Azure Machine Learning
An Azure machine learning service for building and deploying models.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.

We have a computer vision pipeline that finetunes a vision model.
The data for training the vision model is a large collection of images that lands in our data lake.
The problem is that we are not able to mount this dataset to our training job.
In Azure ML portal we defined a named dataset for the image folder in our data lake (not the default workspace data source).
But if in our job control script we will try to reference the dataset by name and mount it to the training job:
docker_config = DockerConfiguration(use_docker=True)
# Access the dataset
dataset = Dataset.get_by_name(ws, 'the name of our named dataset')
# Run the experiment
args = ['--data-folder', dataset.as_mount() ]
print("Mounted dataset")
src = ScriptRunConfig(source_directory='./src',
script='balearms_cnn_training.py',
arguments=args,
compute_target=compute_target,
environment=keras_env,
docker_runtime_config=docker_config)
The job will fail with the error:
{"NonCompliant":"UserErrorException:\n\tMessage: Cannot mount Dataset(id='389fb088-59eb-4288-8225-aa9fb55f14c0', name='balearms', version=1). Error Message: DataAccessError(PermissionDenied(Some(This request is not authorized to perform this operation using this permission.)))\n\tInnerException None\n\tErrorResponse \n{\n \"error\": {\n \"code\": \"UserError\",\n \"message\": \"Cannot mount Dataset(id='389fb088-59eb-4288-8225-aa9fb55f14c0', name='balearms', version=1). Error Message: DataAccessError(PermissionDenied(Some(This request is not authorized to perform this operation using this permission.)))\"\n }\n}"}
…
To overcome this problem we use the default workspace dataset.
datastore = ws.get_default_datastore()
dataset = Dataset.File.from_files(path=(datastore, 'datasets/balearms/ExtractedImages/'))
# Run the experiment
args = ['--data-folder', dataset.as_mount() ]
print("Mounted dataset")
src = ScriptRunConfig(source_directory='./src',
script='balearms_cnn_training.py',
arguments=args,
compute_target=compute_target,
environment=keras_env,
docker_runtime_config=docker_config)
It works but it also means that we have to copy the files to a different storage account (the default workspace dataset) and that creates complexities.
There is no doubt that we should be able to mount a named dataset. I believe that we miss just a small detail…
Would you be able to help us to figure out how to use named datasets and mount them to our training jobs?
Thanks
Manu

Have you tried to mount the dataset to a temp path on your compute as recommended here?
args = ['--data-folder', dataset.as_mount('/tmp/dataset') ]
Also, while registering data lake storage there is an option to grant_workspace_access to true through SDK to enable reader access to workspace managed identity if you are using a secured workspace. Did you enable this access if applicable for your workspace?
I did use your suggestion and I still get the Error Message: DataAccessError(PermissionDenied(Some(This request is not authorized to perform this operation using this permission.
The workspace is defined with:
"Allowed workspace managed identity access: Yes"

It's possible you defined the datalake as a datastore with identity-based access and also defined your compute instance/cluster with managed identity enabled. In this case, you'll need to grant the Compute Cluster Managed Identity access to the Data Lake through RBAC. Check this link for more details: https://learn.microsoft.com/en-us/azure/machine-learning/how-to-identity-based-service-authentication
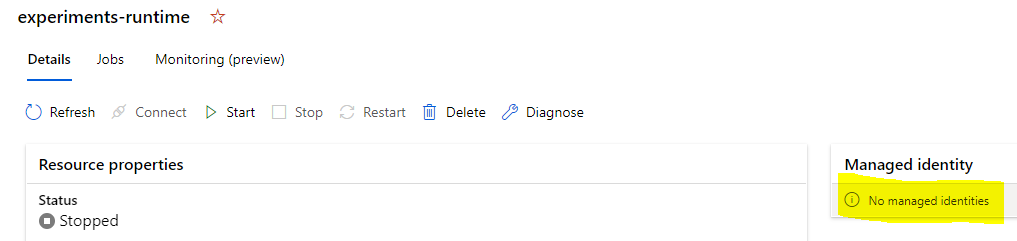
There is no managed identity associated with the compute.
@Manu Cohen-Yashar This section on accessing storage services recommends using the role Storage Blob Data Reader for identity-based access to Azure Data Lake Storage Gen2.
Could you try adding a user based managed identity in your subscription and assigning the role Storage Blob Data Reader from your storage account IAM section to the MI?
From storage account IAM blade.
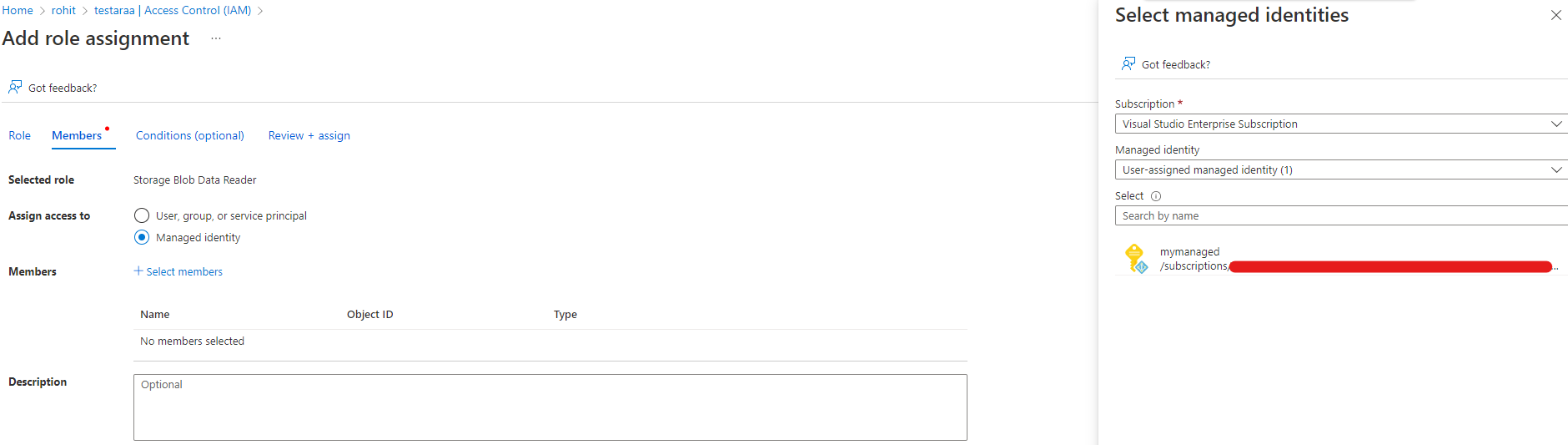
Then, assign the same on your compute instance and restart the instance.
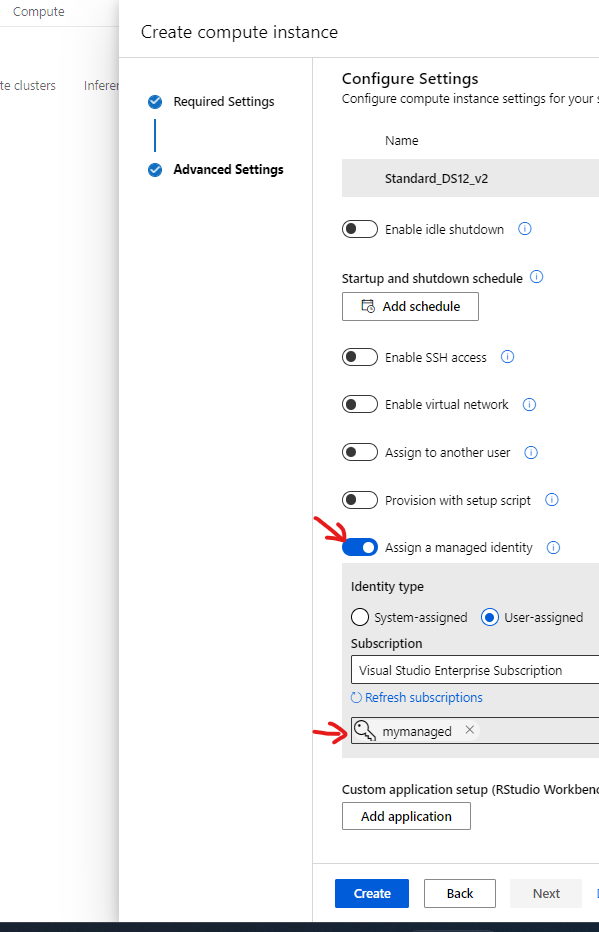
Check if this provides the required permission to read the data from your data lake account.
Unfortunately, this did not work.
The dataset that I needed to mount is a folder in my data lake (gen2).
As you would imagine the Azure ML data store I use is of type the data lake, and it is configured with a service principal that has all the permissions to access the data lake, but still, I cannot access the data.
BUT. It is possible to create a blob data store (that uses the access key) to reference the same data.
Yes, it's not RBAC but when creating a data set from that blob-based data store, I am able to access the dataset, mount it, etc.
Something is broken in my data lake gen2 data store. I do not know what it is, but the blob data store is a reasonable workaround.
The dataset that I needed to mount is a folder in my data lake (gen2).
As you would imagine the Azure ML data store I use is of type the data lake, and it is configured with a service principal that has all the permissions to access the data lake, but still, I cannot access the data.
BUT. It is possible to create a blob data store (that uses the access key) to reference the same data.
Yes, it's not RBAC but when creating a data set from that blob-based data store, I am able to access the dataset, mount it, etc.
Something is broken in my data lake gen2 data store. I do not know what it is, but the blob data store is a reasonable workaround.
I just heard from the Azure ML product team that they know that ADLS Gen-2 data sources cannot be mounted. They are working to fix it, but meanwhile, we have to use the Azure Storage data source.