Azure Blob Storage
An Azure service that stores unstructured data in the cloud as blobs.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EVG%3C/text%3E%3C/svg%3E)
I have .txt files pushed by Microsoft Academic Graph to Azure Blob storage.
And I'm building a python app that uses "azure-storage-blob" SDK for querying the .txt files to search certain entries by column values. For this, I'm using the following documentation:
https://learn.microsoft.com/en-us/azure/storage/blobs/data-lake-storage-query-acceleration-how-to?tabs=python%2Cpowershell
I tested it for .csv files - and it works just fine: the columns are searchable by using the "query_blob" method of the "BlobClient" class. The files have columns in each row that are separated by comma sign ','
But when I'm trying to use it for those .txt files that have columns separated by the '\t' sign. Then in response to the query, I'm getting each row as a single column.
For example, if the file contains a row like:
95198407 14607 helpage international HelpAge International
Then, I expect to get all for columns searchable and get in response an object with four columns as it working for similar .csv files.
But instead of that, I'm getting a single row in response as a single column.
The live example of what I have in code:
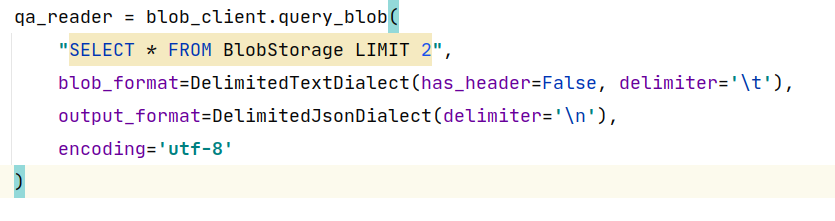
And what I have in response:

I made multiple tests with parameter "delimiter" queal to:
'\t'
'\t'
'/\t'
'\t\t\t\t'
And similar to those. But all time the result is either the same or some time it throws an error like:

Then I tried to set parameter "delimiter" to '\t\t\t\tt' and got the following response:

So, it looks like it does not matter how many '\t' signs I'm specifying for the "delimiter" parameter, they all are filtering out and the columns are treated as 't' characters separated in this case.
And it looks like I either can not figure out how to escape the '\t' sign properly and that is why it is filtering out and ignoring, or there is some another way to specify the 'tab separator". I checked the docs for the BlobClient class here:
https://learn.microsoft.com/en-us/python/api/azure-storage-blob/azure.storage.blob.blobclient?view=azure-python
And even looked inside the source code, but can't figure out how to solve the issue.
An Azure service that stores unstructured data in the cloud as blobs.

@Volochy Grigory since the request body doesn’t have column separator when we set as ‘\t’. I will investigate and get back to you!
Thank you! I'm looking forward to your reply.
If you need any additional information about the way I'm getting the issue or something is not clear in my description, then please let me know, I will provide it as soon as possible.
@Sumarigo-MSFT From what I understood, the problem is with the way the parameter is passed in XML format. And this error that says "The specified XML is not syntactically valid" when I try to escape the "\ t" sign as "\ t".
I tried various ways to avoid this but to no avail.
I hope you can clarify how to fix this problem.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ETC%3C/text%3E%3C/svg%3E)
@Sumarigo-MSFT I also keen to have an answer to this issue - looking forward to your reply.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EA%3C/text%3E%3C/svg%3E)
@Volochy Grigory Just letting you know that we are still working on this internally. Sumarigo or I will provide an update once we have more information available.
I understand this issue is not simple to fix.
Thank you so much for the update. It is important for me to know that the issue is supposed to be solved.