Hi @John Couch
I prefer the unique filtered index. In the above code, you use a UNIQUE NONCLUSTERED INDEX, which has a separate structure from the data table, so it can be placed in different filegroups and use different I/O paths, which means that SQL Server can access the index and table in parallel, making lookups faster.
I did a simple test to compare the efficiency of the two methods.
declare @begin_date datetime;
declare @end_date datetime;
select @begin_date = getdate();
INSERT INTO [Test] VALUES (1, 'Jim Jones', 'Active', '1/1/2021');
INSERT INTO [Test] VALUES (1, 'Jim Jones', 'Inactive', '5/1/2021');
INSERT INTO [Test] VALUES (1, 'Jim Jones', 'Active', '7/21/2022');
select @end_date = getdate();
select datediff(ms,@begin_date,@end_date) as 'Elapsed time/Milliseconds';
Use a Conditional Constrain:
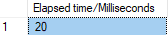
The running time is generally around 20 milliseconds.
Use a Unique Filtered Index:
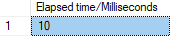
The running time is generally around 10 milliseconds.
Therefore, when the amount of data inserted is large, it is advantageous to use a Unique Filtered Index.
Best regards,
Percy Tang
----------
If the answer is the right solution, please click "Accept Answer" and kindly upvote it. If you have extra questions about this answer, please click "Comment".
Note: Please follow the steps in our Documentation to enable e-mail notifications if you want to receive the related email notification for this thread.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EJC%3C/text%3E%3C/svg%3E)

' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EA%3C/text%3E%3C/svg%3E)