Hi,
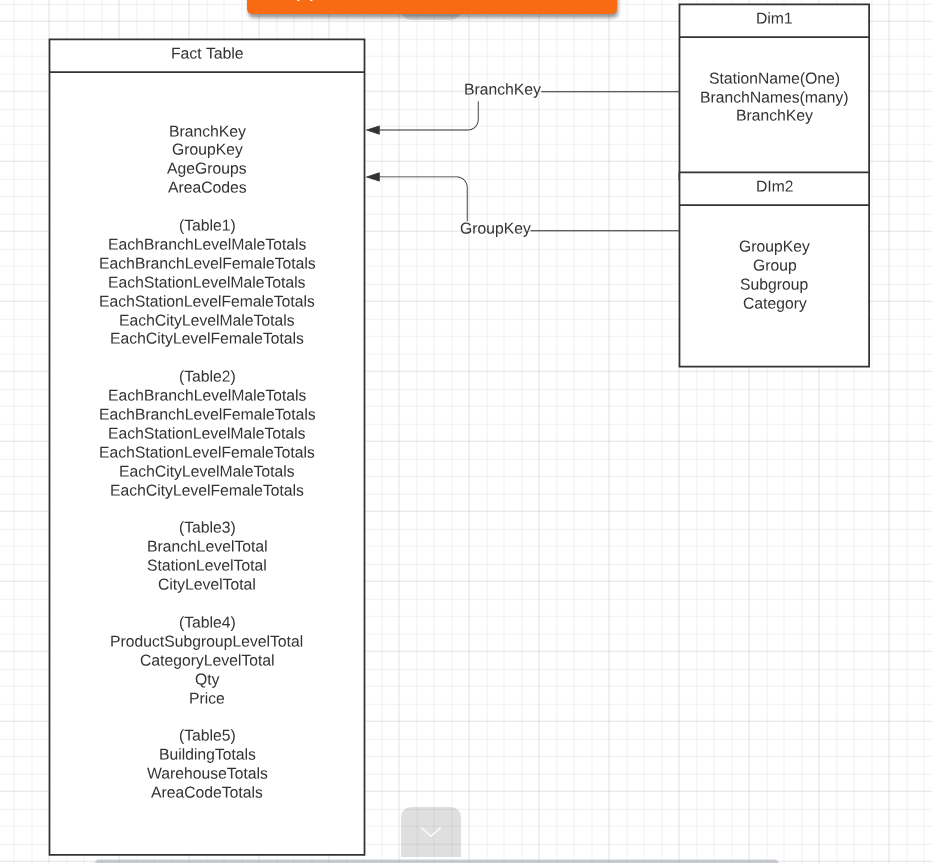
I need some advise on designing a fact table (pic 2). I have 5 tables as below (pic 1). Each table has first two common columns (BranchNames being unique) which I think would go under a dimension table. Table 2 & 5 has one column (middle ones) (It has unique values) could be used as a degenerate dimension (Dont want to create a dimension again to just generate a key for one column) so those will be gothe fact table) and finally, table 3 & 4 has product detail columns(middle ones again) which will come under a different dimension.
The problem I am facing is the records are getting duplicated at the very last three fields in the fact table (coming from table 5) as there is one entry in every column of the three for each unique areacode. So overall the table is becoming a very large one with millions of records. Multipied for each entry.
Note : I want to design the fact table at branch level so I have used the branch key.
Could someone suggest a better design to avoid the issues mentioned above , please?
Thank you in advance!

' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EJZ%3C/text%3E%3C/svg%3E)
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EAS%3C/text%3E%3C/svg%3E)