Azure Data Factory
An Azure service for ingesting, preparing, and transforming data at scale.
11,625 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.

Hi,
I am having 11 parquet files in datalake
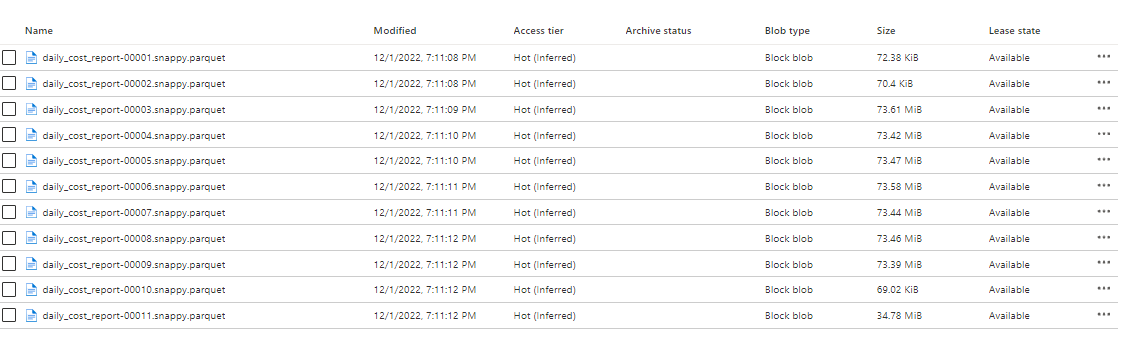
Each file is having 260 columns and approx 500k rows. I have to pull all these 11 files and then filter the number of columns down to 60 only from each file and then have to combine all these files in a single file.
I am trying to achieve this in mapping dataflows like this.
I created 11 incoming streams for each file and the used UNION to union all and then selected only 60 useful columns in the mapping section ( I used manual mapping ) and then used the SINK with output to a single file option.
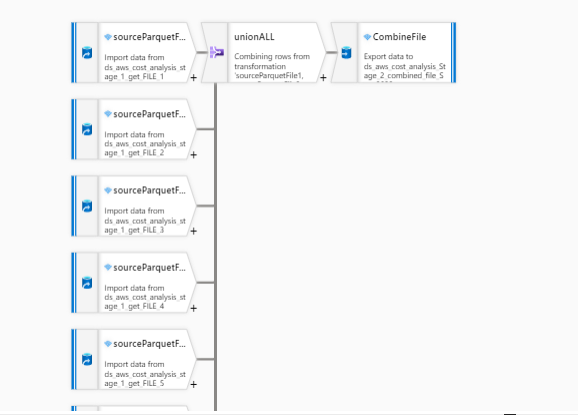
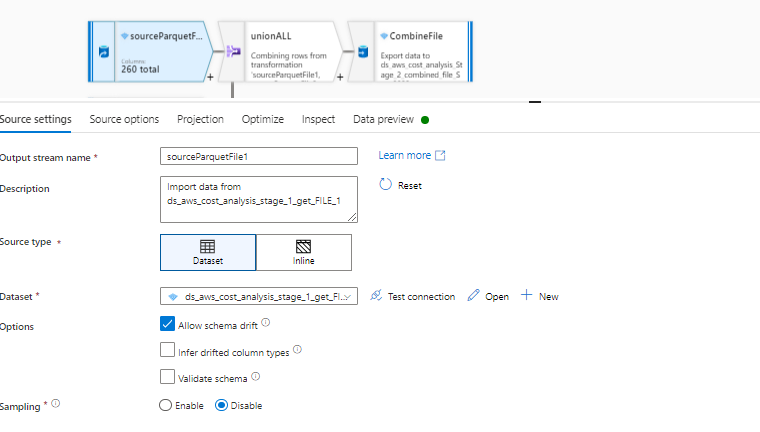
These are my settings for the incoming streams
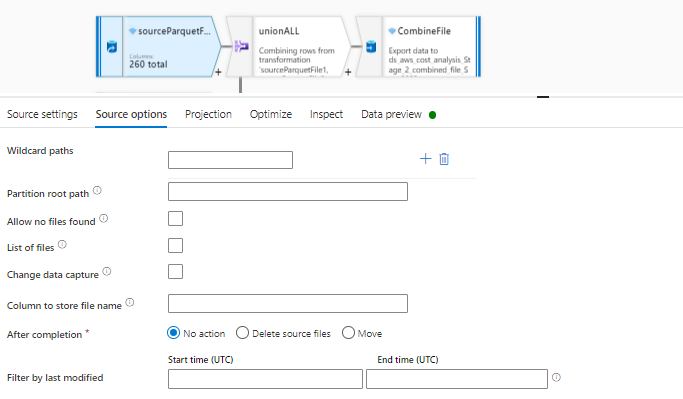
These are the settings in UNION
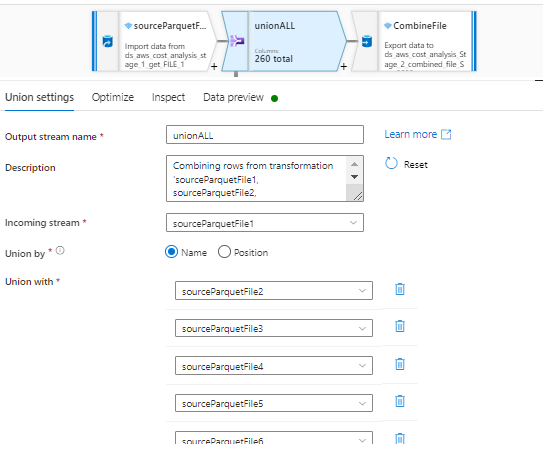
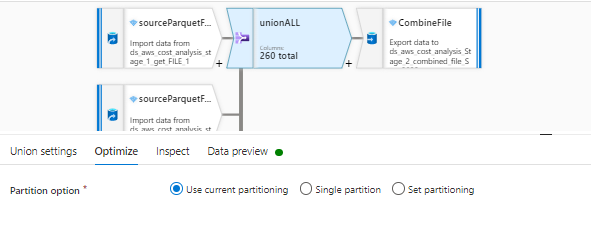
These are the settings in the SINK
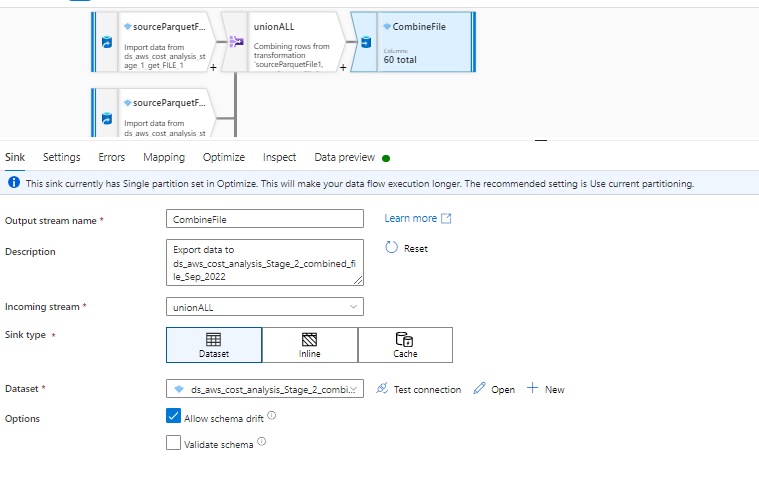
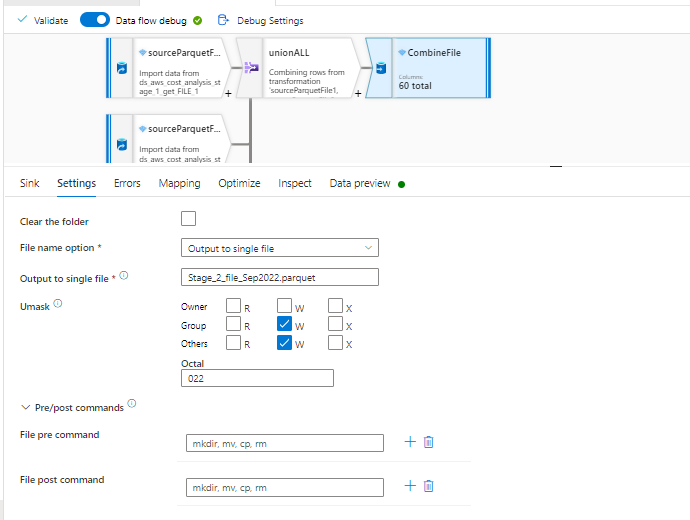
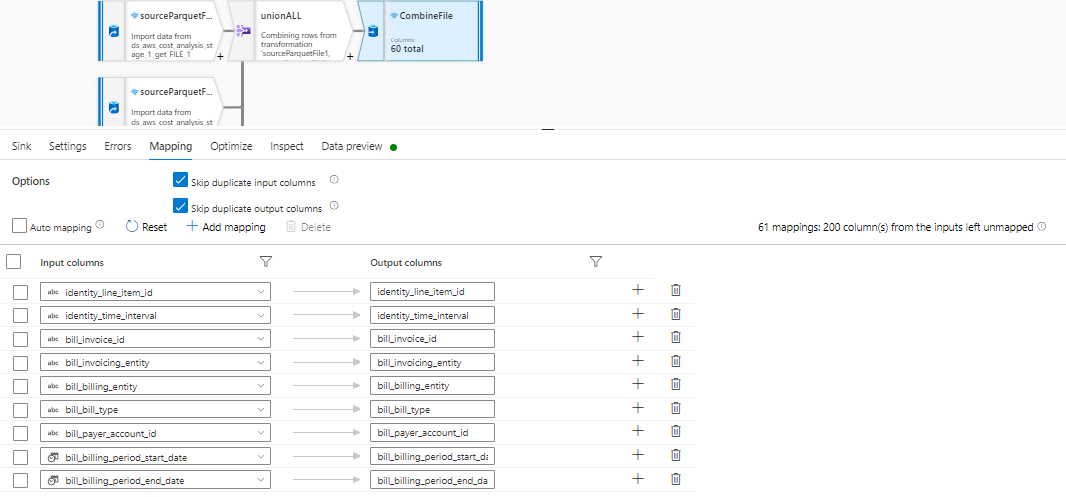
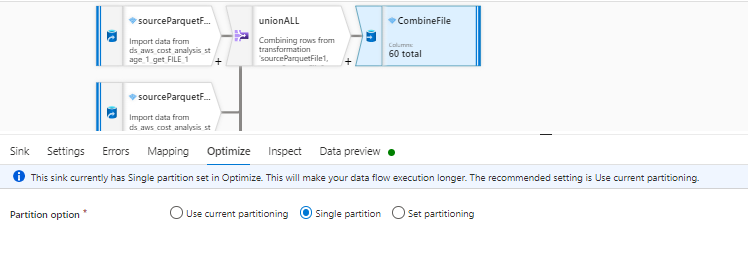
Now when i ran this dataflow it is taking infinite time even when i used 64 Cores in dataflow activity pipeline. I believe it is happening because it is first doing UNION of all the files which is resulting into a large file of 260 columns and 40M rows and then filtering columns is getting done on this gigantic file.
I want to change my logic now. I want to filter the columns down to 60 first on all the 11 files and then i want to do union on all these files having only 60 columns.
Can anyone suggest the work path to achieve this in mapping dataflows or is there any better way to achieve this in an efficient and cost effective way.
Thanks

Hi @Amar Agnihotri ,
I was wondering, if there is a reason to use 11 different Dataset as a Source?
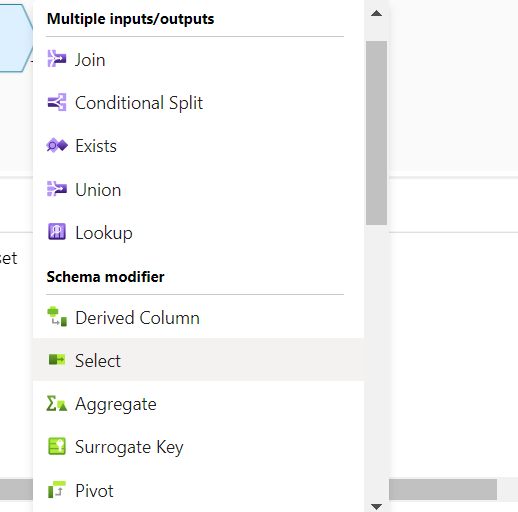
You can simply use 1 dataset for all the files and then have a DataFlow-->SELECT activity to minimize the number of columns >> then do all the other ACTIVITIES if there is any >> then SINK. Hope this helps, thanks!
hi @Nasreen Akter
Thanks for the reply. I agree that there is no sense of using 11 datasets but i want to merge all 11 files and that can be done using UNION in dataflows and for UNION i think there should have different incoming streams over which union can be performed. Now as per your suggestion i tried a single dataset as below-
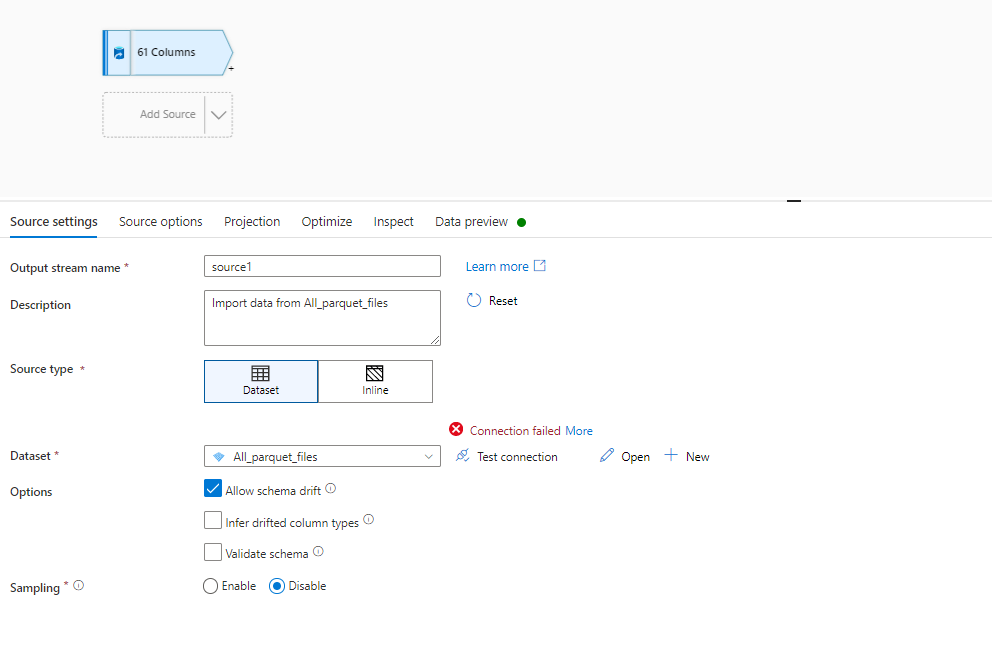
here are the dataset settings
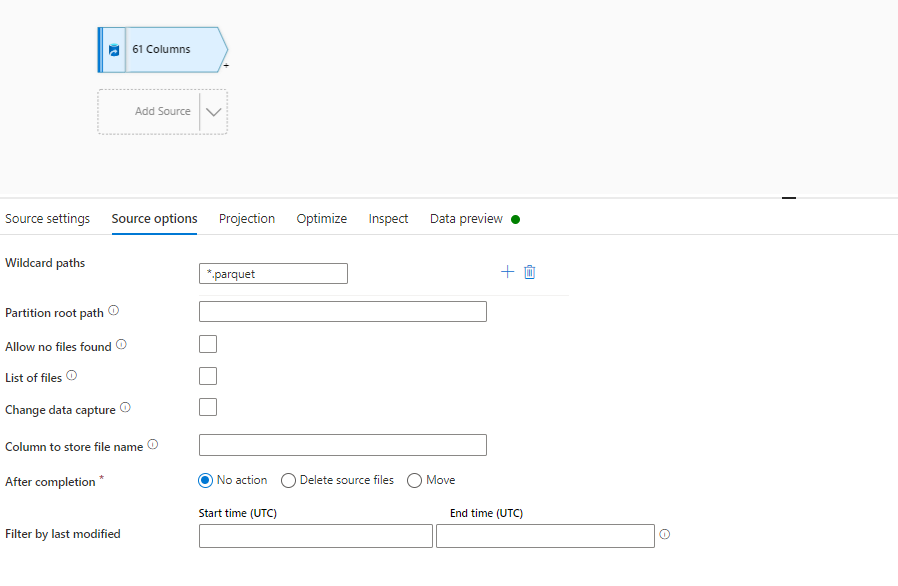
Now this dataset is referring to the datalake folder which is containing all 11 files . These files
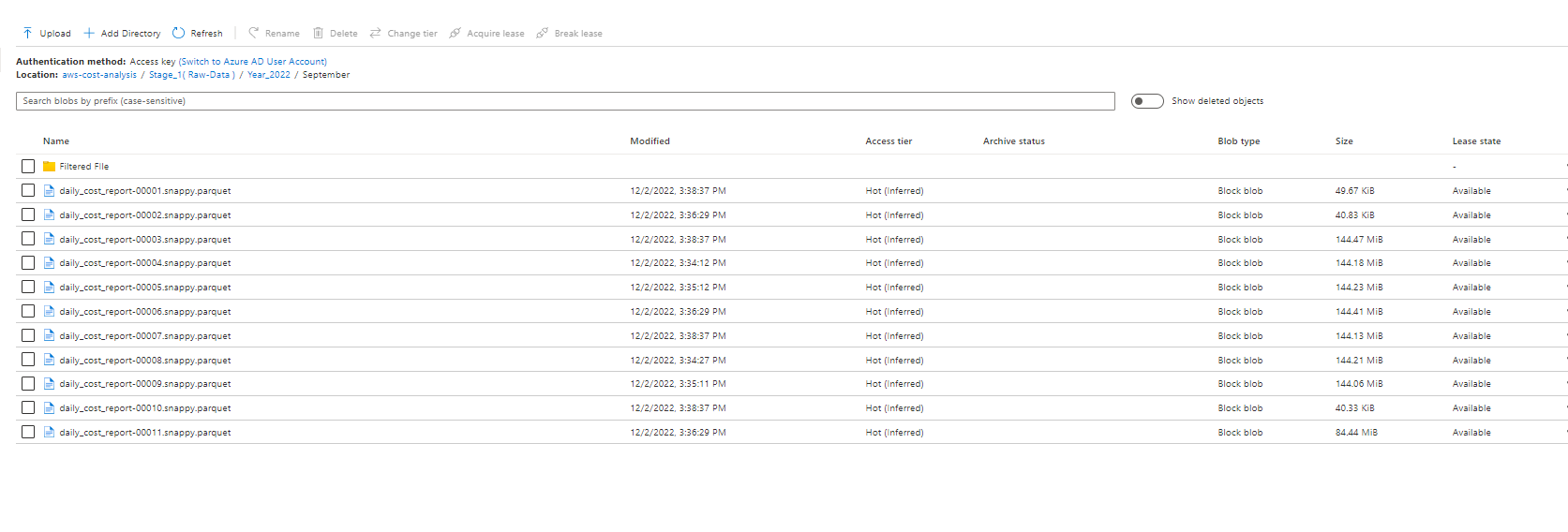
and i am using wildcard path to select only parquet file
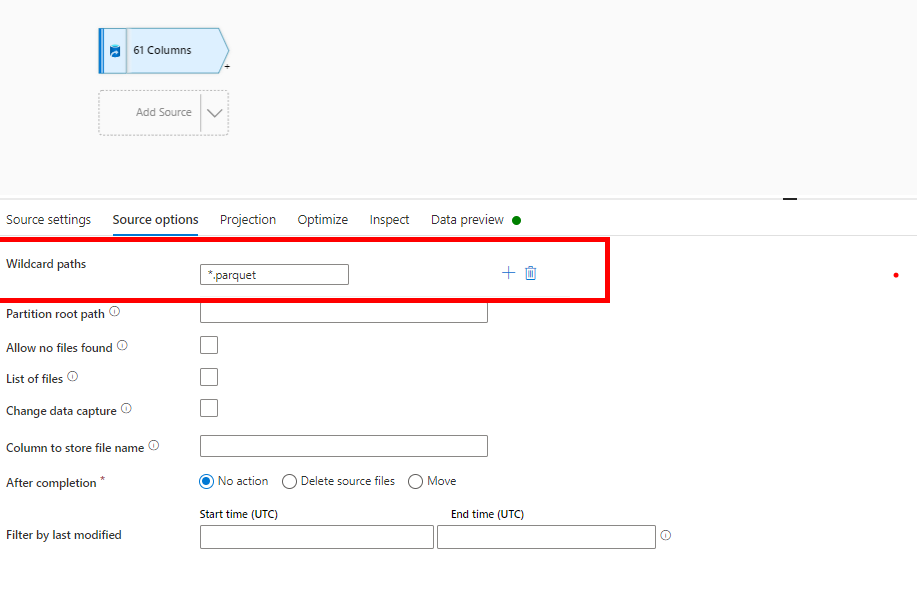
but now when i am trying to import the schema it is not getting connected to dataset
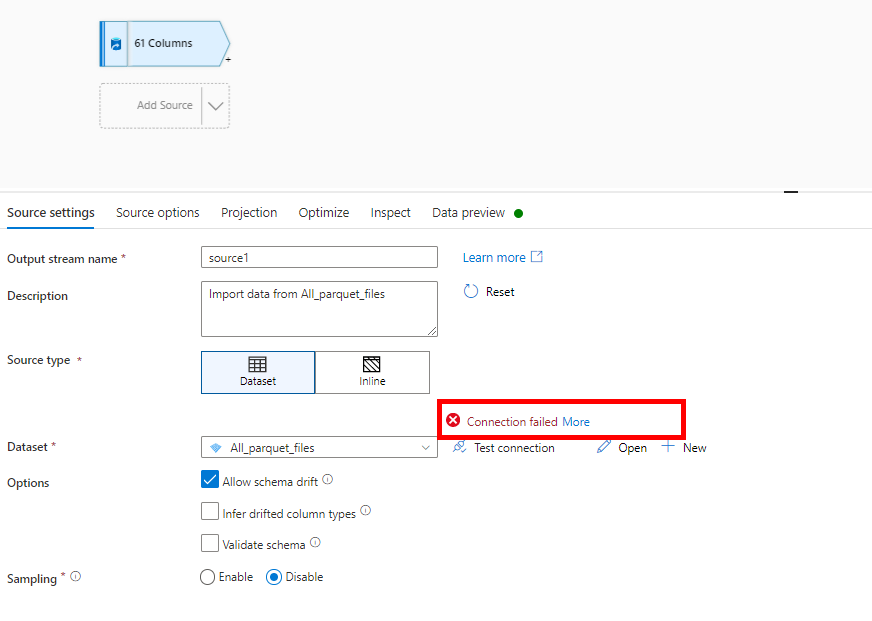
Since it is not importing schema that's why it is whing only 61 columns but the columns are actually 260 in each file . After this i can use SELECT in dataflow and can filter the number of columns but after that how to combine these files. I am confused . Can you please show some demo screenshot of the sequence of activity in dataflow ? That will help me.