Azure Synapse Analytics
An Azure analytics service that brings together data integration, enterprise data warehousing, and big data analytics. Previously known as Azure SQL Data Warehouse.
5,006 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EJA%3C/text%3E%3C/svg%3E)
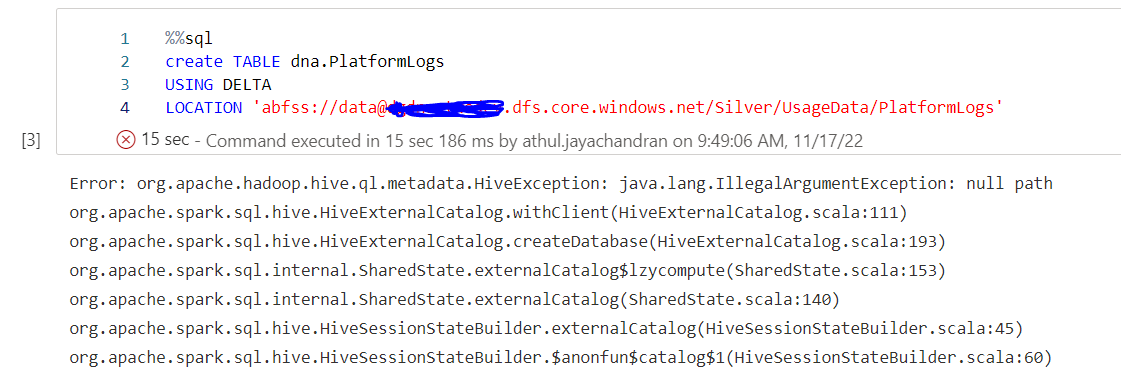
I am trying to create a new delta lake table from a path i have in my datalake container with data in delta format
Syntax i am trying inside notebook
create TABLE lakedatabasename.tablename
USING DELTA
LOCATION 'abfss://container@datalake.dfs.core.windows.net/Path'
Error is as below,
Error: org.apache.hadoop.hive.ql.metadata.HiveException: java.lang.IllegalArgumentException: null path
org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:111)
org.apache.spark.sql.hive.HiveExternalCatalog.createDatabase(HiveExternalCatalog.scala:193)
org.apache.spark.sql.internal.SharedState.externalCatalog$lzycompute(SharedState.scala:153)
org.apache.spark.sql.internal.SharedState.externalCatalog(SharedState.scala:140)
org.apache.spark.sql.hive.HiveSessionStateBuilder.externalCatalog(HiveSessionStateBuilder.scala:45)
org.apache.spark.sql.hive.HiveSessionStateBuilder.$anonfun$catalog$1(HiveSessionStateBuilder.scala:60)
org.apache.spark.sql.catalyst.catalog.SessionCatalog.externalCatalog$lzycompute(SessionCatalog.scala:133)
org.apache.spark.sql.catalyst.catalog.SessionCatalog.externalCatalog(SessionCatalog.scala:133)
org.apache.spark.sql.catalyst.catalog.SessionCatalog.databaseExists(SessionCatalog.scala:316)
org.apache.spark.sql.catalyst.catalog.SessionCatalog.requireDbExists(SessionCatalog.scala:232)
org.apache.spark.sql.catalyst.catalog.SessionCatalog.getTableRawMetadata(SessionCatalog.scala:572)
org.apache.spark.sql.catalyst.catalog.SessionCatalog.getTableMetadata(SessionCatalog.scala:559)
org.apache.spark.sql.execution.datasources.v2.V2SessionCatalog.loadTable(V2SessionCatalog.scala:65)
org.apache.spark.sql.connector.catalog.TableCatalog.tableExists(TableCatalog.java:119)
org.apache.spark.sql.execution.datasources.v2.V2SessionCatalog.tableExists(V2SessionCatalog.scala:40)
org.apache.spark.sql.connector.catalog.DelegatingCatalogExtension.tableExists(DelegatingCatalogExtension.java:78)
org.apache.spark.sql.delta.catalog.DeltaCatalog.org$apache$spark$sql$delta$catalog$SupportsPathIdentifier$$super$tableExists(DeltaCatalog.scala:61)
org.apache.spark.sql.delta.catalog.SupportsPathIdentifier.tableExists(DeltaCatalog.scala:655)
org.apache.spark.sql.delta.catalog.SupportsPathIdentifier.tableExists$(DeltaCatalog.scala:647)
org.apache.spark.sql.delta.catalog.DeltaCatalog.tableExists(DeltaCatalog.scala:61)
org.apache.spark.sql.execution.datasources.v2.CreateTableExec.run(CreateTableExec.scala:42)
org.apache.spark.sql.execution.datasources.v2.V2CommandExec.result$lzycompute(V2CommandExec.scala:43)
org.apache.spark.sql.execution.datasources.v2.V2CommandExec.result(V2CommandExec.scala:43)
org.apache.spark.sql.execution.datasources.v2.V2CommandExec.executeCollect(V2CommandExec.scala:49)
org.apache.spark.sql.execution.QueryExecution$$anonfun$eagerlyExecuteCommands$1.$anonfun$applyOrElse$1(QueryExecution.scala:107)
org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$5(SQLExecution.scala:104)
org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:169)
org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$1(SQLExecution.scala:91)
org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:775)
org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:65)
org.apache.spark.sql.execution.QueryExecution$$anonfun$eagerlyExecuteCommands$1.applyOrElse(QueryExecution.scala:107)
org.apache.spark.sql.execution.QueryExecution$$anonfun$eagerlyExecuteCommands$1.applyOrElse(QueryExecution.scala:103)
org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$transformDownWithPruning$1(TreeNode.scala:481)
org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:82)
org.apache.spark.sql.catalyst.trees.TreeNode.transformDownWithPruning(TreeNode.scala:481)
org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.org$apache$spark$sql$catalyst$plans$logical$AnalysisHelper$$super$transformDownWithPruning(LogicalPlan.scala:30)
org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning(AnalysisHelper.scala:267)
org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning$(AnalysisHelper.scala:263)
org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:30)
org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:30)
org.apache.spark.sql.catalyst.trees.TreeNode.transformDown(TreeNode.scala:457)
org.apache.spark.sql.execution.QueryExecution.eagerlyExecuteCommands(QueryExecution.scala:103)
org.apache.spark.sql.execution.QueryExecution.commandExecuted$lzycompute(QueryExecution.scala:87)
org.apache.spark.sql.execution.QueryExecution.commandExecuted(QueryExecution.scala:81)
org.apache.spark.sql.Dataset.<init>(Dataset.scala:230)
org.apache.spark.sql.Dataset$.$anonfun$ofRows$2(Dataset.scala:100)
org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:775)
org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:97)
org.apache.spark.sql.SparkSession.$anonfun$sql$1(SparkSession.scala:618)
org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:775)
org.apache.spark.sql.SparkSession.sql(SparkSession.scala:613)
org.apache.livy.repl.SQLInterpreter.execute(SQLInterpreter.scala:129)
org.apache.livy.repl.Session.$anonfun$executeCode$1(Session.scala:533)
scala.Option.map(Option.scala:230)
org.apache.livy.repl.Session.executeCode(Session.scala:529)
org.apache.livy.repl.Session.$anonfun$execute$4(Session.scala:338)
org.apache.livy.repl.Session.withRealtimeOutputSupport(Session.scala:741)
org.apache.livy.repl.Session.$anonfun$execute$1(Session.scala:338)
scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
scala.concurrent.Future$.$anonfun$apply$1(Future.scala:659)
scala.util.Success.$anonfun$map$1(Try.scala:255)
scala.util.Success.map(Try.scala:213)
scala.concurrent.Future.$anonfun$map$1(Future.scala:292)
My Synapse Analytics workspace has Blob Storage Contributor Access to datalake. Has anyone faced something similar.

Hello @Jayachandran, Athul ,
Thanks for the question and using MS Q&A platform.
As per the error message - org.apache.hadoop.hive.ql.metadata.HiveException: java.lang.IllegalArgumentException: null path looks the path is null.
Could you please confirm if the path exists by List the content of a directory using this command: mssparkutils.fs.ls('Your directory path')?
Kindly share the screenshot of the query which you are trying along with the complete stack trace of the error message.
Hi Pradeep,
We tried the same, seems we are able to see the directory using the list files command.

Hi Team,
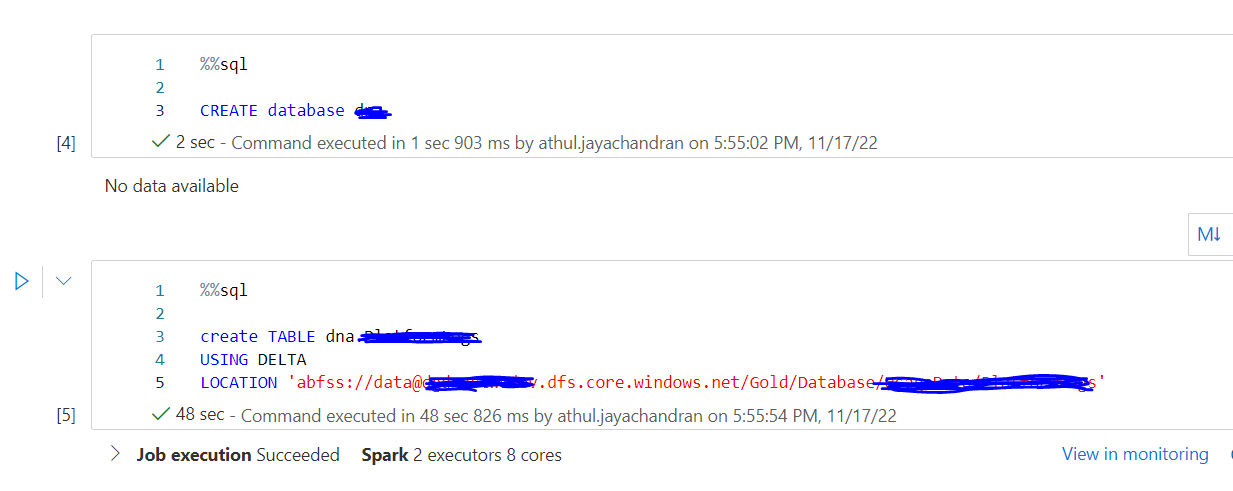
We were able to figure out the problem, the problem was that the default container name specified during the creation of synapse workspace was no longer available under the storage account.
we had the same name for storageaccountname and storagefilesystem name at the time of creation. PFB
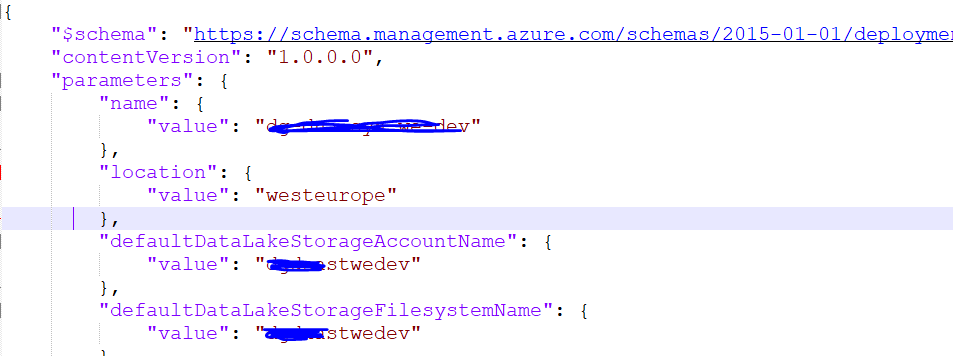
Once we created the default container name again in the datalake, we were able to run and create delta lake table successfully.
Quick question on the same, is it possible to change the default container name under a storage account post creation of Synapse workspace. Would love to have this as a feature.
Hello @Jayachandran, Athul ,
Glad to hear that your issue is resolved. Appreciate for sharing the resolution, this would certainly benefit other community members.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ERV%3C/text%3E%3C/svg%3E)
Hi,
I've found a similar Error: Error: org.apache.hadoop.hive.ql.metadata.HiveException: java.lang.IllegalArgumentException: null path
The strange thing is that my code just worked before.. Nothing changed. I create Several views from Dataframes, the dataframes seem to have data.
But as soon as I run a SQL query on a view, I get the above error.
The only thing I can think of, is that I am currently working from another location... IP should be whitelisted somewhere? (I am able to access the container, and run my sql & spark pool... )
The Directory Output
@Robbe VL - Since this thread is too old, I would recommend creating a new thread on the same forum with as much details about your issue as possible. That would make sure that your issue has better visibility in the community.