Hi @maca128-1653,
Why he says "With SQL Server–level HA technologies, write operations occur on the primary database and then again on all secondary databases, before the commit >on the primary completes" if in the exact previous line he says "written to disk once".
"written to disk once" is for clustering.
"With SQL Server–level HA technologies, write operations occur on the primary database and then again on all secondary databases, before the commit on the primary completes"
Actually,the availability mode determines whether the primary replica waits to commit transactions on a database until a given secondary replica has written the transaction log records to disk (hardened the log).
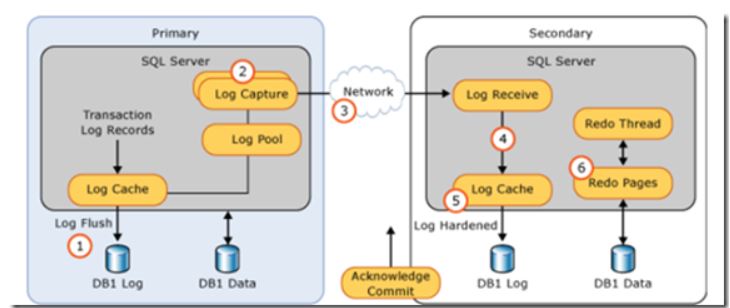
To understanding this sentence, we need to understanding how sql server achieve HA, the next is one AG working steps:
① The logwiter of the primary replica records the log information modified by the transaction into a log buffer in the memory, and then writes it to the physical log file (log solidification);
② The logscanner of the primary replica reads the log block from the cache or log file, and then sends it to the log block decoder of AlwaysON;
Note: The decoder will search the logs for operations that require special processing, such as file stream operations, file growth, etc.
③ The primary replica transmits the log block to the secondary replica via the network;
④ and ⑤
After the secondary replica receives the log block, logwiter records the log information modified by the transaction into a log buffer in memory, and then writes it to the physical log file (log solidification). In addition, if the secondary replica is in synchronization available mode, after the log is solidified, it must also feed back information to the primary replica. The primary replica can submit the transaction after receiving the message that the secondary replica has completed solidification. If the secondary replica is in asynchronous available mode or the primary replica is in asynchronous mode, the primary replica submits the transaction and Whether it has nothing to do with whether the secondary replica has completed log curing;
⑤ Redo thread reinterprets the transactions recorded in the log on the secondary replica. The redo thread will communicate with the primary replica at regular intervals to inform it of its own work progress. The primary replica can know how far the data gap between the two sides is.
For the sentence : ""With SQL Server–level HA technologies, write operations occur on the primary database and then again on all secondary databases, before the commit on the primary completes"" , it may means the first three steps of its working.
Then, why he says "Even though it is possible to stretch a cluster across multiple sites, this involves SAN replication, which means that a cluster is normally configured >within a single site."
"Even though it is possible to strech a cluster across multiple sites..."-"multiple sites" in this sentence means physical site,they are geographically dispersed.
"...this involves SAN replication, which means that a cluster is normally configured within a single site"
A multi-subnet cluster does not share data storage among all nodes, so it is necessary to perform hardware storage-level data replication between multiple subnets, so that multiple copies of available data are obtained.
So the single site means they are need data replications, and it is one logical concept.
If a cluster is scretched across multiple sites and this inolves SAN replication, then.... Is this still clustering?! I thought the point of clustering was having only one disk....
Yes.It is.
It is one cluster or not, not determined by how many disks they use, it determined by whether they can ahcieve the function of cluter, wheter it is suitable for the definition.
Quote from this doc.: sql-server-failover-clustering
SQL Server failover clusters are made of group of servers that run cluster enabled applications in a special way to minimize downtime. A failover is a process that happens if one node crashes, or becomes unavailable and the other one takes over and restarts the application automatically without human intervention
Quote from this doc.: sql-server-multi-subnet-clustering-sql-server
A SQL Server multi-subnet failover cluster is a configuration where each failover cluster node is connected to a different subnet or different set of subnets. These subnets can be in the same location or in geographically dispersed sites. Clustering across geographically dispersed sites is sometimes referred to as stretch clusters. As there is no shared storage that all the nodes can access, data should be replicated between the data storage on the multiple subnets. With data replication, there is more than one copy of the data available. Therefore, a multi-subnet failover cluster provides a disaster recovery solution in addition to high availability.
If a cluster is scretched across multiple sites and this inolves SAN replication, how come this means that a cluster is configured within a single site?!?! it sound like a contradiction... I guess that if the cluster is stretched across multiple sites then cluster is configured across multiple sites, by definition....
The single site comes from the author's understanding, I guess it is just one logical concept.
BR,
Mia
If the answer is helpful, please click "Accept Answer" and upvote it.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EO%3C/text%3E%3C/svg%3E)




