Microsoft Authenticator
A Microsoft app for iOS and Android devices that enables authentication with two-factor verification, phone sign-in, and code generation.
5,533 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ERA%3C/text%3E%3C/svg%3E)
Hi,
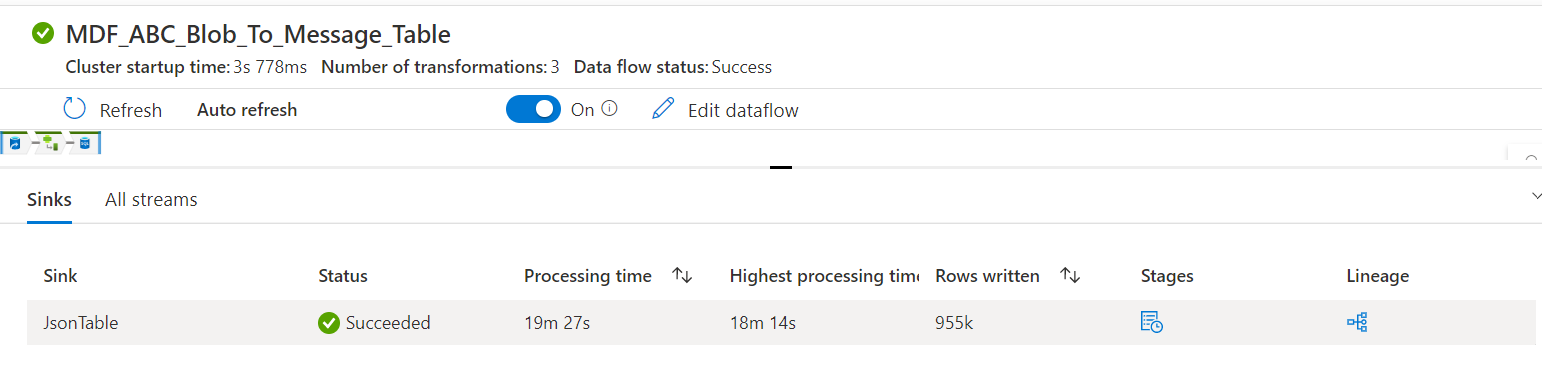
I am running a pipeline which is containing only a Dataflow. This dataflow is just reading the data from json and inserting data to azure SQL. My source JSON containing 9 to 10 lakhs files . When I ran the pipeline for the first time, It executed fast and successful. And the data is inserted in DB.
When I rerun the pipeline, pipeline run is not completing. it keeps on running for more than 40 mins. No errors are throw, and the run is not completed. When I click on the debugging, it shows the activity is queued. It is in the same state for very long time.
It is queued in at the first step(files are reading from DL storage).
Why this issue is happening? wat could be the issue?
We are unable to find the cause.
Please have a look into below points:


' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EBM%3C/text%3E%3C/svg%3E)
Hello @Rahul Ahuja ,
Welcome to the MS Q&A platform.
Are you seeing this issue with every pipeline run? I just wanted to see if this is an intermittent issue or if you are seeing the same behavior with every pipeline run.
When you are seeing the issue, Can you please check if there are any open transactions or any excessive blocking on the DB end?
and can you try processing the data in smaller batches and see if it helps?
Thank you for your response.
1) Are you seeing this issue with every pipeline run? I just wanted to see if this is an intermittent issue or if you are seeing the same behavior with every pipeline run. No, This problem only affects one pipeline from which we call DataFlow. This data flow solely inserts data from a json file into Azure DB (inserting data from a json structure into a SQL table in an NVARCHAR column).
2) When you are seeing the issue, Can you please check if there are any open transactions or any excessive blocking on the DB end? We also attempted to shut off every other pipeline than the one described above, but we encountered the same problem. Data flow has become entered in Queued. Since it is unlikely that any other operation would obstruct this process, we are just absorbing the data into the landing table.
and can you try processing the data in smaller batches and see if it helps? It is true that we can accomplish this, but if we load the data in small batches—which we must do because we get between 9 and 10 lakh files daily—our other work would be delayed. Is there a way to do this?
Hello @Rahul Ahuja ,
I have discussed the issue with my internal team. They have advised the below to resolve the issue.
1) It seems, the core count is not enough to process the data. Please increase the core count in the data flow cluster
(or)
2) Process the data in small chunks:
One way to process data in smaller chunks:
Assume you have one large data file, using a Data Factory Source
You could set Sampling ON in that source activity, and set the Rows Limit by a passed job parameter via Add dynamic Content.
You'd have to wrap your Data Factory Job in some sort of Iteration Activity (e.g. Until) in a called Pipeline. I'd probably check for the output of your Source Activity and, if the number is LESS than the value of the parameter you pass in, then break out of the Iteration Loop.
One Caveat: This may NOT do well with "No Records Returned". May have to do some edge testing for that. (e.g. you process 1000 rows at a time, and there are exactly 1000 rows in the last batch, to the NEXT batch processes zero - does the Source activity return an output value of zero? Or does it not have any results at all?)
A similar thread has been discussed here.
I hope this helps. Please let me know if you have any further questions.
Thank you for your response.
1) It seems, the core count is not enough to process the data. Please increase the core count in the data flow cluster. This point is helpful, we are planning to improve IR core.
2) Process the data in small chunks:
**We don't have any files containing a lot of data. There is only one row in a file that is in JSON format. yet there are a lot of files—about 10 lakhs—in total. I doubt sampling ON will be of much assistance to us. Correct me if I am wrong **
Hello @Rahul Ahuja ,
Thank you for the reply
Yes, I believe sampling could help. But please test these two recommendations and let us know if you still have any issues.
I am looking forward to your response.