Azure Data Factory
An Azure service for ingesting, preparing, and transforming data at scale.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ESP%3C/text%3E%3C/svg%3E)
Hi there
I'm using Azure Data Factory Data Flow. I have a column that contains around 5000 ids.
I'm looking to merge this into 100 separate rows, each with an array of 50 ids.
I was wondering if you could advise the method of doing this, I can use collect() to merge everything into a single row, however I'm looking for 100 separate rows.
Thanks very much
Steven
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EKM%3C/text%3E%3C/svg%3E)
You can use Flatten (foldDown) transformation
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMM%3C/text%3E%3C/svg%3E)
Hello @Steven Pretswell and welcome to Microsoft Q&A.
I see Kiran has offered a suggestion, but could you please clarify the ask? In the title you say "Split array into chunks" , but in the body you say "I'm looking to merge this into 100 separate rows..."
Is it the case that you have a table with 5000 rows, one ID in each row, and you want to group the id's together so the result is a table woth 100 rows, and a column containing an array of 50 id's each
Or
Is it the case that you have a table, and in each row there is cell containing an array of 5000 ids, and you want to duplicate the row except for the cell with the array. That cell gets its contents split among the new rows so it is smaller array size
Or is it something else? A picture of the starting state, and a picture of the desired resulting state would be most useful in that case.
Thank you for your patience.
Hi there
Thanks very much for getting back to me.
Its the first case, I have a table with 1 column(id), 5000 rows, each with a single guid.
I'd like to group them together so the end result is a table with 1 column(idarray) and 100 rows, each row containing an array of 50 ids.
Current
id
a
b
c
d
e
f
Desired
idarray
[a,b,c]
[d,e,f]
Hope this provides more clarity
Thanks very much
Steven
Thank you for the response. That made it perfectly clear. Solution coming soon.
@Steven Pretswell has your question been answered, or do you still need assistance?
Partitioning should be used only in the case of optimization not to do data integration logic.
A optimal solution would be -
Thank you for the feedback @Kiran-MSFT . Your solution sounds better than mine, so I took the liberty of converting it to an answer.
@Steven Pretswell could you please mark the relevant solution as answered, or let us know if you need more help.
@Steven Pretswell I have reproduced and found a solution.
First I created a csv file with the numbers 1...40, each number on its own line. This I use as source data. I will split these 40 numbers into 4 sets of 10.
What you described is somewhat like partitioning. In the Data Flow source, I set the partitioning to round-robin, so the partitions would be evenly sized. The contents of each are not sequential. While my source data is the range of numbers 1...40, contiguous (no holes) and ordered, I have no idea what your id's are like. This is why I chose round-robin.
Step 1

Next, to make the partitions visible, and easier to work with, I added a derived column whose contents are partitionId(column_1).
Step 2 (optional)

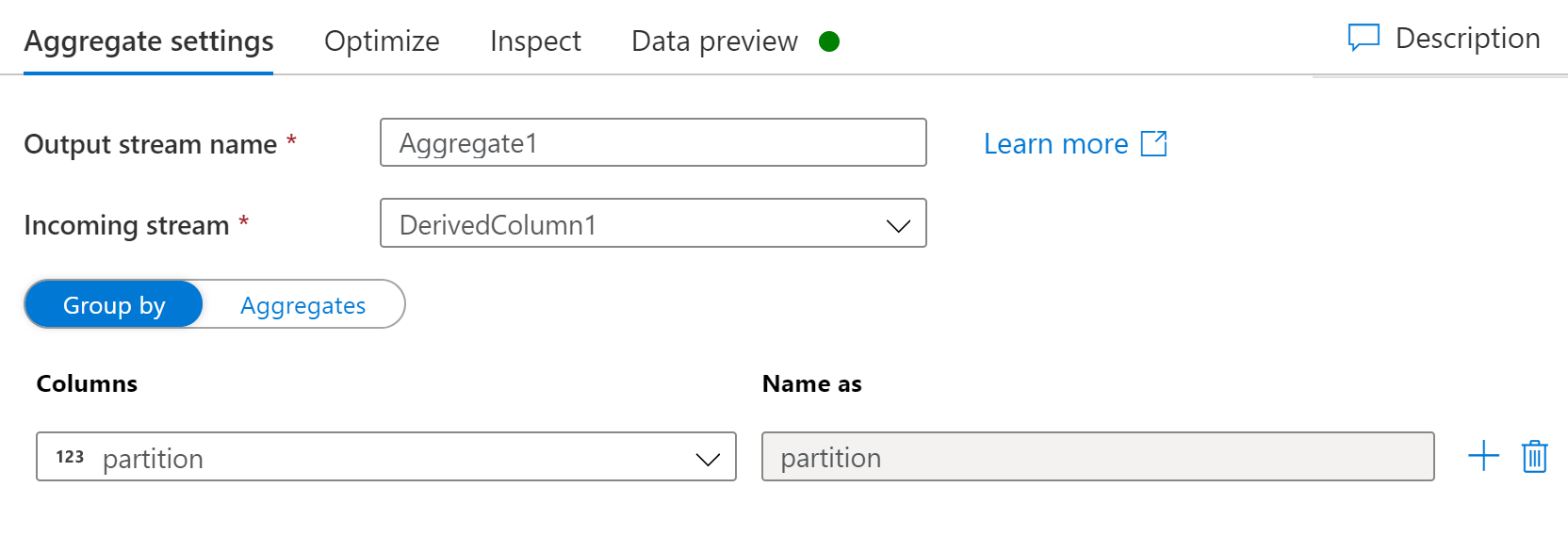
Now I want to group the rows by the partition and do collect like you suggested, but only on the contents of the group, keeping the groups separate. This is accomplished by an aggregation transformation.
Step 3 (important)
Group by: column partition, name as partition
Aggregate: column_1, collect(column_1)
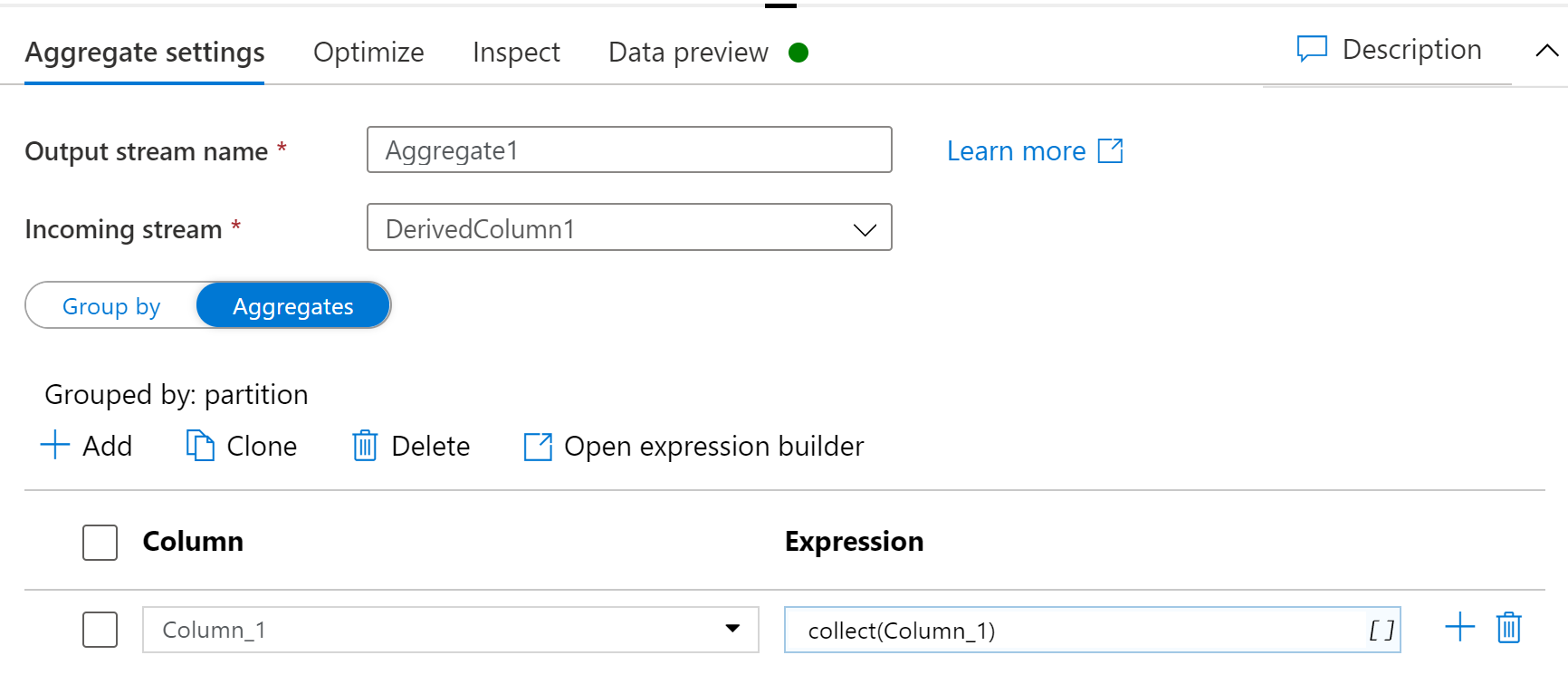
Now I preview the output of the aggregation, I see 4 rows, each a different partitionId. There is also an array in each. Peeking into the array I see 10 entries.
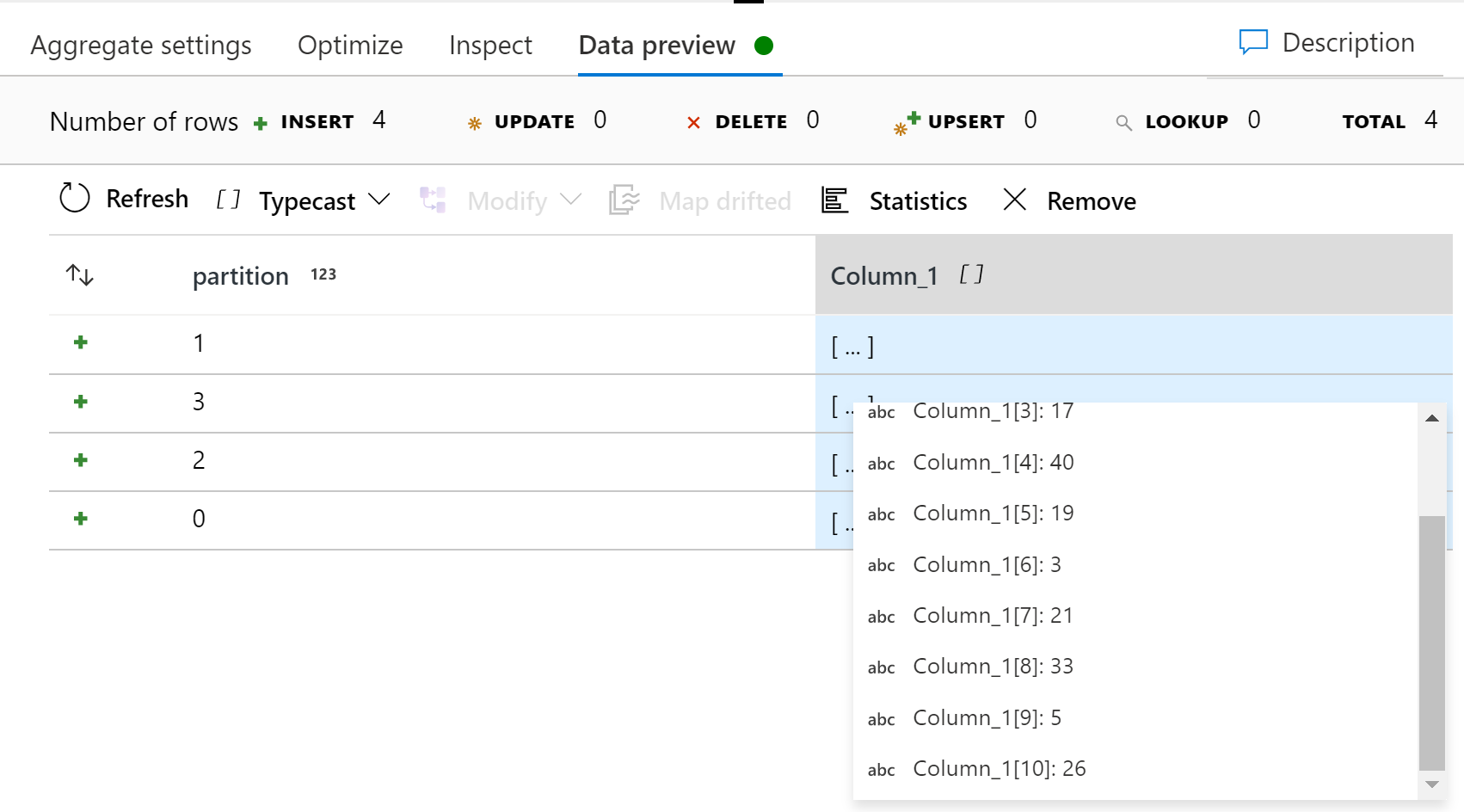
This is similar to the state you wish to achieve. Now to clean up, either use a select to discard the partition id, or just exclude it in the sink. Also, now that I know this works, I could clean up some more. Since partitionId was generated by a function, I can removed the derived column, and in the aggregate group by clause, use partitionId() instead of a column.