,2) as [DispensePharmacyUserName] ,
PARSENAME([PendVerifyPharmacyUserID] ,1) as [PendVerifyPharmacyUserID] , PARSENAME([PendVerifyPharmacyUserID] ,2) as [PendVerifyPharmacyUserName] ,
PARSENAME([CanceledPendVerifyPharmacyUserID] ,1) as [CanceledPendVerifyPharmacyUserID], PARSENAME([CanceledPendVerifyPharmacyUserID] ,2) as [CanceledPendVerifyPharmacyUserName],
PARSENAME([VerifyPharmacyUserID] ,1) as [VerifyPharmacyUserID] , PARSENAME([VerifyPharmacyUserID] ,2) as [VerifyPharmacyUserName]
FROM MyCTE02
GO