Azure AI Search
An Azure search service with built-in artificial intelligence capabilities that enrich information to help identify and explore relevant content at scale.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EA%3C/text%3E%3C/svg%3E)
Hi,
I am trying to run OCR on PDF's as part of skills pipeline in Cognitive Search (Standard2, 2 Replica's, 2 Partition, 4 Search Units). 20 pdf's with 50 pages each, its taking 20 mins to process. Following is my skillset definition. I did create a cognitive services resource and associated it with skillset so that I am getting bound by free tier. Is there any way I can speed up the processing. I would like to understand the max throughput I can achieve with documents of these sizes. What are the key configuration parameters for speeding up the cognitive pipeline? I have used batch size and degreeofParallelism for custom skills but I do not have the same option for Ocr Skill.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EA%3C/text%3E%3C/svg%3E)
MantuSingh-3347, Thanks for the question!
Based on my understanding (from the sample), you are leveraging this Skill Microsoft.Skills.Vision.OcrSkill" :

It by default, uses free one. The free enrichments are 20 documents per day, per indexer.
Based on your requirement, you may add a new cognitive service. Attach Cognitive Services to a skillset - Azure Cognitive Search | Microsoft Learn
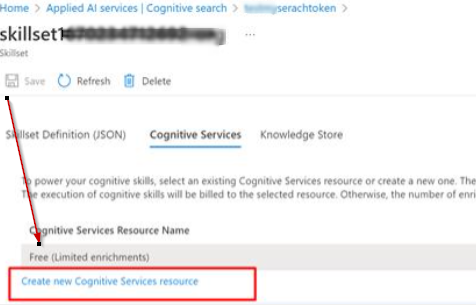
The max throughput depends on the search unit you have, see Estimate capacity for query and index workloads - Azure Cognitive Search | Microsoft Learn –. Also, check out the doc section for “Tips for capacity planning” for more info.
Kindly let us know how it goes, we will be more than happy to assist you further.
@Anonymous thanks for your response. I had the same suspicion that somehow it is getting throttled by free tier. If you see the attached skillset definition it is already associated with a cognitive services resource. From the documentation, it seems like a search unit is somehow tied to a single indexer execution. I have a single indexer running and have given it 3 search units.
MantuSingh-3347, Thanks for the follow-up and update. I'm following-up on this privately to fetch additional info.
I'll leave this open for other community members to share their insights/similar experience.