Azure Synapse Analytics
An Azure analytics service that brings together data integration, enterprise data warehousing, and big data analytics. Previously known as Azure SQL Data Warehouse.
4,396 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EA%3C/text%3E%3C/svg%3E)
We have a few Excel files that need to be imported into Synapse Analytics dedicated pool. For this requirement we build a few data flows, one for each Excel file to be imported. We were recently asked to add another one so I duplicated one of the existing flows and modified it for the new file. When I preview the results from the Data Flow configuration everything looks fine, but when I run it in a debug session from the main pipeline the data flow remains stuck in queued status:
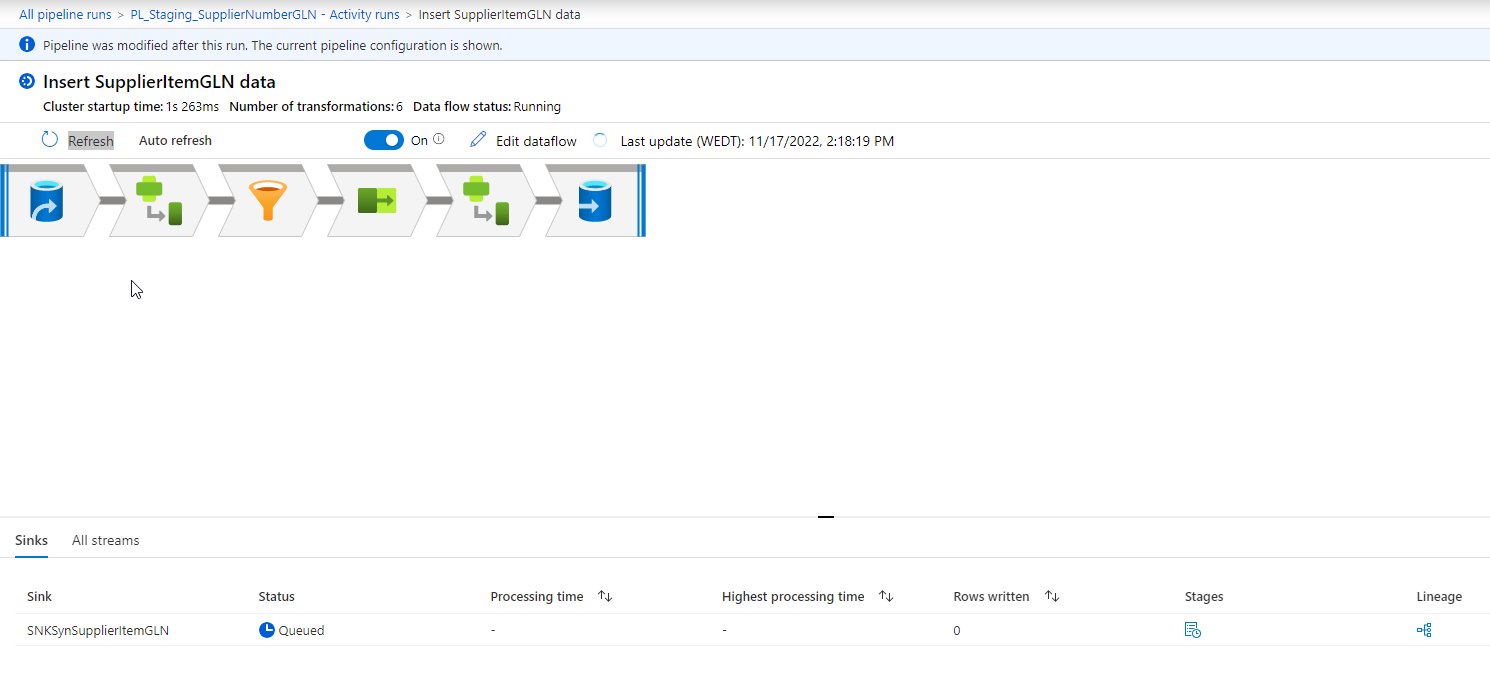
Existing flows for other files using the same integration runtime still work just fine.
I have tried using another integration runtime (we have to use AutoResolve as we don't have self hosted runtimes we can use for this purpose) and tried using a medium instead of a small compute cluster, but neither change makes any difference. The Excel file contains about 110.000 rows and is only 5 columns wide, so we're not talking a lot of data here. I'm stumped as to what might be going on. Hoping someone here can give me some pointers as to where to search for the problem.
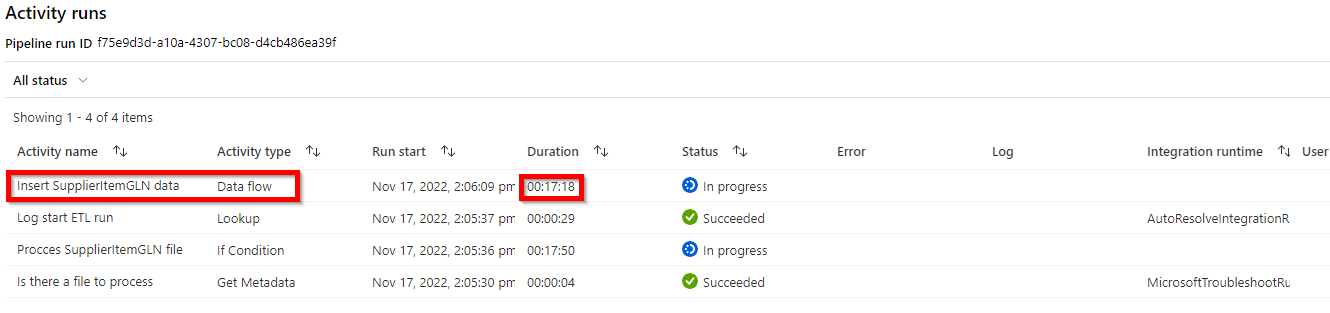
Update: I've discovered that even though it shows as queued in the Data Flow UI, it IS actually running. A temp table is being filled on the dedicated SQL pool, but it's excruciatingly slow. I'm running this on a 1000DWU Synapse pool with a large compute cluster for the data flow, and it's still only importing a few dozen rows per second. Given the fact it needs to import over 100K rows, this will take a long time. Does anyone have any idea why it is so slow?

Hi @Anonymous ,
Thank you for posting query in Microsoft Q&A Platform.
I see similar case in past (check below link), where huge data was getting processed. But in your case, you mentioned it's not huge data.
https://learn.microsoft.com/en-us/answers/questions/582066/index.html
Could you please still give a try to processing data in small chunks? Also, you mentioned that other dataflows are running well. what is the size of data there in comparison the concerned data?